Cursor Composer 2.5深度实测:200 Token/秒的氛围编程到底好不好用
Cursor发布Composer 2.5,以超快速度和强劲编码能力引爆开发者社区
Cursor发布的Composer 2.5在多项基准测试中与Claude Opus 4.7和GPT 5.5处于同一梯队,且成本更低。其最大亮点是200+ Token/秒的生成速度,极大提升了开发迭代效率。实战测试中,它能快速修复简单Bug,对于复杂Bug则可借助调试模式通过系统化假设验证来定位根因。
概述:Composer 2.5为何引爆开发者社区
Cursor 本周一发布了 Composer 2.5,这款模型在 X(Twitter)上的讨论热度远超预期。从基准测试数据来看,Composer 2.5 相比前代有了质的飞跃,直接与 Claude Opus 4.7 处于同一档次。
在 SweepBench 多语言测试中,它与 Opus 4.7 和 GPT 5.5 属于同一梯队。SWE-bench(Software Engineering Benchmark)是由普林斯顿大学研究团队于2023年推出的标准化评测框架,专门用于衡量AI模型解决真实软件工程问题的能力——它从GitHub真实Issue中抽取任务,要求模型在不提示解决方案的情况下自主修复代码缺陷。其多语言扩展版本覆盖Python、JavaScript、TypeScript、Java等主流语言,更贴近实际开发场景。
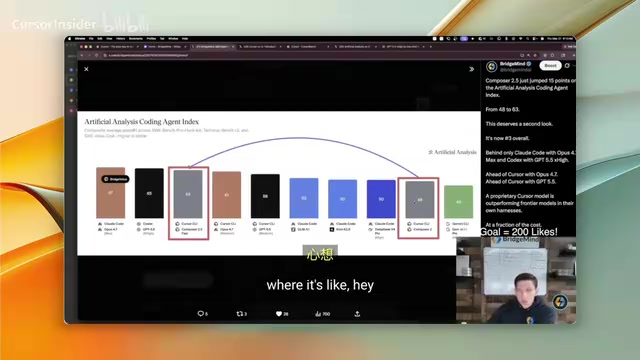
更值得关注的是 Cursor 自家的 Cursor Bench 测试结果——Composer 2.5 的成绩超过了 GPT 5.5 和 Opus 4.7,而且平均每个任务只需 55 美分,远低于竞品成本。虽然有人质疑自家基准测试可能存在偏见,但第三方 Artificial Analysis(一家独立的AI性能评测机构,其编码智能体指数通过在真实代码库中执行端到端任务来评分,被业界视为相对客观的第三方参考)的编码智能体指数也给出了印证:Composer 2 在 Cursor Client 中得分 48,而 Composer 2.5 拿到了 63 分,评价为"快而强,比肩 GPT 5.5"。
速度体验:200 Token/秒带来的开发节奏变化
Composer 2.5 最突出的卖点就是速度——Token 生成速度达到每秒 200 个甚至更高。
Token 是大语言模型处理文本的基本单位,大致对应0.75个英文单词或约1.5个中文字符。Token/秒(TPS)是衡量模型推理速度的核心指标,直接影响用户的交互体验。主流商业模型如GPT-4o的输出速度通常在50-100 TPS区间,而Composer 2.5声称达到200 TPS以上,这背后依赖的是推测性解码(Speculative Decoding)、KV Cache优化以及专用推理硬件(如H100/H200 GPU集群)的协同加速。高TPS对于代码生成场景尤为关键——开发者的思维流不会因等待而中断,从而维持"心流"状态。
实际测试中,一个简单的 TypeScript 文件修改(更新 YouTube 订阅人数),从分析到完成只需 5-10 秒。这种响应速度让快速迭代真正成为可能,也与氛围编程(Vibe Coding)的工作范式高度契合。
氛围编程这一概念由OpenAI联合创始人Andrej Karpathy于2025年初提出,描述的是一种以自然语言意图驱动、AI负责具体实现的新型编程范式——开发者不再逐行编写代码,而是通过描述功能需求、提供截图或示例,让AI模型完成代码生成与迭代,自己则专注于方向把控和结果验证。
不过速度快也是一把双刃剑。正如测试者所说:"如果我有 10 个用 Opus 4.7 的任务在后台跑,我就有空去管理这些任务。有时候模型跑得太快未必是好事。"高速度也意味着错误会更快累积,需要开发者保持更高的审查频率。但确实,对于需要频繁调试和迭代的氛围编程场景,这种响应速度确实带来了全新的工作节奏。
实战测试一:Bug修复能力如何
设计工具输入框无法点击
测试场景是 BridgeSpace 浏览器中的一个真实 Bug:设计工具的输入框无法点击进入。测试者用 CleanShot X 截图标注问题区域,然后将截图和描述一起提交给 Composer 2.5。
模型快速定位了问题——WebView 浏览器注入的 Inspector 脚本影响了设计模式,导致点击事件被错误捕获。
WebView 是一种将Web渲染引擎嵌入原生应用的技术组件,在Electron、Tauri等跨平台桌面框架中被广泛使用。开发者常通过向WebView注入JavaScript脚本来实现调试工具(如Inspector)、功能增强或数据采集。然而这种注入机制会在宿主页面的事件系统中引入额外的监听层,当注入脚本拦截了鼠标点击、键盘输入等DOM事件时,就可能导致原生UI组件失去响应——这正是输入框无法点击的根本原因。修复一次完成,Bug 当场解决。
代理启动失败的复杂Bug
第二个更棘手的 Bug 是:在 BridgeSpace 中向 Cloud Code 等编码助手发送提示词后,代理无法正常启动。这个问题 Composer 2.5 第一次没有修好,Opus 4.7 同样也没搞定。
这时测试者启用了 Cursor 的调试模式(Debug Mode)——这是一个被很多人忽视但极其实用的功能。调试模式本质上是一种基于 ReAct(Reasoning + Acting)框架的智能体工作流。ReAct是由谷歌和普林斯顿研究者提出的LLM推理范式,让模型在执行动作前先进行显式的思维链推理,形成"思考→行动→观察→再思考"的循环。具体而言,调试模式会:
- 自动配置排查 Bug 所需的监控探针(Instrumentation)
- 列出导致 Bug 的多个假设(Hypothesis Generation)
- 逐一测试假设并记录结果
- 基于日志确认根因
这种系统化的调试方法论与人类高级工程师的排查思路高度一致,相比直接让模型"猜测并修复
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。