LLM可观测性与Eval实战:大模型上线后的监控评估全指南
当你的AI Agent终于上线了,然后呢?你怎么知道它在生产环境中到底做了什么?出了问题怎么定位?改了一个bug会不会引发三个新问题?
在AI Engineer大会上,Arise AI的AI架构师Dat分享了他在企业级LLM可观测性、评估(Eval)和实验改进方面的深度实践。作为一个去年消耗了1000亿到1万亿token的重度从业者,他与全球最大的企业合作,亲眼见证了它们在AI转型过程中遇到的核心痛点。要理解这个数字的含义——一个中等规模的企业客服Agent每天可能处理数十万次对话,每次对话消耗数千到数万token,一个大型企业的AI系统年消耗量达到千亿级别完全合理。在这种规模下,每个token的成本优化、每次不必要的API调用的消除,都直接影响数十万甚至数百万美元的运营成本。
本文将系统梳理他分享的三大核心主题:可观测性、评估体系和实验改进闭环。
可观测性:你的Agent到底在干什么?
从Trace开始,但不止于Trace
Dat开场就点明了一个关键认知:AI本质上就是软件工程的重新想象,同样的模式,不同的风味。既然是工程问题,第一步就是可观测性——搞清楚你构建的系统里到底发生了什么。
Arise的技术栈完全基于OpenTelemetry(OTEL),这是传统软件工程中已经被广泛验证的可观测性标准。OpenTelemetry是由Cloud Native Computing Foundation(CNCF)托管的开源可观测性框架,由OpenTracing和OpenCensus两个项目合并而来,提供了一套标准化的API、SDK和工具,用于生成、收集和导出三类核心遥测数据:Trace(分布式追踪)、Metrics(指标)和Logs(日志)。在传统微服务架构中,OTEL已经成为事实上的可观测性标准,被Datadog、Grafana、Jaeger等主流监控平台广泛支持。将OTEL引入AI系统意味着开发者可以复用已有的监控基础设施,而不需要为AI应用单独构建一套全新的可观测性体系。
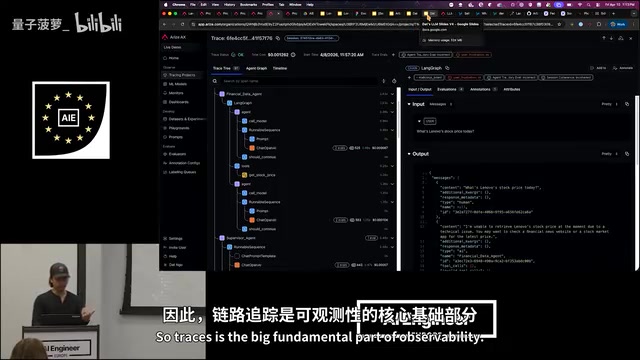
通过自动插桩(auto-instrumentation),开发者只需添加一行代码,系统就能自动捕获框架和SDK中的调用链路,生成trace和span视图。这里有必要解释一下这两个核心概念:Trace和Span源自Google的Dapper论文,是分布式追踪系统的基本构建块。一个Trace代表一个完整的请求在系统中的端到端执行路径,而Span是Trace中的最小工作单元,代表一次具体的操作。Span之间通过父子关系组成树状结构,完整描述了请求的因果链路。在AI Agent的语境下,一个Trace可能包含:用户输入解析→意图识别→工具选择→外部API调用→结果合成→响应生成等多个Span。每个Span都携带时间戳、持续时间、状态码和自定义属性(如token消耗量、模型名称),使得开发者可以精确定位性能瓶颈和错误根因。
这里有一个重要的认知转变:在AI系统中,代码本身并不能审计Agent的行为,真正能做到这一点的是遥测数据(telemetry)。Trace记录了Agent的完整行为轨迹,是可观测性的基础。
Session与分布式视图
但Trace只是起点。Dat提到了Anthropic发布的Managed Agents论文,引出了Session(会话)的概念。Anthropic在2025年发布的这份关于构建高效Agent的指南中,系统性地阐述了Agent架构的设计原则,其中一个核心洞察是将Agent的生命周期从单次请求-响应扩展到多轮会话维度。在这个框架下,Agent不再是无状态的函数调用,而是一个持续运行的状态机,需要在多轮交互中维护上下文、追踪目标完成度、处理中断和恢复。
Session关注的是状态——Agent与用户之间的多轮对话、多次运行之间的状态流转。对于企业用户来说,他们往往不关心Agent调用了哪个工具的细节,而是关心:最终用户满意吗?所有问题都被回答了吗?
Arise AX提供了一个独特的分布式视图功能。由于Agent的行为是非确定性的,同一个Agent可能走不同的分支路径。这个视图允许你俯瞰所有实例化的Agent行为分布:
- 多少流量走了A分支,多少走了B分支?
- 某个特定分支中的哪个组件导致了显著的延迟?
- 不同路径下的评估信号有何差异?
这直接引出了**轨迹评估(Trajectory Eval)**的概念:当Agent走路径A时一切正常,但走路径B时信号下降,根因可能是组件调用顺序错误——比如B依赖A的输出,但LLM决定先调用了B。
评估体系:五种信号与四个层级
评估信号的五种类型
Dat将评估信号分为五种类型,构成了一个完整的评估矩阵:
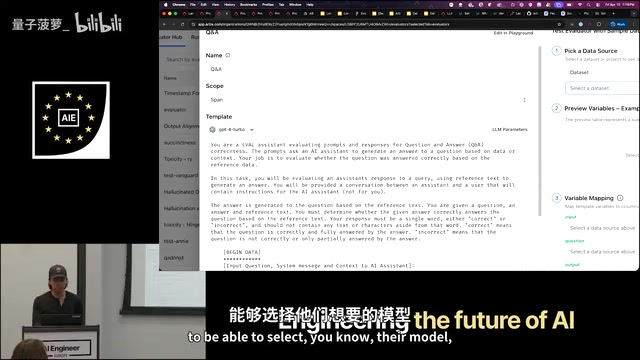
1. LLM-as-a-Judge(LLM作为评判者)
看似简单,实际上可以非常复杂。这是当前最流行的自动化评估方式,用一个大模型来评判另一个大模型的输出质量。LLM-as-a-Judge范式最早由UC Berkeley等机构在2023年的论文中系统化提出,其核心优势在于可扩展性强、成本远低于人工标注,且在许多任务上与人类评判的一致性可达80%以上。但它也存在已知的系统性偏差:位置偏差(倾向于选择排在前面的答案)、冗长偏差(倾向于给更长的回答更高分)、以及自我偏好偏差(倾向于偏好自己生成的内容)。理解这些偏差对于正确使用这一评估方式至关重要。
2. 人类反馈
无论是终端用户的使用反馈,还是产品经理的主观判断,人类信号都极其宝贵,是校准自动化评估的锚点。
3. 黄金数据集(Golden Dataset)
由领域专家标注的高质量数据集,代表了你最信任的评估标准。一个关键技巧是:用黄金数据集来校准你的LLM-as-a-Judge,让LLM学会逼近专家的判断。这本质上是在自动化评估和人类判断之间建立一个可靠的对齐桥梁——通过对比LLM评判结果与专家标注的差异,可以系统性地识别和修正LLM评判者的偏差,使其在大规模自动化评估中保持与人类判断的高度一致。
4. 确定性评估
不是所有评估都需要LLM。比如检查JSON输出是否合法、schema是否正确、必填字段是否非空——这些用简单的逻辑判断就够了,成本几乎为零。在千亿token规模的生产环境中,确定性评估的价值被进一步放大:它们能过滤掉大量明显的错误输出,避免将这些低质量结果送入昂贵的LLM-as-a-Judge流程,从而显著降低整体评估成本。
5. 业务指标
最终所有AI产品都服务于三个目的之一——赚更多钱、省更多钱、或节省更多时间。业务指标是衡量AI价值的终极标尺。
评估的四个作用域层级
评估不仅有类型之分,还有作用域之分,这是很多团队容易忽略的维度:
- Span级别:评估单个组件的输入输出,最简单直接
- Multi-Span级别:需要跨多个组件的数据才能完成评估,比如评估多个Agent之间的数据传递质量
- Trajectory级别:评估整个调用链路的轨迹是否正确
- Session级别:最宏观的层面,评估整个会话状态机——用户是否曾感到沮丧?所有问题是否都得到了解答?
Dat特别强调了一个务实的原则:能评估不代表应该评估。你需要找到最小化的评估集合来判断系统是否按预期工作,因为每一项评估都有成本。
实验改进:从发现问题到自动化闭环
数据集驱动的实验流程
有了可观测性和评估体系,下一步就是改进。Dat描述的工作流非常清晰:
- 从Trace中找到信号异常的数据点
- 将这些数据收集成数据集(或直接上传输入输出对)
- 在数据集上运行实验——修改Prompt、更换模型、调整编排逻辑、变更配置
- 对比实验结果,量化改进效果
但这里有一个关键警告:在非确定性系统中,你以为修复了一个问题,可能同时制造了两三个回归(regression)。这个问题的根源在于LLM系统与传统软件的本质差异。传统软件是确定性的——相同的输入总是产生相同的输出,这使得回归测试相对直接。但LLM驱动的AI系统本质上是非确定性的:即使使用相同的Prompt和参数,由于模型内部的采样机制(temperature、top-p等)、API版本更新、甚至浮点运算精度差异,输出都可能不同。这种非确定性在Agent系统中被进一步放大——Agent可能根据中间结果动态选择不同的工具调用路径,形成指数级的行为空间。这意味着你不能简单地断言输出等于某个固定值,而需要基于统计分布和语义相似度来判断系统行为是否在可接受范围内。一个Prompt的微小修改可能在95%的场景下改善了效果,却在5%的边缘场景中引发严重的质量下降。这就是为什么实验必须系统化,而不是凭直觉修改。
两类角色的高效协作
Dat观察到,优秀的AI产品团队通常有两类角色的紧密协作:
- 技术人员(AI工程师、开发者):擅长构建系统和自动化流程
- 领域专家(产品经理、业务专家):理解AI体验应该是什么样的
最佳实践是让会写代码的人专注于工程实现,让懂领域的人负责Prompt工程和评估标准的制定。Arise的产品设计也体现了这一点——既支持UI上的非技术操作,也支持编程式的评估运行。
未来方向:自动化整个改进飞轮
Dat分享的最具前瞻性的观点是:整个可观测性→评估→实验改进的飞轮都应该被自动化。
Arise内置了一个名为Alex的AI系统,可以通过CLI、工具集或直接被Claude Code等编码Agent调用。你可以直接问Alex:"我的应用有什么问题吗?"它会自动分析Trace数据,发现高延迟、错误等异常,甚至主动创建新的评估指标。
Dat的终极愿景是:用户甚至不需要自己选择评估指标,AI应该根据Trace上下文自动判断需要什么评估,并在发现变化时自动创建新的评估。这不是魔法,但应该让人感觉像魔法。
产品生态:开源与企业级方案
Arise目前有两个产品线:
- Arise Phoenix:开源版本,单容器部署,无需Kubernetes,适合工程师快速上手验证
- Arise AX:企业版,服务于Uber、Booking、Reddit等大型企业,提供完整的分布式视图和协作功能
总结
从这次分享中可以提炼出一个核心框架:LLM应用的生产化不是一次性的部署,而是一个持续的观测→评估→实验→改进的闭环。
在这个闭环中:
- 可观测性是基础设施,让你看见系统的真实行为
- 评估体系是信号来源,告诉你哪里好、哪里有问题
- 实验改进是价值交付,把发现的问题转化为实际优化
- 自动化是终极方向,让整个飞轮越转越快
对于正在将AI Agent推向生产的团队来说,最实用的建议可能是:先把OpenTelemetry接入做好,再从最小化的评估集合开始,逐步构建起完整的质量保障体系。不要试图一步到位,但也不要在没有任何可观测性的情况下裸奔上线。
相关推荐
Vibe Coding完全指南:零基础用AI把想法变成产品
详解Vibe Coding氛围编程的完整流程:从想法梳理、产品文档生成、UI设计到代码实现,用Gemini、Figma Make、Cursor等AI工具,零代码基础也能独立开发应用并实现变现。
Vibe Coding入门指南:零基础让AI帮你写代码
Vibe Coding(氛围编程)让不会写代码的人也能开发软件。本文详解Vibe Coding核心理念、与传统编程的区别,以及Miniconda虚拟环境配置全流程,助你迈出AI编程第一步。
DeepSeek识图模式实测:截图转代码还原度高达80%
实测DeepSeek识图模式的界面复刻能力,通过Ant Design官网、百度、B站、苹果官网等多个案例,展示其截图转代码的实际效果,分析核心应用场景与局限性。