DeepSeek V4+Claude Code写UI自动化测试:11个用例仅花5毛7
用DeepSeek V4 Pro写UI自动化测试,每个用例仅需五分钱。
作者使用DeepSeek V4 Pro搭配Claude Code和Playwright,对笔记软件Memo从零编写UI自动化测试。12分钟生成11个用例,4分钟完成Page Object重构,总费用仅0.57元,每个用例约5分钱。AI在标准表单测试等场景表现良好,但在架构设计合理性上仍需人工把关,推荐采用AI生成初稿、人工审查优化的协作模式。
用国产大模型写UI自动化测试,真实成本到底多少?
DeepSeek V4 Pro 近期推出了极具竞争力的优惠价格,不少开发者和测试工程师开始琢磨:拿国产大模型来写 UI 自动化测试,实际成本到底是多少?到底是营销噱头,还是真能在项目里落地?
本文基于一个真实项目——笔记软件 Memo,使用 DeepSeek V4 Pro 搭配 Claude Code 和 Playwright CLI,从零开始编写 UI 自动化测试用例,完整记录整个过程的效果与花费。
环境搭建与工具配置
核心工具链
整个实验的技术栈非常清晰:
- AI Agent 编程工具:Claude Code(简称 CC)
- 模型:DeepSeek V4 Pro(通过 CC Switch 插件切换)
- 测试框架:Pytest + Playwright CLI
- 被测项目:Memo 笔记软件(本地运行在 localhost:5230)
Claude Code 是 Anthropic 推出的命令行 AI 编程助手,它能够直接在终端中读取项目文件、执行命令、编写和修改代码。与传统的 IDE 插件不同,Claude Code 以 Agent 模式运行,具备自主规划、执行和验证的能力。CC Switch 是社区开发的一个配置工具,允许用户将 Claude Code 的底层模型从默认的 Claude 系列切换为其他兼容 API 的大模型(如 DeepSeek、GPT-4o 等),本质上是通过修改 API endpoint 和模型参数实现的。这种灵活性使得开发者可以在保留 Claude Code 强大的 Agent 框架和工具调用能力的同时,选择性价比更高或特定任务表现更好的模型。
首先需要配置 CC Switch,将模型指向 DeepSeek V4 Pro,然后创建一个空文件夹作为项目根目录,安装好 Playwright CLI 的 Skill。
Playwright 是微软开源的端到端测试框架,支持 Chromium、Firefox 和 WebKit 三大浏览器引擎。与 Selenium 相比,Playwright 具备自动等待机制、网络拦截、多标签页支持等现代特性,且其选择器引擎支持 CSS、XPath、文本内容等多种定位方式。Playwright CLI 提供了代码生成(codegen)、截图、PDF 导出等功能,其中 codegen 模式可以录制用户操作并自动生成测试代码。在本实验中,AI Agent 利用 Playwright 的 Skill(即预定义的工具调用能力)来访问页面、获取 DOM 结构、执行交互操作,这比单纯依赖截图理解页面要精确得多。Pytest 作为 Python 生态中最流行的测试框架,其 fixture 机制和参数化能力与 Playwright 的 Python 绑定配合良好。
提示词设计要点
提示词的设计直接影响自动化测试用例的质量,核心要求包括:
- 使用 Playwright CLI Skill 测试 localhost:5230 的注册和登录功能
- 采用 Pytest 框架
- 用例完成后自动运行两遍,确保稳定性
- 每个用例必须包含断言——没有断言的测试用例毫无意义
关于断言的要求值得展开说明。在自动化测试中,断言(Assertion)是验证被测系统行为是否符合预期的核心机制。没有断言的测试用例被业界称为"无效测试"或"快乐路径测试"——它只能证明程序没有崩溃,却无法验证功能是否正确。有效的断言应该覆盖多个维度:页面元素的可见性、文本内容的正确性、URL 的跳转、网络请求的响应状态等。在 Playwright 中,推荐使用 expect() API 进行断言,它内置了自动重试和超时机制,能够处理异步渲染带来的时序问题。AI 生成的断言质量是评估其测试代码实用性的关键指标——过于宽泛的断言(如只检查页面是否加载)几乎没有价值,而过于具体的断言(如检查某个动态生成的 ID)则会导致用例脆弱。
值得一提的是,整个过程采用了"一把梭"模式——全程无需人工干预,完全交给 AI 自主完成。所谓"一把梭"模式,是指 AI Agent 在接收到初始指令后,自主完成从分析、编码、调试到验证的完整闭环,中间无需人工介入。这种模式的实现依赖于 Agent 框架的几个关键能力:工具调用(Tool Use)——Agent 能够执行终端命令、读写文件、访问网页;自我纠错(Self-correction)——当测试运行失败时,Agent 能分析错误信息并修改代码;规划能力(Planning)——Agent 能将复杂任务分解为可执行的步骤序列。这与传统的代码补全(如 Copilot)有本质区别:补全工具是被动响应,而 Agent 是主动规划和执行。
第一轮:12分钟自动生成11个UI自动化测试用例
执行过程
启动后,DeepSeek V4 Pro 开始自动分析被测页面、编写 Playwright 测试代码、运行调试。整个过程耗时 12 分 11 秒,最终生成了 11 个测试用例,并且稳定通过了两轮运行。
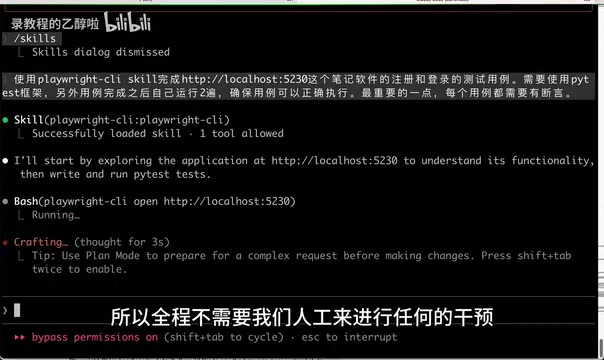
初版代码的典型问题
初版代码的质量只能说"能跑但不够优雅",具体表现为:
- 没有使用 Page Object 模式,代码基本是流水账式的写法
- 页面元素定位、操作步骤都直接写在测试方法里
- 可维护性和复用性较差
这其实在意料之中——AI 在没有明确架构要求的情况下,往往会选择最直接的实现方式。
第二轮:不到4分钟重构为Page Object模式
3分53秒完成PO模式重构
接下来让 Claude Code 将所有用例重构为 Page Object 模式。Page Object Model(POM)是 UI 自动化测试中最经典的设计模式之一,由 Selenium 项目的核心贡献者 Simon Stewart 提出。其核心思想是将页面的元素定位和操作封装为独立的类(Page Object),测试用例只调用这些类提供的方法,而不直接操作页面元素。这种分离带来三个关键优势:一是当 UI 发生变化时,只需修改对应的 Page Object 而非所有相关用例;二是测试代码的可读性大幅提升,测试方法读起来更像业务描述;三是促进代码复用,多个测试用例可以共享同一个 Page Object。
这一次效率更高,仅用 3 分 53 秒 就完成了重构,所有 UI 自动化测试用例运行通过。
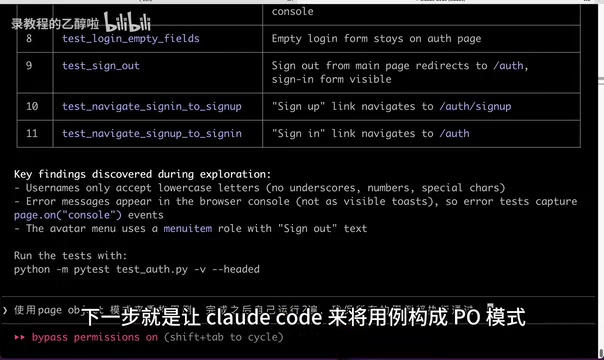
手动验证后确认:
- ✅ 页面对象和测试逻辑分离,确实采用了 Page Object 模式
- ✅ 每个用例都包含断言
- ✅ 所有用例稳定通过
仍存在的小问题
不过也发现了一个细节:注册和登录实际上是同一个页面的不同状态,但 DeepSeek V4 Pro 将它们拆分成了两个独立的 Page Object,导致代码略显臃肿,存在一定的重复。
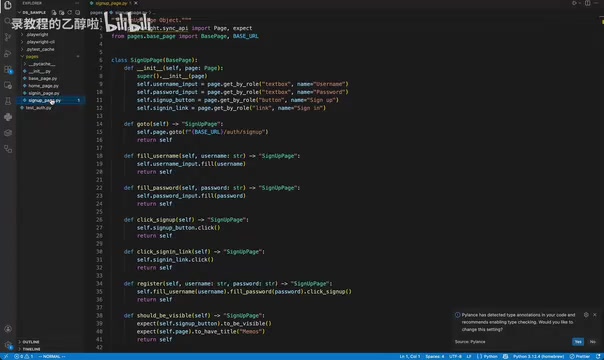
这类问题反映出 AI 在理解业务逻辑层面仍有局限——它能准确地完成功能实现,但在架构设计的"合理性"上还需要人工把关。在实际项目中,Page Object 的粒度划分是一个需要经验判断的问题——过细会导致类爆炸,过粗则失去封装意义。AI 目前缺乏对页面状态关系的深层理解,容易将视觉上的"两个功能"机械地映射为"两个对象",而忽略它们在 DOM 层面可能共享大量元素和交互逻辑。
成本拆解:一个UI自动化用例只要五分钱
这是大家最关心的部分。整个实验的费用明细如下:
| 阶段 | 耗时 | 用例数 | 费用 |
|---|---|---|---|
| 用例生成 | 12分11秒 | 11个 | — |
| PO重构 | 3分53秒 | 11个 | — |
| 合计 | 约16分钟 | 11个 | 0.57元 |
换算下来,每个用例的成本约为 0.05 元(五分钱)。
DeepSeek V4 Pro 采用按 Token 计费的模式,其定价在国产大模型中处于极具竞争力的位置。作为参考,GPT-4o 的输入价格约为每百万 Token 2.5 美元,Claude 3.5 Sonnet 约为 3 美元,而 DeepSeek V4 Pro 的价格远低于这些国际主流模型。值得注意的是,AI 编程 Agent 的实际 Token 消耗往往远超用户的直觉——一次看似简单的任务可能涉及数十次工具调用、上下文传递和代码生成,累计消耗数万甚至数十万 Token。本实验 0.57 元的总成本对应的 Token 量,如果使用 GPT-4o 可能需要数十元。
这个数字意味着什么?假设一个中等规模的 Web 项目需要 200 个 UI 自动化测试用例,按这个单价估算,AI 生成的总成本大约在 10 元左右。即便算上后续的调试、优化和人工审查时间,这个成本也远低于纯人工编写的时间投入。
实践总结与适用建议
哪些场景适合用AI写UI自动化测试
从本次实验来看,DeepSeek V4 Pro + Claude Code + Playwright 的组合在以下场景表现不错:
- 标准化的表单测试(注册、登录、搜索等)
- CRUD 操作的基础覆盖
- 快速生成测试骨架,再由人工优化细节
当前局限
- AI 对页面结构的理解可能不够精准,Page Object 划分不一定合理
- 复杂交互场景(拖拽、多步骤流程)的用例质量有待验证
- 仍需人工 Review 代码质量和断言的有效性
推荐的人机协作工作流
- 先让 AI 生成基础用例(一把梭模式)
- 再让 AI 重构为 Page Object 模式(分步优化)
- 人工审查架构合理性和断言覆盖度
- 持续迭代,将审查反馈作为新的提示词输入
这种分步工作流的设计思路,本质上是在利用 AI 的高速生成能力与人类的架构判断能力形成互补。当前阶段,AI 在"从 0 到 1"的代码生成和"从 1 到 1.5"的模式重构上效率极高,但"从 1.5 到 2"的精细化优化仍然依赖人类工程师的经验和业务理解。随着模型能力的持续提升和上下文窗口的扩大,这个人机协作的边界会不断向 AI 一侧移动。
写在最后
五分钱一个 UI 自动化用例,16 分钟从零到稳定运行——这在一年前几乎不可想象。虽然 AI 生成的自动化测试代码还做不到开箱即用的完美,但作为"初稿生成器",它已经能显著提升测试工程师的工作效率。
关键不在于 AI 能否替代人,而在于我们能否找到人机协作的最佳平衡点。从成本角度看,DeepSeek V4 Pro 的定价确实让 AI 辅助 UI 自动化测试变得触手可及。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。