打造AI第二大脑:本地数据库+MCP零代码部署指南
本地AI知识库方案:让AI成为你永不遗忘的第二大脑
文章介绍了一套基于向量数据库+SQL混合架构、MCP协议和Obsidian的本地AI知识管理系统。该系统通过语义检索实现精准知识查找,支持收藏即入库的跨时间回溯,以及AI主动搜索更新知识库。整套方案零代码部署,约一小时可完成搭建,将个人知识管理从被动存储升级为主动智能检索。
为什么你需要一个「第二大脑」
我们每天都在消费大量信息——笔记、学习资料、收藏的网页、视频、照片,但这些内容往往散落在各个角落,需要时却怎么也找不到。如果能把这些数据全部接入AI,让它随时帮你检索、总结、解读,是不是就像拥有了一个永不遗忘的「第二大脑」?
「第二大脑」(Second Brain)这一概念由生产力专家Tiago Forte系统化提出,并在其2022年出版的同名书籍中详细阐述。其核心方法论称为CODE框架:Capture(捕获)、Organize(组织)、Distill(提炼)、Express(表达)。Forte认为,人类大脑擅长产生想法而非存储想法,因此需要一套外部系统来承担记忆和组织的职能,从而解放认知资源用于更高层次的创造性思考。在AI工具普及之前,第二大脑的实现主要依赖Notion、Roam Research、Obsidian等工具的手动整理。而本文介绍的方案代表了第二大脑概念的进化版本:引入AI语义理解和自动化能力,将知识管理从「人工整理后检索」升级为「自动入库、智能检索、主动生长」的新范式。
最近B站上一位创作者分享了一套完整的本地AI知识库方案,通过将本地数据库与OpenClaw、Cursor等AI工具打通,实现了零代码、一小时部署的个人知识管理系统。整套方案的核心思路非常清晰:让AI成为你的记忆外挂,你学过的、看过的、想过的,它全都能帮你记住。
三个核心使用场景
场景一:基于语义的精准知识检索
最直观的用法是让AI在你的数据库中进行语义检索。比如你可以对AI说「帮我找关于GSAP动画库的文章并把全文发给我」,AI会立刻在本地数据库中搜索匹配内容,并将原文完整输出。这不是简单的关键词搜索,而是基于向量数据库的语义理解——向量数据库将文本内容通过嵌入模型(Embedding Model)转化为高维数值向量,每个向量代表文本的语义特征。当你输入查询时,系统同样将查询转化为向量,再通过余弦相似度等算法找出语义最接近的内容。这意味着即使你用不同的词汇描述同一概念,系统也能准确匹配——例如搜索「动画效果库」也能找到关于GSAP的文章,即使你记不清原文标题,只要描述大致内容就能找到。
场景二:收藏即入库,跨时间知识回溯
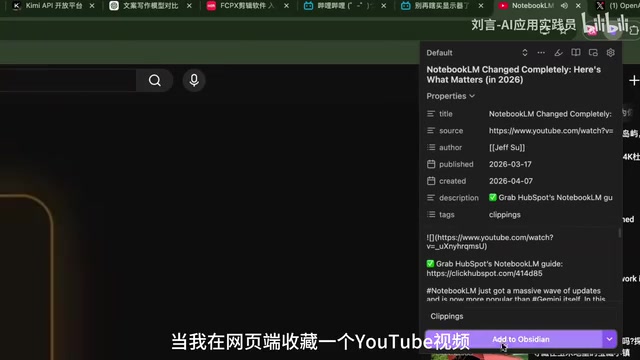
当你在网页端收藏一个YouTube视频或一篇文章后,AI可以直接帮你解读收藏的内容。更重要的是,这些内容会持久化存储在你的数据库中。以后任何时候你都可以问AI:「上个月我收藏的某个视频讲了什么?」——这种跨时间的知识回溯能力,是传统书签和收藏夹完全做不到的。
场景三:AI主动搜索并更新知识库
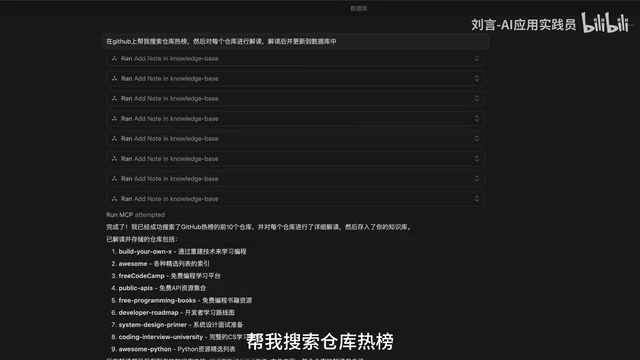
除了被动检索,你还可以让AI主动出击。比如让Cursor在GitHub上搜索仓库热榜,然后对每个热门项目进行解读,解读完成后自动更新到数据库中。这意味着你的知识库不仅是静态的存储,还能通过AI持续「生长」。
系统架构详解:三层组件协同工作
整套系统的架构并不复杂,核心围绕三个组件展开:
数据层:向量库 + SQL数据库混合架构
数据库部分采用了向量库 + SQL数据库的混合架构,这是当前AI应用中的主流数据层设计模式,两者各司其职、优势互补。SQL数据库(如SQLite、PostgreSQL)擅长处理结构化数据的精确查询,例如按时间范围筛选、按标签分类、统计收藏数量等操作;向量库(如Chroma、Pinecone、Weaviate)则专注于非结构化内容的语义相似度搜索,处理「找和这个主题相关的内容」这类模糊查询。
在实际系统中,一篇文章的元数据(标题、创建时间、标签、来源URL)存入SQL数据库,而文章正文经过嵌入模型处理后的向量存入向量库,两者通过文章ID关联。检索时,系统先用向量库找出语义相关的文章ID列表,再用SQL查询补充完整的元数据信息,最终返回给AI进行处理。这种分层设计兼顾了检索的语义灵活性与数据管理的结构化精确性,两者结合可以显著提高检索的精准性。
编辑层:Obsidian实时同步
数据库中的所有文章都可以用Obsidian来编辑和查看。Obsidian是一款基于本地Markdown文件的知识管理工具,自2020年发布以来迅速在知识工作者群体中积累了大量用户。其核心设计哲学是「你的数据永远属于你」——所有笔记以纯文本Markdown格式存储在本地文件夹,不依赖任何云服务或专有格式。Obsidian最具特色的功能是双向链接和知识图谱,允许用户在笔记之间建立网状关联,模拟人脑的联想记忆方式,社区插件数量超过1500个,涵盖几乎所有使用场景。
关键在于,Obsidian与数据库是实时绑定的——正因为Obsidian基于本地文件系统,任何对文件的修改都可以被外部程序实时监听,文章更新后两秒内就会同步到数据库中。这意味着你日常的写作、笔记工作流完全不需要改变,只需在Obsidian中正常操作即可。

交互层:MCP协议连接AI工具
OpenClaw或Cursor通过**MCP(Model Context Protocol)**协议与数据库实现联动。MCP是由Anthropic于2024年底提出并开源的标准化协议,旨在解决AI大模型与外部工具、数据源之间的集成碎片化问题。在MCP出现之前,每个AI应用都需要为不同的数据源单独开发适配层,维护成本极高。MCP定义了一套统一的客户端-服务器通信规范:AI助手作为客户端,各类工具和数据源作为MCP服务器,双方通过标准化接口交换信息。这使得同一个MCP服务器可以被Cursor、Claude Desktop、OpenClaw等多种AI工具复用,目前MCP生态已涵盖数据库、文件系统、浏览器控制、API调用等数十类服务器实现。通过MCP协议,AI不再是一个孤立的对话框,而是真正能够读写你的知识库的智能代理。
零代码部署流程:一小时搞定
这套系统最令人惊喜的地方在于部署门槛极低。据作者介绍,整个部署过程全程没有写一行代码,全部交给Cursor完成,大概一小时就能搞定。

具体做法是:作者已经将整个系统打包成提示词和Markdown文件,部署时直接丢给AI,通过几轮对话就能完成基础搭建。后期的微调可能因人而异,但核心框架的搭建确实可以在极短时间内完成。
这种「用AI部署AI系统」的方式本身就很有启发性——它说明在当前的AI能力水平下,很多原本需要开发经验的工作,已经可以通过自然语言对话来完成。
适用人群与注意事项
这套方案适合谁?
- 内容创作者:日常需要大量收集、整理、引用素材
- 学习者和研究者:需要管理大量学习笔记和参考资料
- 开发者:希望将技术文档、代码片段、项目笔记统一管理
- 知识工作者:任何需要频繁检索和复用信息的人
需要注意的问题
虽然方案看起来很诱人,但也有几点值得关注:
- 数据隐私与安全:所有数据存储在本地,这是优势,但也意味着备份和安全需要自己负责
- 长期维护成本:系统搭建容易,但数据清洗、向量库更新等工作需要持续投入
- AI API调用费用:频繁调用AI进行检索和总结,API费用可能是一笔不小的开支
- 基础概念门槛:虽然号称零代码,但对Obsidian、MCP协议、向量数据库等概念的基本理解仍然是必要的
总结
这套「第二大脑」方案的核心价值在于:将个人知识管理从被动存储升级为主动智能检索。通过向量数据库实现语义搜索,通过MCP协议打通AI工具链,通过Obsidian保持日常工作流的连贯性——三者结合,构成了一个真正实用的个人AI知识系统。
在AI工具日益成熟的今天,搭建这样一套系统的门槛已经大幅降低。如果你每天都在和大量信息打交道,不妨尝试搭建属于自己的「第二大脑」。
核心要点
- 通过向量库+SQL数据库的混合架构,实现对个人知识库的语义级精准检索
- 利用MCP协议将OpenClaw/Cursor等AI工具与本地数据库打通,实现双向读写联动
- Obsidian作为编辑层与数据库实时同步,保持日常笔记工作流不变
- 整套系统零代码部署,通过Cursor对话式搭建,约一小时可完成基础框架
- 系统支持主动搜索与被动检索两种模式,知识库可通过AI持续自动扩充
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。