o1、o1 pro与o3-mini-high编程能力深度对比:Deep Research实测分析
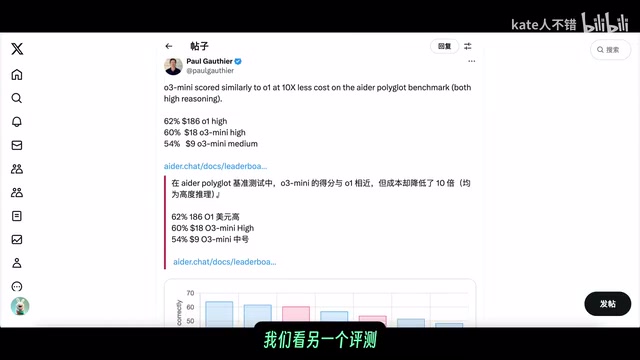
Deep Research系统对比o1、o1 pro和o3-mini-high三模型编程能力,揭示各自优劣与适用场景。
文章通过OpenAI Deep Research功能,在9分钟内自动生成了o1、o1 pro和o3-mini-high三个模型编程能力的深度对比报告。结论显示:o1 pro在代码质量、复杂任务推理和可靠性上均最优但成本最高;o3-mini-high以小模型实现接近o1的能力,胜在速度与成本;o1存在"过度推理"的双刃剑效应。文章同时展示了Deep Research作为自主研究代理的独特价值——能综合多源数据提出深度洞察,而非简单信息堆砌。
引言
OpenAI推出的Deep Research功能正在改变人们进行技术调研的方式。它不仅能检索信息,更善于提出有用的分析和观点——这是一种全新的研究形式。
Deep Research是基于o3模型构建的自主研究代理(Autonomous Research Agent),于2025年初推出。它能够自主规划研究路径、在互联网上执行多轮搜索、阅读并综合数十乃至上百个网页内容,最终生成结构化的深度报告。这与传统的RAG(检索增强生成)有本质区别——RAG通常是单次检索后直接生成,而Deep Research会根据中间结果动态调整搜索策略,模拟人类研究员的迭代思考过程。今天我们通过一个实际案例,看看Deep Research如何帮助我们系统对比o1、o1 pro和o3-mini-high三个模型的编程能力。
整个分析报告由Deep Research在约9分钟内自动生成,引用了大量来自OpenAI官网和学术论文的信息源,展现了令人印象深刻的深度和广度。
官方编程基准数据回顾
在进入Deep Research的分析之前,我们先看看OpenAI官方公布的编程能力数据。理解这些数据,首先需要了解各基准测试的侧重点:Codeforces是全球最权威的竞技编程平台,其评分系统基于数千道算法竞赛题目,能精准衡量模型在数据结构、动态规划、图论等复杂算法上的推理能力;Pass@k是一种统计指标,Pass@1表示单次生成即通过测试的概率,Pass@4则允许4次尝试,更能反映模型的潜在能力上限;SWE-Bench(Software Engineering Benchmark)则更贴近真实工程场景,要求模型解决来自GitHub真实仓库的Issue,涵盖代码理解、定位Bug、生成补丁等完整软件工程流程,被认为是目前最能反映实际开发能力的基准之一。
- Pass@1 Codeforces:o1和o1 pro得分非常接近
- Codeforces评分:o1的得分远低于o3-mini-high
- Pass@4通过率:o1 pro明显优于o1(同一问题测试4次的通过率)
- SWE-Bench评分:o1得分远高于o3-mini medium,但略低于o3-mini-high
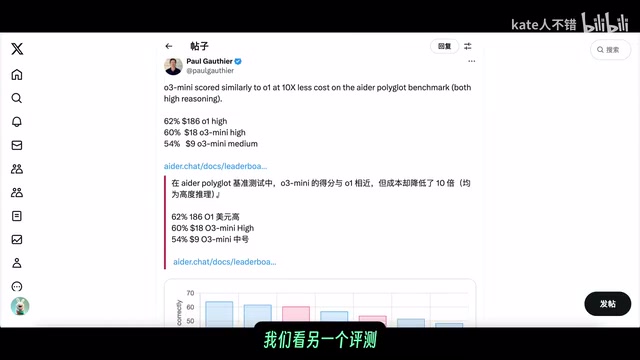
在AID基准测试中,o1 high(对应o1 pro)的编程能力得分超过60,优于o3-mini-high,但两者非常接近。这些数据为Deep Research的分析提供了重要参考。
Deep Research对三个模型的整体评估
三模型定位差异
Deep Research对三个模型给出了清晰的定位:
- o3-mini-high:尽管规模更小,但经过强化推理训练,在需要推理的工程任务上智力已接近o1
- o1 pro:由于计算投入更大,可能给出更详尽的方案
- Web开发方面:三者都能胜任,对于明确且单一的任务都能给出高质量解决方案
o3-mini-high之所以能以较小规模实现接近o1的推理能力,核心在于OpenAI采用的**强化学习推理训练(Reinforcement Learning for Reasoning)**范式。与传统的监督微调不同,这种方法让模型通过大量试错来学习「如何思考」,而非直接学习「答案是什么」。模型在推理时会生成一条内部的「思维链」(Chain of Thought),在给出最终答案前进行多步骤的自我验证。「high」后缀表示在推理时使用了更高的计算配额(compute budget),允许模型进行更长的思维链推导,这也是同一模型在不同配置下性能差异显著的根本原因。
关键结论是:对于多步骤复杂任务,o1 pro表现更好;而在数据库方面,o1 pro由于执行思考步骤更多,更有可能发现代码或查询中的潜在优化点。
代码生成质量对比
Deep Research的量化排序为:o1 pro ≈ o3-mini-high > o1
在可维护性方面,遇到复杂需求时o1 pro可能写出更健壮的代码,而o3-mini-high更倾向于简洁直观地完成任务,但差异很小。
代码优化能力
o3-mini-high掌握了优化算法的本领,能在需要时写出高效解法。综合排序为:o1 pro > o1 ≈ o3-mini-high
错误率与可靠性分析

Deep Research在错误率分析中给出了一个非常实用的建议:为了保险起见,开发实践中用户应尽量将需求拆解清晰,或一步步验证模型输出,减少推理误差偏差导致的逻辑错误。
综合评估:
- o1 pro:最为可靠
- o1:紧随其后
- o3-mini-high:尽管体积小但可靠性接近o1
实际编程案例的深度洞察
o1模型的"双刃剑"效应

Deep Research引用了一个有趣的案例:o1在某个任务中最终分数低于Claude 3.5。报告分析认为,这凸显了o1模型的"双刃剑"特性——深度推理让它在明确任务上表现卓越,但对复杂指令的鲁棒性需要提升。
这一现象在AI可靠性研究领域有更深层的技术解释,本质上是**过度推理(Over-reasoning)与指令跟随(Instruction Following)**之间的张力。强推理模型在接收到复杂指令时,会构建一个内部的「问题模型」,一旦这个模型在初始阶段出现偏差,后续的推理步骤反而会以极高的「置信度」沿着错误路径深入,形成所谓的「推理惯性」——一旦漏掉某个细节,推理过程可能不会自动校正,反而坚定地朝错误方向进行。相比之下,Claude 3.5等模型采用了更保守的生成策略,在不确定时倾向于寻求澄清而非自主推断,虽然单项能力弱一点,但有时不做过多推理反而避免了误区。
关键启示:当让模型一次性生成大型复杂应用时,最好明确列出需求清单并逐一确认模型产出,或者将任务分解为多次对话完成。这也是为什么业界越来越重视「需求工程」(Prompt Engineering)——对于强推理模型,清晰、原子化的指令比模糊的高层描述更能发挥其潜力,同时弥补其在复杂指令上的可能疏漏。
o3-mini-high的亮眼表现
社区中流行的100个彩色小球在球体内弹跳的Python脚本测试中,o3-mini-high给出的解决方法完美满足了提示中的每一项要求。此外,在经典算法题上,o3-mini给出了简洁又巧妙的解法,比常规GPT写出的代码运行速度快很多。
代码调试与错误修复能力对比

Deep Research指出,在真实软件工程中编写代码只是第一步,调试和修复错误同样关键:
- o1:能有效定位问题并给出正确修改
- o3-mini-high:修复了39%的错误;如果允许调用内部工具(运行代码、查看报错),成功率飙升到61%
这一跃升背后是**代码执行反馈循环(Code Execution Feedback Loop)**的力量。当模型被允许调用工具时,它不再仅凭静态代码分析来判断问题,而是通过实际运行获取运行时信息(如堆栈跟踪、变量状态),再据此调整修复策略——这种「执行-观察-修正」的闭环模式被称为「代码代理」(Code Agent),与人类程序员的调试习惯高度一致。目前,GitHub Copilot、Cursor等主流AI编程工具都在积极集成这种能力,被认为是下一代AI编程助手的核心竞争力所在。
报告特别强调:安全相关的错误有时不会体现在简单的测试用例里,模型可能不易察觉。这时人与模型的结合依旧非常重要——人提供高层次的指导,模型执行具体的调试步骤,双方配合可以将错误率降到最低。
最终结论与模型选择建议
Deep Research基于权威基准和案例分析,给出了量化总结:
| 维度 | 排序 |
|---|---|
| 整体编程能力 | o1 pro > o1 ≈ o3-mini-high |
| 代码生成质量 | o1 pro > o1 ≈ o3-mini-high |
| 优化调优 | o1 pro最优 |
| 错误率 | o1 pro最可靠 > o1 > o3-mini-high |
不同场景的选择建议:
- o3-mini-high:胜在速度和成本,适合高频次编程问答和一般开发任务
- o1:提供更全面的推理支持,在复杂任务上更稳健
- o1 pro:面向准确性要求极高的专业场景
对Deep Research功能的评价
这个案例充分展示了Deep Research的价值——它不是简单的信息堆砌,而是能够综合多个数据源进行交叉分析,提出有深度的洞察。比如"双刃剑"效应的分析、人机协作调试的建议等,都是能促进开发者思考的有价值观点。
虽然部分信息未能充分检索(如某些具体分数),但在9分钟内完成如此深度的技术对比报告,这本身就是AI辅助研究的一个里程碑式体验。
核心要点
- Deep Research在9分钟内完成了o1、o1 pro和o3-mini-high三个模型编程能力的系统对比分析
- o1 pro在多步骤复杂任务、代码质量和错误率方面均表现最优,但成本最高
- o3-mini-high以小模型实现了接近o1的编程能力,在速度和成本上具有极大优势
- o1模型存在"双刃剑"效应:深度推理在明确任务上卓越,但对复杂指令的鲁棒性需要提升
- Deep Research的核心价值在于善于提出有用的分析和观点,而非简单的信息检索
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。