DeepSeek V4 vs GLM-5.1编程实测:认证迁移、全栈开发谁更强

DeepSeek V4 Pro与智谱GLM-5.1在真实编程项目中的实测对比
本文通过真实编程项目和工作流Agent两类任务,对比测试了DeepSeek V4 Pro和智谱GLM-5.1的实际编程能力。在认证体系迁移任务中,GLM-5.1展现了自主进入计划模式、完整需求理解等优势,虽存在小瑕疵但整体优于DeepSeek V4 Pro出现的会话隔离等严重缺陷。
测试背景与方法论
在AI编程助手百花齐放的当下,模型的跑分成绩和实际项目表现往往存在巨大鸿沟。本次测试抛开参数对比,直接将DeepSeek V4 Pro和智谱GLM-5.1放入真实项目中进行实测,考察它们在长程编程任务和工作流Agent中的实际表现。
**长程编程任务(Long-horizon Coding Task)**是指需要模型在单次或多轮对话中持续追踪大量代码上下文、跨文件依赖关系和任务状态的编程场景。这类任务对模型的上下文窗口(Context Window)和注意力机制提出了极高要求。当前主流大模型的上下文窗口普遍在32K到200K Token之间,但窗口大小并不等于有效利用率——研究表明,许多模型在上下文超过一定长度后会出现"中间遗忘"现象(Lost in the Middle),即对位于上下文中段的信息处理能力显著下降。
**工作流Agent(Workflow Agent)**则是一种将大语言模型与外部工具链串联的自动化执行架构。其核心技术是Function Calling(函数调用)或Tool Use机制——模型在推理过程中输出结构化的工具调用指令,由宿主程序执行后将结果回传给模型,形成"推理→执行→观察→再推理"的闭环。
测试设计了两类任务:
- 真实编程项目:包含用户认证体系迁移、CLI转Web全栈开发
- 自媒体内容分析Agent:视频下载、音频提取、转录分析的完整工作流
所有测试使用相同的提示词、相同的项目基础,确保对比的公平性。最终代码还会提交给GPT-5.5和Claude Opus 4.7进行独立Review评分。
编程项目实测一:认证体系迁移
任务难度分析
第一个项目是图片生成Agent的用户认证体系迁移,需要从另一个项目中将已有的认证代码迁移过来。这个任务涉及后端、前端和数据库三个层面,同时需要跨项目探索代码结构,对模型的长程处理能力要求极高。认证体系迁移尤为典型:模型需要同时理解源项目结构、目标项目结构、数据库Schema变更、前后端接口协议等多维信息,任何一个环节的上下文丢失都可能导致代码逻辑断裂或安全漏洞。
在上期测试中,DeepSeek V4在这个项目上仅获得7.0分(满分10分),而GPT-5.5获得了8.5分。
GLM-5.1的表现亮点
智谱GLM-5.1在接收到任务后,展现了几个值得注意的特点:
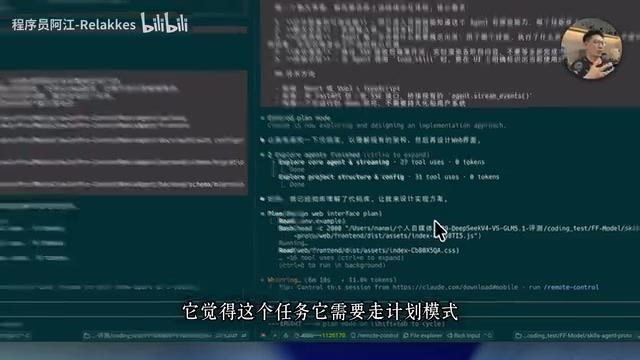
- 自主进入计划模式:模型在探索完项目后,主动判断任务复杂度并切换到计划模式,说明它对任务难度有准确的评估能力。这一行为背后对应的是思维链(Chain-of-Thought, CoT)和任务分解(Task Decomposition)技术——计划模式意味着模型在正式生成代码前,会先输出结构化的执行计划,列举子任务、识别依赖关系、预判潜在风险点。这与OpenAI o系列和DeepSeek R系列所采用的"慢思考"(Slow Thinking)范式一脉相承。研究表明,对于需要多步骤规划的任务,显式的计划生成可以将最终代码的正确率提升15%至30%。模型能够自主判断何时需要进入计划模式,本身也是元认知能力(Metacognition)的体现。
- 完整的需求理解:一次性接收并完成了落地页的需求,而DeepSeek V4 Pro在首轮对话中遗漏了落地页
- 任务描述更清晰:相比DeepSeek V4 Pro,GLM-5.1的任务分解描述更加规范
整个认证迁移任务GLM-5.1耗时约50分钟完成,代码改动涉及前后端多个文件。
功能验证结果
实测登录功能时,GLM-5.1完成的版本支持Google和GitHub登录(均基于OAuth 2.0协议实现身份验证),均能正常进入图片生成Agent后台。但存在一个小问题:左侧栏未能正确拉取用户头像和历程信息。
相比之下,DeepSeek V4 Pro在上期测试中暴露了更严重的问题——聊天记录未与用户体系绑定,导致不同用户的聊天记录会串联。这是一类典型的会话隔离(Session Isolation)缺陷,在Web应用安全领域属于访问控制(Access Control)漏洞,严重时可被归类为OWASP Top 10中的"Broken Access Control
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。