DeepSeek V4 vs Qwen3.6实测:8大类150场景深度对比评测
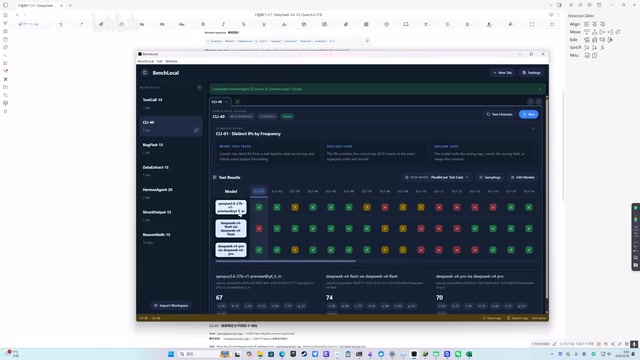
BenchLocal工具实测DeepSeek V4与Qwen3.6四模型,V4 Pro以691分领跑。
使用开源测评工具BenchLocal,对DeepSeek V4 Pro、V4 Flash和Qwen3.6 27B(Q4/Q6量化)四个模型进行85个日常场景的全面横评。V4 Pro以691分领先,但优势仅约6%。测试发现量化精度对工具调用影响显著,但在代码找Bug等任务中出现Q4反超Q6的"量化反转"现象,且V4 Flash在命令行测试中表现最佳,说明模型大小并非决定一切。
前言:一次更严谨的大模型实测
大模型之间的对比测评一直是社区热议话题。这次测评使用了GitHub上的专业测试工具 BenchLocal,覆盖8大测试类别、85个日常场景、12种工具调用,对 DeepSeek V4 Pro、V4 Flash 以及 Qwen3.6 27B(Q4/Q6两种量化精度)共四个模型进行了全面横评。
与学术跑分不同,这套测评工具聚焦于日常使用场景——工具调用、命令行操作、Bug查找、指令遵循、结构化输出、智能体引擎、推理数学、数据提取等,力求反映用户真实使用体验。
测评方法与设计理念
测试工具:BenchLocal
BenchLocal 是一个开源的本地化大模型测评工具,核心设计理念是贴近日常工作场景。以 ToolCore15 测试为例,第一道题就是"柏林现在天气怎么样?"——考验的不是模型的知识储备,而是它能否正确调用 GetWeather 接口获取实时天气数据。
**工具调用(Function Calling / Tool Use)**是现代大模型的核心能力之一,允许模型在推理过程中识别何时需要调用外部API或函数,并生成结构化的调用参数。其技术实现通常基于特殊的系统提示词模板,模型输出符合JSON Schema的函数调用请求,由外部运行时执行后将结果返回给模型继续推理。这一能力是构建AI Agent(智能体)的基础——没有可靠的工具调用,智能体就无法与真实世界交互。OpenAI在2023年率先将Function Calling标准化,此后成为行业事实标准,各主流模型均已支持。
评分标准简洁务实:
- 满分:正确调用工具链并返回准确结果
- 半分:部分调用成功但结果不完整
- 零分:未调用任何工具直接编造答案(即"幻觉")
可复现性保障
测评结果具备可复现性。比如 Qwen3.6 27B 在某些测试项中未通过的题目,第二次测试依然无法通过,杜绝了造假的可能性。任何人都可以用同一工具验证结果。
模型配置一览
- DeepSeek V4 Pro / V4 Flash:通过 API Key 调用,开启思考模式
- Qwen3.6 27B Q4:本地部署,Q4量化精度
- Qwen3.6 27B Q6:本地部署,Q6量化精度(因Q4成绩偏低而补测)
关于量化精度:大模型量化(Quantization)是将模型权重从高精度浮点数(如FP16/BF16)压缩为低比特整数表示的技术。Q4表示每个权重用4位整数存储,Q6则使用6位。量化的核心权衡是:精度越低,模型体积越小、推理速度越快、显存占用越少,但信息损失也越大。以27B参数模型为例,FP16完整精度约需54GB显存,Q4量化后约需14-16GB,Q6约需20-22GB,使得消费级GPU(如RTX 4090的24GB显存)得以运行。目前本地部署最主流的量化格式是GGUF,由llama.cpp项目推广,支持CPU+GPU混合推理。
总分对比:V4 Pro领跑但优势有限

最终的总分排名如下:
| 排名 | 模型 | 总分 | 相对基准 |
|---|---|---|---|
| 1 | DeepSeek V4 Pro | 691 | +6.3% |
| 2 | DeepSeek V4 Flash | 676 | +4.0% |
| 3 | Qwen3.6 27B Q6 | 670 | +3.0% |
| 4 | Qwen3.6 27B Q4 | 650 | 基准 |
以 Q4 精度的 Qwen3.6 27B 为基准,V4 Pro 领先约 6%,V4 Flash 领先约 4%,Q6 量化版领先约 3%。领先幅度并不算悬殊,但如果不是 V4 Pro 在推理数学项上意外翻车,其领先幅度可能超过 10%。
八大测试项逐项分析
1. ToolCore15:工具调用基础测试
Q4 量化的 27B 有两项未通过、一项半分,最终得 83 分;Q6 版本仅错一题,拿到 90 分。V4 Pro 也有一项小问题,疑似"想太多"导致失分。这项测试中,量化精度对工具调用能力影响显著——这与量化损失对模型格式化输出能力的破坏有直接关联,低比特量化在压缩权重时可能削弱模型对结构化输出格式的精确控制能力。
2. CLI40:命令行操作测试
难度比 ToolCore15 高出一个层级,40道题中即使是 V4 Pro 也错了 12 道。Q4 版本更是仅得 67 分。这项测试中表现最好的反而是 V4 Flash,说明参数量大不等于在所有场景都占优。这一现象在工程实践中并不罕见:较小的模型经过针对性优化后,在特定任务上往往能超越更大的通用模型。

3. BugFind:代码找Bug测试
出现了一个有趣的"量化反转"现象:Q4 精度得了 87 分,反而比 Q6 的 80 分更高,甚至超过了 V4 Flash。这说明量化过程对不同能力维度的影响并非线性的,低精度量化有时反而可能保留了某些特定能力。从信息论角度理解,量化相当于对权重空间施加了一种特殊的正则化,这种"有损压缩
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。