大模型命名规则解析:参数量、量化格式与显存需求速查
系统拆解大模型命名规则与显存估算方法,助你选对模型。
本文系统解析了HuggingFace上大模型名称中各字段的含义(模型系列、参数量、微调类型、量化策略等),并提供了实用的显存估算方法:FP16下参数量×2,4-bit量化下参数量÷1.5~1.75。文章特别强调上下文长度的KV Cache是最易被忽视的显存杀手,同时指出MOE模型必须按总参数量估算显存。最后对比了GGUF、AWQ、IMatrix、NVFP4等量化策略,给出了按显存档位选模型的实用建议。
面对 HuggingFace 上动辄几十个字符的大模型名称,很多人一头雾水:32B 是什么意思?AWQ 和 GGUF 有什么区别?我的显卡到底能不能跑?本文将系统拆解大模型命名规则,并提供一套实用的显存估算方法,帮你在下载前就判断自己的硬件是否够用。
大模型名称拆解:每个字段都在说什么
以 Qwen3-32B-Instruct-AWQ 为例,我们逐段拆解:
- Qwen3:模型系列与代数,即阿里巴巴通义千问第三代
- 32B:参数量,B = Billion(十亿),32B 即 320 亿参数
- Instruct:指令微调版本,表示模型针对对话场景做了优化
- AWQ:量化策略,决定了模型的精度与体积
再看一个更复杂的社区模型名称:DavidYu-Qwen3.6-40B-Cloud4.6Opus-Deckard-Uncensored-Thinking-NearCode-IMatrix-Max-GGUF,每个字段的含义如下:
| 字段 | 含义 |
|---|---|
| DavidYu | 创作者名称 |
| Qwen3.6 | 基座模型架构 |
| 40B | 参数量(由 27B 扩展而来) |
| Cloud4.6Opus | 蒸馏所用的教师模型 |
| Deckard | 架构增强策略(致敬《银翼杀手》角色) |
| Uncensored | 解除内容审查限制 |
| Thinking | 支持推理/思考模式 |
| NearCode | 代码能力增强 |
| IMatrix | 重要性矩阵量化方式 |
| Max-GGUF | 高质量 GGUF 打包格式 |
掌握这套命名规则后,你看到任何大模型名称都能快速理解其核心特性。
参数量与显存:到底需要多大显卡
FP16 原始精度下的显存估算
对于未量化的 FP16 原始模型,显存需求的估算非常简单:参数量 × 2 = 所需显存(GB)。例如 7B 模型需要约 14GB,32B 模型需要约 64GB。
这里的"×2"来自 FP16 格式本身:每个参数以 16 位(2 字节)浮点数存储,因此 1B(十亿)个参数恰好占用约 2GB 显存。FP16 是目前深度学习训练和推理的主流精度,它在保留足够数值精度的同时,将 FP32 的显存占用减半。但这个精度对个人用户来说基本不现实,所以我们重点关注量化后的需求。
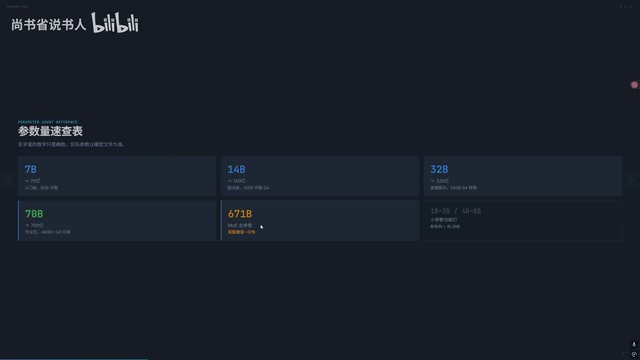
4-bit 量化显存速查表
量化(Quantization)是将模型权重从高精度浮点数压缩为低精度整数表示的技术。4-bit 量化(Q4)是目前最主流的"甜点精度"——每个参数仅占 0.5 字节,相比 FP16 体积缩小约 75%,而性能损失通常只有约 10% 左右。不同的量化算法(AWQ、GPTQ、GGUF 等)本质上都是在解决如何在压缩比和精度损失之间取得最优平衡的问题。估算公式为:参数量 ÷ 1.5~1.75 ≈ 所需显存(GB)(不含上下文)。
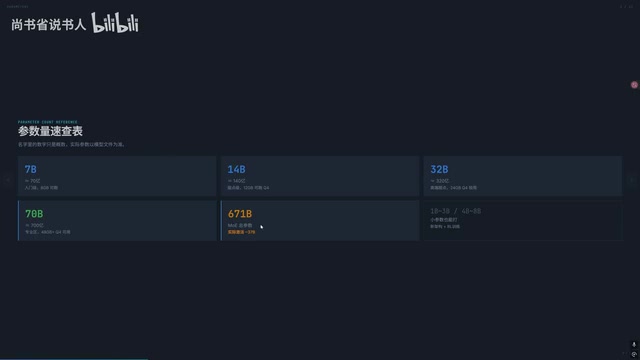
| 模型体量 | Q4 最低显存(不含上下文) | 建议显存 |
|---|---|---|
| 7B | 4GB | 8GB |
| 14B | 8GB | 12GB |
| 27B | ~15.5GB | 24GB |
| 32B | 18GB | 24GB+ |
| 70B | 40GB+ | 48GB |
需要特别强调的是,以上数字不包含上下文占用。实际使用中,上下文的显存消耗往往被严重低估。
上下文长度:最容易被忽视的显存杀手
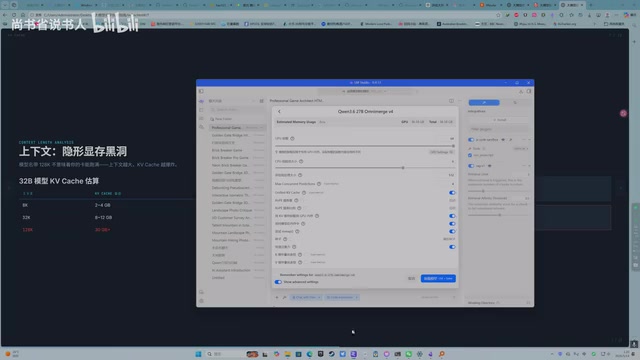
上下文长度(Context Length)直接影响模型能"记住"多少对话内容。理解这一点需要先了解 Transformer 架构中的 KV Cache 机制:在自回归生成过程中,模型每生成一个 token 都需要访问所有历史 token 的注意力键值对(Key-Value Pairs)。KV Cache 将这些中间计算结果缓存在显存中以避免重复计算,但代价是显存占用随上下文长度线性增长。其占用量大致为:模型层数 × 注意力头数 × 头维度 × 序列长度 × 2(K 和 V 各一份)× 精度字节数。
以 32B Q4 模型为例:模型本身占用约 18GB,但如果开启 128K 上下文,光 KV Cache 就要额外占用约 30GB——比模型本身还大!
实际体验中,使用 RTX 5090(32GB 显存)部署千问 3.6 的 27B 模型,上下文也只能拉到约 60K 左右。如果你要用 Agentic 工作流或长文档处理,至少需要 50-100K 的上下文,这对显存的压力非常大。
好在 LM Studio 等工具支持将 KV Cache 卸载到内存中,可以一定程度缓解显存不足的问题。
前提是你的系统内存要足够大——如果部署 32B 模型,建议至少配备 64GB 内存作为后备。
MOE 模型的显存陷阱
Mixture of Experts(专家混合,MOE)是一种将模型分割为多个"专家"子网络的架构,由门控网络动态决定每个 token 激活哪些专家进行处理。这一设计最早由 Google 在 Switch Transformer 中大规模验证,后被 DeepSeek、阿里等广泛采用。其核心优势在于:用远超单一模型的总参数量换取更强的知识容量,同时单次推理只激活其中一小部分,计算量并不随总参数量线性增长。
很多人看到 MOE 模型时会产生误解。比如千问 3.6 的 35B MOE 模型每次只激活其中 3B 的参数,DeepSeek R1 的 671B 模型每次只激活 37B。
但这不意味着你只需要 3B 或 37B 对应的显存。
原因很简单:模型需要从全部参数中"挑选"出要激活的部分,这个挑选过程要求所有参数都在高速存储中随时可访问。所以部署 MOE 模型时,必须按总参数量来估算显存需求,而非激活参数量。
虽然社区有人在研究将非激活参数放到内存甚至 SSD 上的方案,但目前速度损失仍然很大,不建议作为常规方案。
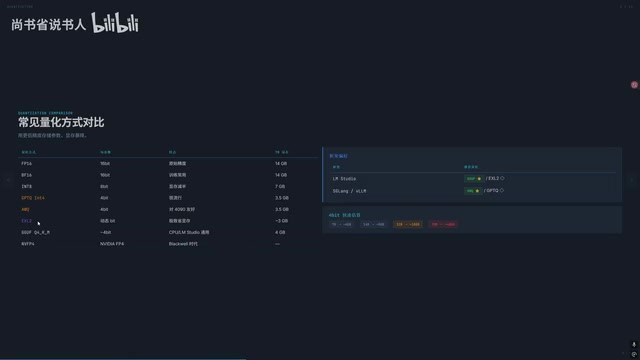
量化策略对比:GGUF、AWQ 还是 EXL2
主流量化方式一览
| 量化方式 | 适用工具 | 特点 |
|---|---|---|
| GGUF + Q4_K_M | LM Studio / Ollama | 最通用,HuggingFace 上最常见 |
| AWQ / GPTQ | LM Studio / Ollama | 支持广泛,但精度一般 |
| EXL2 | vLLM / SGLang | 显存节省显著,但不支持 Ollama/LM Studio |
| NVFP4 | Blackwell 架构专用 | 50 系显卡神器,精度逼近 FP16,速度快 40-50% |
| IMatrix | GGUF 格式 | 重要性矩阵量化,Dense 模型的精度救星 |
IMatrix 量化:Dense 模型的精度救星
IMatrix(重要性矩阵量化)是目前 Dense 模型最值得关注的量化方式。它的原理类似于 MOE 模型的 APEX 量化:通过在校准数据集上运行推理,统计模型各层激活值的重要程度,对关键层采用高精度量化(如 Q8),对边缘层采用低精度量化(如 Q4)。这种"差异化精度分配"策略,使得整体体积维持在 Q4 水平的同时,能让性能显著接近 FP16 原版——相当于把有限的"精度预算"花在刀刃上。
如果你要下载 27B Dense 模型,优先选择带 IMatrix 标识的版本。
50 系显卡用户必看:NVFP4 量化
NVFP4 是 NVIDIA 为 Blackwell 架构(RTX 50 系列)专门设计的 4 位浮点量化格式。与传统 INT4 整数量化不同,FP4 保留了浮点数的指数位,能更精确地表示权重的动态范围,因此精度损失远小于 INT4。更关键的是,Blackwell 架构在硬件层面原生集成了 FP4 张量运算单元,使其吞吐量相比 FP16 提升显著——这正是"速度快 40-50%"的底层原因。
如果你拥有 RTX 5090 等 Blackwell 架构显卡,NVFP4 量化是首选。但千万不要在非 50 系显卡上使用:在缺乏硬件原生支持的架构上,FP4 运算会退化为软件模拟,不仅无法获得速度优势,还会因格式转换带来额外开销,导致显存占用大、精度差,毫无优势。
按显存档位选择合适的模型
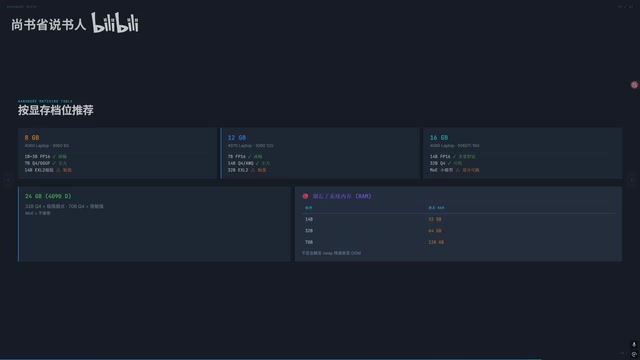
- 8GB 显存:只能跑 7B 及以下模型,体验有限
- 12GB 显存:可以尝试 14B Q4,上下文会比较短
- 16GB 显存:14B Q4 较为舒适,32B 基本不可行
- 24GB 显存:32B Q4 可用但上下文受限,建议搭配 64GB 内存
- 32GB 显存(5090):32B Q4 + 32K 上下文,或 27B + 60K 上下文
一个实用的建议:不要为了跑更大的模型而牺牲上下文长度。一个上下文充足的 14B 模型,在实际使用中往往比上下文捉襟见肘的 32B 模型更好用。
总结
理解大模型命名规则和显存估算方法,能帮你在下载前就做出正确判断,避免浪费时间和带宽。记住三个核心原则:参数量决定基础显存需求,量化策略决定精度与体积的平衡,上下文长度(及其背后的 KV Cache 机制)是最容易被忽视的显存杀手。根据自己的硬件条件,选择合适体量和量化方式的模型,才能获得最佳的使用体验。
核心要点
- 大模型名称中每个字段都有明确含义:模型系列、参数量(B=十亿)、微调类型、量化策略等,掌握规则后可快速解读任何模型
- 4-bit 量化是主流甜点精度,显存估算公式为参数量÷1.5~1.75,但必须额外考虑上下文占用——128K 上下文的 KV Cache 可能比模型本身还占显存
- MOE 模型虽然每次只激活部分参数,但部署时必须按总参数量估算显存,不能只看激活参数量
- IMatrix 重要性矩阵量化通过对关键层高精度、边缘层低精度的差异化策略,让 Dense 模型在 Q4 体积下逼近 FP16 性能
- 50 系显卡用户应首选 NVFP4 量化(硬件原生支持,精度高、速度快 40-50%),非 Blackwell 架构切勿使用
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。