大模型微调入门:用你的数据再教AI几招

什么是微调?站在巨人肩膀上的聪明做法
想让AI更懂你的业务,很多人的第一反应是"从头训练一个大模型"。但现实是,这条路的成本极其高昂——动辄数百万甚至上千万的算力投入,对绝大多数企业来说并不现实。
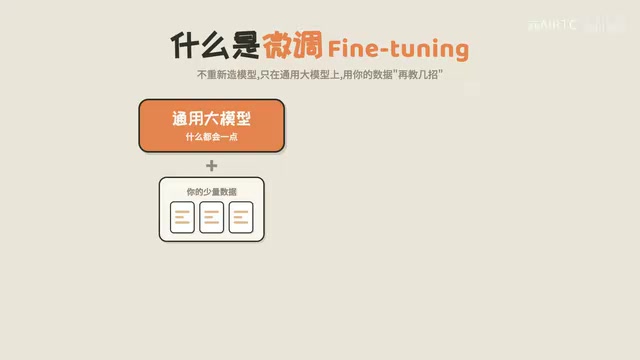
更实际的做法叫做微调(Fine-tuning)。简单来说,就是拿一个已经很聪明的通用大模型当底子,再喂给它一批你自己的数据——比如你公司的话术、你行业的案例——让它在这个底子上再学几招,最终得到一个更懂你的专用模型。

这就好比你招了一个名校毕业的高材生,他已经具备了扎实的通用知识和推理能力,你不需要从小学数学开始教他,只需要带他熟悉你公司的业务流程、行业术语和工作规范,他就能快速上手。微调做的就是这件事。
要理解微调为什么有效,需要先了解大模型的训练分为两个阶段。**预训练(Pre-training)**是第一阶段,模型在这个阶段消化互联网上数万亿token的文本数据,通过自监督学习(如预测下一个token)来习得语言结构、世界知识和推理模式。这个过程通常需要数千张GPU运行数周甚至数月,耗资巨大。微调则是第二阶段,使用远小于预训练规模的数据集,通过监督学习让模型适应特定任务。从技术角度看,微调本质上是在预训练模型已经收敛的参数空间附近做小幅调整,而非重新搜索整个参数空间——这就是它能以极低成本获得显著效果的根本原因。
微调的三个核心特征
理解微调,需要抓住以下三个关键点:
特征一:通用能力保留,只叠加专业技能
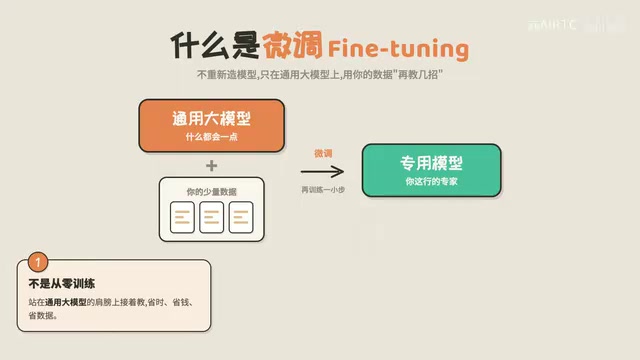
微调并不是"从零开始的丛林训练"。通用大模型在预训练阶段已经学到了海量的语言知识、逻辑推理能力和世界常识,这些能力在微调过程中是保留的。微调只是在这个基础上叠加一层专业能力,而不是推倒重来。
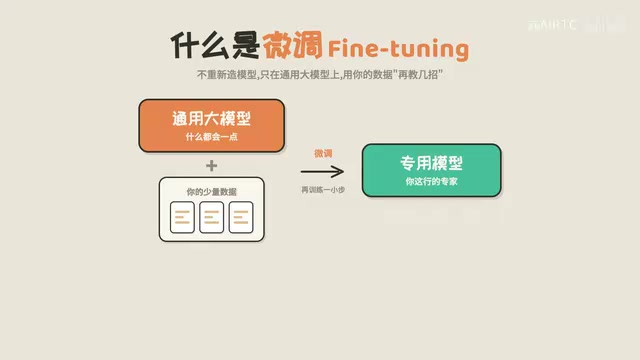
这意味着微调后的模型既保留了通用大模型的"聪明劲儿",又获得了你所需要的专业技能。这正是微调最大的优势——成本低、效率高、效果好。
现代微调技术已经发展出多种高效实现方式,进一步降低了门槛。全参数微调(Full Fine-tuning)会更新模型所有参数,效果最好但成本最高。更流行的是参数高效微调(PEFT),其中LoRA(Low-Rank Adaptation)是最具代表性的方法——它通过在模型的注意力层插入低秩矩阵,只训练这些新增的少量参数(通常不到原模型参数的1%),就能达到接近全参数微调的效果。QLoRA则进一步将基础模型量化为4bit,使得在单张消费级GPU上微调70亿参数的模型成为可能。这些技术让微调不再是大厂的专利,中小团队甚至个人开发者都能负担得起。
特征二:数据质量远比数量重要
微调只需要喂你自己的数据,而且数据质量比数量更重要。很多人以为需要海量数据才能微调,实际上几百到上千条高质量样本,往往就足够了。
什么是"高质量样本"?可以从三个维度来衡量:
- 格式规范:输入和输出的格式一致、清晰
- 内容准确:答案本身是正确的、符合业务标准的
- 覆盖典型场景:涵盖你业务中最常见、最重要的情况
与其花时间凑一万条质量参差不齐的数据,不如精心打磨五百条高质量的标注样本。
特征三:产出一个稳定的专用模型
微调的最终成果是得到一个专用模型。这个模型会更稳定地按照你要求的风格、格式、口吻来输出内容。相比每次都在提示词里反复强调"请用某某风格回答",微调后的模型已经把这些要求"内化"了,输出的一致性和稳定性会大幅提升。
这在实际业务中非常有价值。比如客服场景中,你希望AI始终用温和专业的语气回复,并且严格遵循公司的话术规范;或者在内容生成场景中,你需要AI始终输出特定格式的报告。这些需求通过微调来实现,效果远比单纯依赖提示词工程更可靠。
微调不是万能药:何时该用,何时不该用
虽然微调很强大,但并不是所有场景都需要它。在决定是否微调之前,建议先评估两个更轻量的替代方案:
替代方案一:RAG(检索增强生成)
如果你的核心需求是让AI能够引用最新的、特定的知识库内容(比如产品文档、政策法规),那么RAG可能是更好的选择。RAG通过在生成时实时检索相关文档,让模型"有据可查",而不需要把知识"塞进"模型参数里。
RAG的具体工作流程分为三步:首先将知识库文档切分为小块,并通过嵌入模型(Embedding Model)转化为向量,存入向量数据库(如Pinecone、Milvus等);当用户提问时,系统先将问题转化为向量,在向量数据库中检索语义最相近的文档片段;最后将检索到的内容作为上下文拼接到提示词中,交给大模型生成最终回答。RAG的核心优势在于知识可以实时更新(只需更新向量数据库),且回答可溯源——你能清楚知道模型引用了哪段原文。但它无法改变模型本身的推理方式和输出风格,这正是RAG与微调的本质区别。
替代方案二:提示词工程(Prompt Engineering)
如果你的需求只是调整输出格式或风格,写好系统提示词(System Prompt)可能就够了。这是成本最低、见效最快的方式。
提示词工程通过精心设计输入指令来引导模型行为,常见技巧包括:用系统提示词设定角色和约束、通过少样本示例(Few-shot)提供参考格式、用思维链(Chain-of-Thought)引导复杂推理过程等。然而提示词工程存在明确的天花板:每次请求都需要携带完整的指令文本,增加了token消耗和推理延迟;模型对长提示词的遵循度会随长度增加而下降(即"指令遗忘"现象);且无法让模型真正"学会"新的知识模式,只能在其已有能力范围内做引导。当你发现提示词已经超过2000-3000字仍无法稳定获得满意输出时,通常意味着需要认真考虑微调了。
什么时候才真正需要微调?
当你遇到以下情况时,微调才是最佳选择:
- 需要模型深度理解特定领域的专业术语和逻辑
- 对输出的一致性和稳定性有极高要求
- 提示词已经写得很长但效果仍不理想
- 需要降低推理成本(微调后的小模型可能替代大模型+长提示词的组合)
最后一点值得展开说明。假设你当前使用GPT-4级别的大模型配合2000字的系统提示词来完成某项任务,每次调用的成本较高。通过微调,你可以将这些"指令知识"内化到一个7B或13B参数的小模型中,使其无需长提示词就能完成同等质量的输出。这样不仅单次推理的token消耗大幅降低,小模型本身的推理速度也更快,还可以部署在更便宜的硬件上。OpenAI的研究表明,经过良好微调的小模型在特定任务上可以达到甚至超越未微调大模型的表现——这对于高频调用的生产环境来说,意味着巨大的成本节约。
总结:先想清楚再动手
微调的本质,就是站在巨人的肩膀上,再教它几招你的独门手艺。它不需要从零开始,不需要海量数据,但能让你获得一个真正懂你业务的专用AI模型。
不过,在动手微调之前,先问自己一个问题:RAG或者好的提示词能不能解决我的问题?如果能,那就不必微调;如果不能,微调就是你最值得投入的方向。技术选型的智慧,往往就在于知道什么时候该用什么工具。
核心要点
相关推荐
WWDC发布会前瞻:全新Siri重塑、AI大升级与系统性能优化
苹果WWDC大会即将发布重大系统更新,包括彻底重塑的Siri聊天机器人、更具吸引力的AI功能,以及性能大幅优化的操作系统。详解三大核心升级方向及行业影响。
OpenAI投资者创新日:Codex如何重塑企业工作流
OpenAI投资者创新日:Codex如何重塑企业工作流
OpenAI投资者创新日揭示企业AI应用新趋势:从提问模式到执行模式,Codex与ChatGPT Enterprise如何通过上下文决策支持、数据处理加速和组织级GPTs生态,驱动企业级工作流变革与组织转型。
Siri重启背后的三条关键叙事线
Apple Siri正经历史上最大规模重启,Tim Cook确立AI战略方向,Craig Federighi统领AI整合,Mike Rockwell从底层重塑Siri。深度解析三条叙事线如何交汇,揭示Apple在AI时代的全面布局与追赶策略。