Datasette 1.0a33发布:JSON Extras API全面扩展与AI辅助开发实践
概述
Datasette 项目迎来了 1.0a33 alpha 版本的发布,这是迈向稳定 1.0 版本的重要一步。本次更新的核心亮点是将 ?_extra= 模式从表(tables)扩展到了查询(queries)和行(rows),使得 API 的灵活性大幅提升。更值得关注的是,项目作者 Simon Willison 使用 Claude Fable 5 和 GPT-5.5 构建了一个交互式 API 探索工具来演示新功能,展现了 AI 辅助编程的实际生产力。
Datasette 与 SQLite 的技术背景
Datasette 是建立在 SQLite 之上的数据探索和发布工具。SQLite 是全球部署量最大的数据库引擎——据估计,全球活跃的 SQLite 实例超过一万亿个——它以单文件形式存储整个数据库,无需独立的服务器进程,广泛嵌入在手机、浏览器和操作系统中。
SQLite 由 D. Richard Hipp 于 2000 年创建,采用公有领域(Public Domain)许可证,这意味着它没有任何版权限制。与 MySQL、PostgreSQL 等客户端-服务器架构的数据库不同,SQLite 是一个进程内数据库库(in-process library),整个数据库存储在一个跨平台的磁盘文件中。每一部 Android 手机、每一台 iPhone、每一个 Chrome 和 Firefox 浏览器实例中都嵌入了 SQLite。它的可靠性经过了航空电子设备级别的测试验证——SQLite 的测试套件包含超过 1 亿行测试代码,代码与测试的比例约为 1:600。这种极致的可靠性和零运维特性,正是 Datasette 选择它作为底层存储引擎的根本原因。
Datasette 的核心洞察在于:将 SQLite 的轻量级特性与 Web 技术结合,任何人只需一个 .db 文件就能立即获得一个功能完整的 JSON API 和可视化界面。这种设计特别适合数据记者快速发布公共数据集、研究人员共享实验数据,以及开发者进行快速原型验证。正是这种「零配置、即时可用」的理念,让 Datasette 自 2018 年首次发布以来在开放数据社区中获得了广泛关注。
?_extra= 模式的全面扩展
从表到查询和行的统一覆盖
?_extra= 模式最早在 2023 年的 Datasette 1.0a3 版本中引入,当时仅支持表级别的额外数据请求。经过近三年的迭代,这一模式终于在 1.0a33 中实现了全面覆盖——开发者现在可以在查询和行的 API 端点中同样使用 extras 参数来获取额外的元数据。
这意味着当你请求 Datasette 的 JSON API 时,可以通过 ?_extra=columns 获取列名、通过 ?_extra=count 获取匹配行的总数、通过 ?_extra=count_sql 获取用于计算总数的 SQL 查询等。这种设计让 API 响应变得高度可定制——客户端只获取真正需要的数据,减少了不必要的带宽消耗。
按需加载的 API 设计哲学
?_extra= 模式本质上是一种按需加载(on-demand)的 API 设计策略,与 GraphQL 的字段选择理念有相似之处,但实现方式更加轻量。
GraphQL 由 Facebook 于 2012 年内部开发、2015 年开源,其核心创新之一就是让客户端精确声明需要哪些字段,从而解决 REST API 中普遍存在的「过度获取」(over-fetching)和「不足获取」(under-fetching)问题。过度获取指客户端收到了大量不需要的字段,浪费带宽;不足获取指一次请求无法满足需求,需要多次往返。然而 GraphQL 引入了较高的学习成本和服务端复杂度,需要定义 Schema、部署专用的 GraphQL 服务器。Datasette 的 ?_extra= 模式巧妙地在传统 REST 的简单性和 GraphQL 的灵活性之间找到了平衡点——它不需要任何额外的查询语言,仅通过标准的 URL 查询参数就实现了类似的按需数据获取能力。
在传统 REST API 中,端点返回的数据结构通常是固定的,客户端要么接受全部字段,要么需要服务端为不同场景创建多个端点(即所谓的「端点爆炸」问题)。而 ?_extra= 模式允许客户端通过查询参数声明需要哪些额外的元数据,服务端只计算和返回被请求的部分。
这种设计在性能上尤为重要——例如 count 操作在大数据集上可能需要全表扫描,耗时从毫秒级到数秒不等。如果默认包含在每次响应中,会严重拖慢 API 性能;而通过 extras 机制,只有在客户端明确需要时才执行计算。这种「默认精简、按需丰富」的策略,在 API 设计中被称为稀疏字段集(Sparse Fieldsets),JSON:API 规范中也有类似的设计模式。
官方文档终于补齐
值得一提的是,这个已经存在多年的功能模式现在终于有了完整的官方文档。对于一个开源项目来说,文档的完善往往标志着功能的成熟和稳定,这也进一步印证了 Datasette 正在认真地向 1.0 稳定版迈进。
AI 辅助构建的 Extras Explorer 工具
双 AI 协作的开发工作流
本次发布中最引人注目的细节之一,是 Simon Willison 用 AI 工具构建了一个交互式的 Datasette Extras API Explorer。他的工作流程颇具启发性:
- 规划阶段:使用 Claude Code 中的 Claude Fable 5 生成项目计划
- 实现阶段:使用 Codex Desktop 中的 GPT-5.5 xhigh 完成代码实现
这种「一个 AI 做规划、另一个 AI 做实现」的双模型协作模式,体现了当前 AI 辅助编程的前沿实践。Claude Fable 5 是 Anthropic 于 2025 年推出的模型,集成在 Claude Code 命令行工具中,以强大的推理规划和代码架构能力著称。GPT-5.5 则是 OpenAI 的最新一代模型,其 xhigh 计算配置代表最高推理强度,擅长将详细规划转化为高质量的代码实现。Codex Desktop 是 OpenAI 推出的本地化编程代理工具,能够直接在开发者的项目环境中执行代码生成和修改。
2024-2025 年间,AI 辅助编程工具经历了从代码补全到全栈编程代理的跨越式发展。早期的 GitHub Copilot 主要提供行级和函数级的代码补全,而 Claude Code、Codex Desktop 和 Cursor 等新一代工具已经能够理解整个项目的上下文,执行跨文件修改,甚至独立完成从需求分析到代码实现的完整开发流程。这些工具的底层依赖不同的大语言模型:Claude Code 使用 Anthropic 的 Claude 系列模型,Codex Desktop 使用 OpenAI 的 GPT 系列模型。在实际开发中,资深工程师越来越多地采用多模型策略——利用不同模型在推理、创意、代码生成等维度的差异化优势,组合出最优的开发工作流。Simon Willison 的双模型实践正是这一趋势的典型案例。
Simon 选择的这种双模型工作流反映了当前 AI 编程领域的一个重要趋势:不同模型在不同任务维度上各有优势,资深开发者开始像组建团队一样组合使用多个 AI 模型,让每个模型发挥其最擅长的能力。Simon 本人也在博文中感叹「API 探索工具现在几乎是免费构建的」,这句话背后是 AI 编程工具对开发效率的巨大提升。
Explorer 工具的核心功能
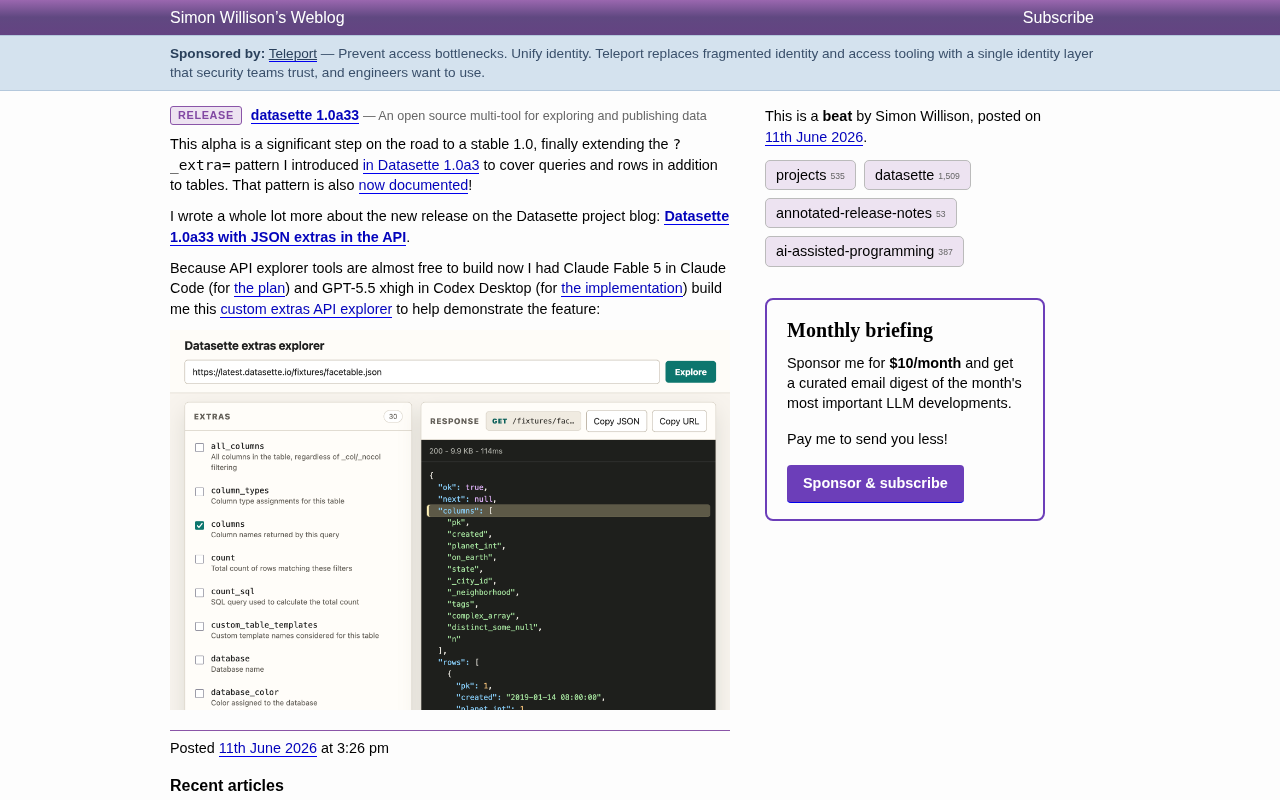
从截图可以看到,这个工具提供了直观的界面:
- 左侧面板列出了所有可用的 extras(共 30 个),以复选框形式呈现
- 右侧面板实时显示 API 响应,包括状态码、响应大小和耗时
- 支持一键复制 JSON 和 URL,方便开发者快速调试
这个工具本身就是 Datasette extras 功能的最佳文档——通过交互式探索,开发者可以直观地理解每个 extra 参数的作用。这种「可交互的文档」理念在开发者工具领域越来越流行,Stripe 的 API 文档和 Swagger UI 都是类似思路的先驱,而 AI 的介入让构建这类工具的成本大幅降低。
Datasette 1.0 的路线图与设计哲学
Datasette 从 2018 年首次发布至今,已经经历了 33 个 alpha 版本的迭代。这种漫长的预发布周期在开源社区中并不罕见——它遵循语义化版本控制(Semantic Versioning)的预发布标识规范。
语义化版本控制由 GitHub 联合创始人 Tom Preston-Werner 于 2011 年提出,采用 MAJOR.MINOR.PATCH 的三段式版本号。其核心契约是:MAJOR 版本号变更意味着存在不兼容的 API 修改,MINOR 版本号变更意味着新增了向后兼容的功能,PATCH 版本号变更意味着进行了向后兼容的缺陷修复。在实践中,许多知名项目都经历了漫长的预发布周期:Rust 语言在 1.0 之前经历了 0.1 到 0.12 共 13 个版本,Svelte 框架的 5.0 也经历了大量预发布迭代。这种审慎态度源于一个现实:1.0 发布后,任何破坏性变更都会影响所有依赖该库的下游项目,修复成本呈指数级增长。
在这一体系中,alpha 版本意味着 API 接口可能随时变更,不建议用于生产环境;beta 版本则表示功能基本冻结,仅修复缺陷;而正式的 1.0 版本意味着公共 API 的稳定承诺——后续的非主版本更新将保持向后兼容。Datasette 经历 33 个 alpha 迭代才趋近 1.0,体现了作者对 API 稳定性的极度审慎——一旦发布 1.0,任何破坏性变更都需要等到 2.0 才能引入。
作为一个将 SQLite 数据库即时转化为 JSON API 和交互式界面的工具,Datasette 在数据新闻、开放数据和快速原型开发领域有着广泛的应用。数据新闻(Data Journalism)是一种以结构化数据分析驱动报道的新闻实践,记者需要快速探索、查询和发布大量公共数据集。传统做法需要搭建数据库服务器和编写后端代码,而 Datasette 将这一过程缩短到几分钟。例如,美国多家新闻机构使用 Datasette 发布政府预算数据、选举捐款记录和环境监测数据,让读者可以直接通过 Web 界面进行自助查询。在开放数据运动中,Datasette 也被政府机构和非营利组织用于快速搭建数据门户,降低了数据开放的技术门槛。
从 ?_extra= 模式的演进可以看出 Simon Willison 对 API 设计的深思熟虑:既要保持向后兼容,又要提供足够的灵活性。这种渐进式的设计哲学,让 Datasette 能够在不破坏现有用户工作流的前提下持续进化。
总结
1.0a33 版本虽然是 alpha,但它标志着 Datasette API 设计的成熟。?_extra= 模式的全面覆盖为最终的 1.0 稳定版奠定了坚实基础。而 AI 辅助构建 Explorer 工具的实践,则为我们展示了一种高效的开发者工具构建范式——当 AI 能够快速生成辅助工具时,软件的文档和可发现性都将得到质的提升。
核心要点
核心要点
相关推荐
AI Agent核心架构拆解:从概念到企业级智能体搭建
深度解析AI Agent智能体的三大核心架构:感知模块、大脑模块与行动模块,详解RAG记忆系统、工具调用机制及Chain of Thought推理能力,附企业级智能体开发技能路线图。
200行Python代码从零搭建AI Agent智能体实战教程
用200行Python代码从零搭建AI Agent智能体,逐步拆解提示词、记忆、工具调用、RAG检索增强和Skill技能五大核心模块,适合Python开发者快速入门Agent开发。
Anthropic撤回Claude隐形限制AI研究者的争议政策
Anthropic因Claude Fable/Mythos模型隐形限制前沿LLM开发请求的政策遭社区强烈反对后迅速撤回。本文详解事件始末、隐形安全措施的争议本质、Anthropic的修正方案及对AI行业透明度的深远启示。