大模型Agent开发学习路径:从零到接单的三步实战指南

系统化三步路径,三个月掌握AI Agent开发能力
文章指出AI Agent开发正处于供需严重失衡的市场窗口,薪资和项目报价极具吸引力。作者提出三步系统化学习路径:第一步打好基础,掌握提示词工程、Transformer原理和API调用;第二步学习核心工具链,包括RAG、向量数据库和知识图谱;第三步实战构建Agent,掌握ReAct推理-行动范式。每天两小时,三个月可建立完整开发能力。
为什么Agent开发是当下最值得投入的技术方向
打开任何一个招聘平台搜索"AI Agent",你会发现一个令人振奋的现实:相关岗位薪资直接从18K拉到45K,兼职接单一个智能体项目报价五位数起步。更关键的是,会做Agent的人远远不够用——这是一个典型的供需严重失衡的市场窗口。
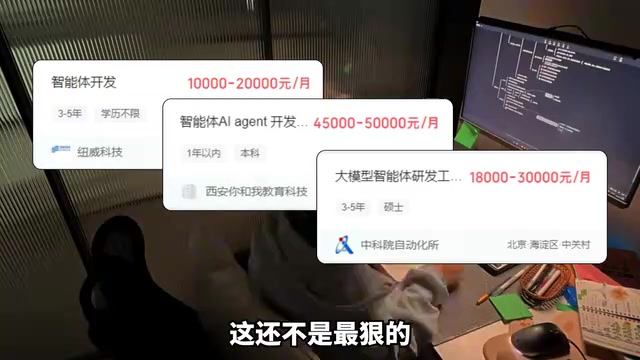
但很多人面对大模型开发时,要么被铺天盖地的概念吓退,要么陷入"收藏即学会"的自我欺骗。实际上,如果方法得当,每天投入两个小时,三个月时间足以建立起完整的Agent开发能力。

当然,这需要满足几个基本前提:有稳定的学习时间、有执行力去动手实践,以及愿意按照系统化的路径循序渐进,而不是东一榔头西一棒槌。
第一步:打好基础——API调通比模型训练更重要
很多初学者犯的第一个错误,就是一上来就想搞模型训练、微调。这就像还没学会开车就想改装发动机,完全搞反了优先级。
对于Agent开发者来说,第一步要做的是三件事:
-
提示词工程(Prompt Engineering):这是与大模型交互的核心技能。提示词工程是一门研究如何设计和优化输入文本以引导大语言模型产生期望输出的系统性方法——大语言模型本质上是基于概率的文本续写系统,精心设计的提示词能够激活模型在预训练阶段习得的特定知识和推理模式。系统提示词定义Agent的角色边界和行为规范;Few-shot示例通过在提示词中嵌入少量输入输出样本,帮助模型理解任务格式;思维链(Chain-of-Thought,CoT)技术则通过引导模型逐步展示推理过程,显著提升复杂推理任务的准确率。提示词写得好不好,直接决定了你构建的Agent质量上限,这些技巧都需要反复练习才能掌握。
-
Transformer原理的基本理解:不需要推导每一个数学公式,但要搞清楚注意力机制的核心思想、Token化过程、上下文窗口的概念。这些基础认知会帮助你在后续开发中做出正确的技术判断。理解上下文窗口的长度限制,是你在设计RAG系统和多轮对话时避免踩坑的关键前提。
-
API调用能力:能够熟练调用OpenAI、Claude、国内各大模型的API,理解请求参数、流式输出(Streaming)、Token计费等实际问题。流式输出通过Server-Sent Events协议逐Token返回结果,能显著改善用户体验;Token计费则直接影响你的项目成本核算。这是Agent开发的日常基本功。

这一步的核心原则是够用就行,不用精通。很多人在基础阶段花了太多时间追求完美理解,结果迟迟无法进入实战环节。记住,理论理解会在实践中不断加深。
第二步:掌握核心工具链——从RAG到知识图谱
基础打好之后,第二步是学习Agent开发的核心技术栈。这个阶段是真正拉开差距的关键。
RAG(检索增强生成)
RAG(Retrieval-Augmented Generation)由Meta AI在2020年提出,是解决大语言模型两大核心缺陷——知识幻觉和训练数据过时——的主流工程方案。其工作原理是:在模型生成回答之前,先从外部知识库中检索与问题相关的文档片段,再将这些片段作为上下文注入提示词,让模型基于真实、最新的信息进行回答。
要真正掌握RAG,你需要打通以下几个环节:数据如何清洗和预处理、文档如何切片(Chunking策略的选择直接影响检索效果——切片过大会引入噪声,切片过小则可能丢失语义完整性,通常需要根据文档类型和查询模式动态调整)、Embedding模型如何选型、向量数据库(如Milvus、Pinecone、ChromaDB)如何搭建和查询。把这条链路跑通,你就能为大模型接入私有知识库,解决"幻觉"和"知识过时"两大痛点。
向量数据库实操
向量数据库是专门为高维向量的存储和相似性检索而设计的数据库系统,也是RAG系统的核心基础设施。与传统关系型数据库的精确匹配不同,向量数据库通过近似最近邻(ANN)算法实现语义层面的模糊匹配——Embedding模型将文本转化为数百至数千维的浮点数向量,语义相近的文本在向量空间中距离更近。
不仅要会用,还要理解不同检索策略各自的适用场景:语义检索(稠密向量)擅长捕捉语义相关性,关键词检索(稀疏向量)擅长精确匹配专有名词,而混合检索策略将两者结合,能在不同查询场景下取得更稳定的效果。此外,Rerank模型在初步检索后对候选结果进行精排,能进一步提升最终召回的准确率。实际项目中,检索准确率往往比模型能力更能决定最终效果。
Agent架构与知识图谱
当你把RAG、向量数据库、API调用这些技能串联起来,再引入Agent的架构设计和知识图谱的思路,你会发现思路一下子就打开了——突然觉得什么都做得出来。这不是错觉,而是技术栈达到临界点后的自然突破。
知识图谱(Knowledge Graph)是一种以图结构存储实体及其关系的知识表示体系,由谷歌于2012年提出并用于增强搜索引擎的语义理解能力。它与向量数据库形成互补:向量数据库擅长处理非结构化文本的语义检索,而知识图谱则能精确表达"A是B的子公司""C在D之前发生"等结构化关系,让AI不仅能检索文本,还能理解实体之间的逻辑关联。近年兴起的GraphRAG方向将图结构检索与生成式AI结合,在需要多跳推理的复杂问答场景中表现出显著优势。在复杂业务场景中,比如金融风控、医疗问诊、法律咨询,这种结构化推理能力尤为重要。
第三步:真刀真枪——构建你的第一个Agent
前两步是积累,第三步才是真正的价值兑现。

掌握ReAct模式
ReAct(Reasoning and Acting)框架由谷歌研究团队于2022年在论文《ReAct: Synergizing Reasoning and Acting in Language Models》中正式提出,是Agent开发的核心范式。它让AI能够交替进行推理和行动,形成"思考(Thought)→行动(Action)→观察(Observation)"三个步骤的闭环循环:先思考当前应该做什么,然后调用相应的工具执行,再根据执行结果继续推理下一步。
与纯推理模式相比,ReAct让模型能够根据工具返回的真实结果动态调整后续策略,而非依赖静态的预设逻辑——这正是它成为LangChain等主流框架底层设计基础的原因。理解并实现ReAct模式,是从"调API"到"做Agent
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。