DeepSeek V4 Pro深度评测:性能媲美GPT-5.5,成本仅1/12
引言
DeepSeek 在上周五发布了两款新模型——DeepSeek V4 Pro 和 DeepSeek V4 Flash。作为凭借R1模型引发开源大模型革命的中国AI公司,DeepSeek这次再度证明:开源模型不仅能在性能上逼近甚至超越闭源模型,还能以极低的成本实现这一切。
开源大模型与闭源大模型之间的竞争是当前AI行业最重要的叙事之一。闭源模型(如OpenAI的GPT系列、Anthropic的Claude系列)通常由资金雄厚的公司开发,不公开模型权重,用户只能通过API付费调用。开源模型(如DeepSeek、Meta的Llama系列)则公开模型权重,允许开发者自由下载、部署和微调。开源模型的核心优势在于:企业可以在自有服务器上部署以保障数据隐私,可以根据特定需求进行微调,且不受单一供应商的定价策略和服务条款约束。DeepSeek的崛起尤其具有标志性意义——它证明了中国团队能够以相对较低的成本训练出世界顶级水平的开源模型,打破了此前"只有硅谷巨头才能训练顶级模型"的行业认知。
本文将从基准测试、定价对比和实际使用三个维度,全面解析DeepSeek V4 Pro的真实表现。
DeepSeek V4 Pro基准测试:全面对标顶级闭源模型
DeepSeek V4 Pro延续了混合专家(Mixture of Experts, MoE)架构——模型参数量巨大,但每次请求只激活其中一部分参数,从而在保持高性能的同时大幅提升推理速度。
MoE架构是当前大模型领域最重要的架构创新之一。传统的密集(Dense)模型在每次推理时会激活所有参数,计算成本与参数量成正比。而MoE架构通过引入一个"门控网络"(Gating Network),在每次前向传播时只选择性地激活一部分"专家"子网络。例如,一个拥有6000亿参数的MoE模型,每次推理可能只激活其中的370亿参数。这意味着模型可以拥有巨大的知识容量(由总参数量决定),同时保持较低的计算成本(由激活参数量决定)。DeepSeek从V2开始就在MoE架构上进行了深度优化,包括其独创的DeepSeekMoE细粒度专家分配策略和Multi-head Latent Attention(MLA)机制,后者通过压缩KV缓存大幅降低了推理时的显存占用,这也是DeepSeek能够以极低成本提供高性能推理服务的技术基础。
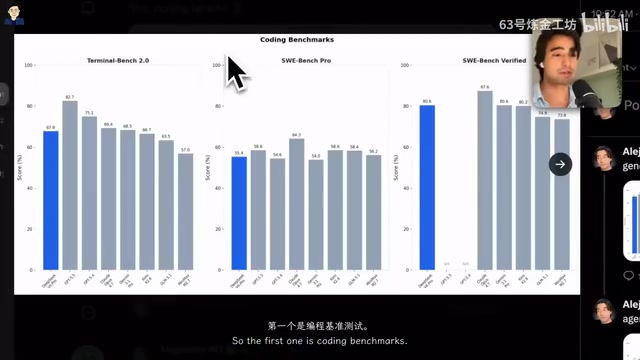
编程能力:SweetBench Pro得分超越GPT 5.4
在编程领域,DeepSeek V4 Pro的表现令人印象深刻:
- Terminal Bench(终端操作能力):与Claude Opus 4.7和Gemini 3.1 Pro处于同一水平,略高于Kimi K2.6、GLM 5.1和Minimax M2.7等开源模型
- SweetBench Pro(GitHub Issue解决能力):得分甚至超过GPT 5.4,仅略低于GPT 5.5和Claude Opus 4.7
SweetBench Pro(也常写作SWE-bench)是由普林斯顿大学研究团队推出的编程能力基准测试,它从真实的GitHub开源项目中提取实际的Issue和对应的Pull Request,要求AI模型在理解问题描述后,自主定位相关代码文件、理解代码上下文,并生成正确的补丁来解决问题。与传统的编程基准(如HumanEval、MBPP)只测试单函数生成能力不同,SweetBench Pro要求模型具备跨文件推理、理解项目架构、处理依赖关系等真实软件工程能力,因此被业界视为衡量AI编程实力最具参考价值的基准之一。DeepSeek V4 Pro在这项测试中的优异表现,说明它已经具备了处理真实工程问题的能力。
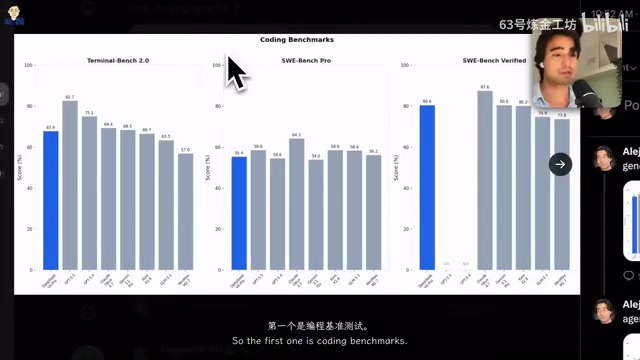
通用推理能力:GPQA与Humanity's Last Exam表现
在非编程领域的推理能力测试中:
- GPQA Diamond 和 MMLU Pro:DeepSeek V4 Pro仅略低于顶级闭源模型,与Kimi K2.6基本持平
- Humanity's Last Exam(人类最后的考试):这是一个由各领域顶级专家出题的超高难度基准,涵盖古典学、生态学、数学、计算机科学、语言学、化学等学科。DeepSeek V4 Pro得分37.7,略高于Kimi,但低于其他SOTA模型
GPQA(Graduate-Level Google-Proof Questions and Answers)是由纽约大学等机构推出的研究生级别推理基准。其中Diamond子集是经过最严格筛选的题目——每道题都要求领域专家花费大量时间才能回答,且非专业人士即使借助搜索引擎也难以找到答案。GPQA Diamond涵盖物理、化学、生物等自然科学领域的深度推理问题,是衡量模型在专业学术领域推理深度的重要指标。MMLU Pro则是经典MMLU基准的升级版,增加了更多需要多步推理的复杂题目,减少了通过猜测就能答对的简单选择题。
说个细节,Humanity's Last Exam的难度远超其他基准——大多数模型在其他测试中能达到90/100的水平,但在这个基准上表现普遍较差,这使得各模型之间的差距更具参考价值。
Agent能力:工具调用与多步骤任务执行
AI Agent(智能体)是当前大模型应用的核心发展方向之一。与传统的问答模式不同,Agent能够自主规划任务步骤、调用外部工具(如搜索引擎、代码执行器、API接口等)、根据中间结果动态调整策略,最终完成复杂的多步骤任务。在衡量这一关键能力的Agent基准中,DeepSeek V4 Pro表现尤为亮眼:
- MCP Atlas 和 Toolethlon:得分超过GPT 5.4、Gemini 3.1 Pro和Kimi K2.6,仅次于GPT 5.5和Claude Opus 4.7
- BrowseComp(多网站信息检索能力):接近GPT 5.5和Gemini 3.1 Pro的水平,甚至超过了Claude Opus 4.7
这里值得解释的是,MCP(Model Context Protocol)是Anthropic提出的模型上下文协议,旨在标准化AI模型与外部工具和数据源之间的交互方式,可以理解为AI世界的"USB-C接口"。BrowseComp则测试模型在多个网站间检索、整合信息的能力,模拟真实的研究和调查场景。这些Agent基准的重要性在于,它们直接反映了模型在实际生产环境中自主完成复杂任务的能力——这也是企业最关心的应用场景。
综合来看,DeepSeek V4 Pro在大多数场景下优于GPT 5.4,略低于GPT 5.5——而GPT 5.4本身已经是一个非常优秀的模型。
DeepSeek V4 Pro定价:开源模型的极致性价比
性能对标顶级闭源模型,但价格却天差地别:
| 模型 | 输入价格(每百万token) | 输出价格(每百万token) |
|---|---|---|
| DeepSeek V4 Pro | $1.74 | $3.48 |
| GPT 5.5 | 约$20+ | 约$40+ |
| Claude Opus 4.7 | 约$15+ | 约$75+ |
DeepSeek V4 Pro的价格大约是GPT 5.5的 1/12,是Claude Opus 4.7的更小比例。更令人惊喜的是,DeepSeek目前还在进行75%折扣的促销活动(截至5月5日),使用成本进一步降低到令人难以置信的水平。
这种极致的性价比背后,是DeepSeek在工程优化上的深厚积累。MoE架构本身就大幅降低了每次推理的计算量,再加上MLA机制对显存的高效利用、FP8混合精度训练等技术手段,使得DeepSeek能够在相同的硬件资源上服务更多的并发请求,从而将成本优势传递给终端用户。
对于高频调用API的开发者和企业来说,这意味着每月可以节省数千甚至数万美元的推理费用。
实战演示:通过Pi Agent使用DeepSeek V4 Pro
Pi Agent简介
Pi是一个极简主义的Agent框架,可以理解为OpenCode的精简版本。它不仅是一个编码助手,还是一个SDK,可以为应用程序赋予Agent能力。
安装非常简单,只需一行命令即可完成。Pi的设计哲学是开箱即用功能精简,但你可以让Pi自己为自己实现新功能——这本身就是对AI编程能力的一种优雅展示。这种"自举"(bootstrapping)的设计理念在开发者工具中越来越常见,它既降低了工具本身的维护复杂度,又为用户提供了极高的可定制性。
如何配置DeepSeek V4 Pro API
有两种方式接入DeepSeek V4 Pro:
- 官方API:访问deepseek.com,创建账户并充值,获取API密钥
- HuggingFace推理提供商:通过HuggingFace的inference providers间接调用
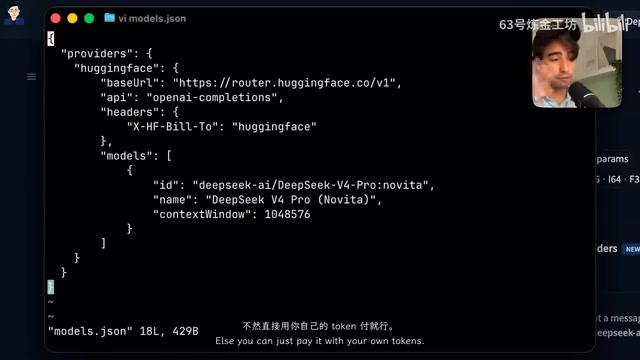
通过编辑Pi的models.json配置文件,添加HuggingFace提供商信息和模型ID,即可在Pi中使用DeepSeek V4 Pro。该模型支持百万token的上下文窗口,这对于处理大型代码库非常有利。
百万token的上下文窗口意味着模型可以一次性读取并理解约75万个英文单词或数十万行代码。对于软件开发场景,这意味着开发者可以将整个中大型项目的代码库一次性输入模型,让模型在充分理解项目全貌的基础上进行代码生成、Bug修复或架构重构。相比之下,早期的GPT-3.5仅支持4K token的上下文窗口,处理稍大的文件就需要分段输入,严重限制了实际应用场景。百万级上下文窗口的实现,得益于近年来在位置编码(如RoPE的外推技术)、注意力机制优化(如稀疏注意力、滑动窗口注意力)等方面的技术突破。
实际编码测试结果
在实际测试中,我们要求DeepSeek V4 Pro构建一个浏览器端的代码游乐场(类似CodeSandbox),包含HTML、CSS和JavaScript三个编辑器以及实时预览功能,并要求支持自动保存。
整个构建过程仅耗时约5分钟,最终产出的应用功能完整:编辑器响应式更新、实时预览正常工作、重置功能可用。虽然这只是一个简单的演示,但结合前面的基准测试数据,足以说明DeepSeek V4 Pro在实际开发场景中的可用性。
总结:DeepSeek V4 Pro值得切换吗?
DeepSeek V4 Pro的发布再次印证了一个趋势:开源模型正在以惊人的速度追赶闭源模型,不仅在质量上可比,成本更是仅为后者的一小部分。
对于通过API使用GPT 5.5或Claude Opus 4.7的开发者和企业来说,切换到DeepSeek V4 Pro是一个值得认真考虑的选择——你可以获得90%以上的性能,但只需支付不到10%的费用。当然,在做出切换决策时,还需要考虑一些实际因素:数据隐私政策(数据是否经过中国服务器)、API服务的稳定性和可用性、以及特定任务上的实际表现是否符合预期。建议在正式迁移前,先在自己的核心使用场景上进行充分的A/B测试。
如果你正在寻找一个兼顾性能与成本的AI模型方案,DeepSeek V4 Pro无疑是当前最具竞争力的选项之一。
核心要点
相关推荐

洛杉矶市长为何没有实权:一座被设计为反纽约的城市
洛杉矶市长为何在山火等危机中显得力不从心?这并非个人能力问题,而是源于一个多世纪前进步主义运动的极端去中心化制度设计。本文解析洛杉矶权力分散体制的历史根源与当代代价。
DeepSeek GUI桌面版:免费开源的Codex平替方案
实测DeepSeek GUI桌面版,一款免费开源的Codex平替工具。支持本地桌面智能体工作台,中文写作与代码生成能力出色,零门槛开箱即用,成本极低,是国内开发者和内容创作者的理想选择。
Loop Engineering从入门到精通:智能体循环开发全解析
深入解析Loop Engineering循环工程的核心概念,涵盖Agent Loop工作流程、代码实现(While循环与Graph图模式)、与Prompt Engineering的区别,帮助开发者掌握智能体循环机制的系统化设计方法。