DeepSeek V4编码实测:榜单第一Kimi翻车,Claude稳居最强

AI编码模型榜单排名与真实项目表现存在巨大差距
一位开发者用四大AI编程模型(Claude Opus、DeepSeek V4、GPT、Kimi K2.6)完成同一全栈小游戏测试,结果与排行榜排名严重不符:榜单第一的Kimi K2.6全部失败,Claude Opus一次成功排名第一。这揭示了标准化基准评测与真实工程编码之间的巨大鸿沟,真实项目更考验架构能力、上下文理解和错误恢复。文章还解读了DeepSeek V4的核心技术创新。
榜单与实战的真实差距
选AI编码模型时,排行榜分数是最直观的参考依据。但榜单上的第一名,放到真实项目里就一定最强吗?
一位开发者用Claude Code对DeepSeek V4、GPT、Claude Opus和Kimi K2.6四个顶尖AI编程模型做了同场对比测试,让它们完成同一个完整的全栈小游戏——"云养猫系统"。结果出人意料:榜单排名第一的模型直接翻车,排名靠后的模型反而表现最稳。
这个测试揭示了一个关键事实:标准化基准评测和真实项目编码之间,存在巨大的鸿沟。
AI模型的标准化基准评测(Benchmark)通常采用HumanEval、MBPP、SWE-bench等测试集,这些测试集以孤立的编程题为主,考察模型能否在有限上下文中完成单一函数或算法实现。这类评测的优势在于可重复、可量化,便于横向比较;但其局限性同样明显——真实工程项目需要跨文件的上下文理解、多轮错误恢复、前后端协同设计以及对模糊需求的合理推断,这些能力在标准化题目中几乎无从体现。换句话说,基准评测更像是高考模拟题,而真实项目更像是一场没有标准答案的工程答辩。
测试设置与结果概览
任务描述
四个模型在同一套提示词下,需要完成一个功能完整的"云养猫"全栈小游戏,涵盖UI界面、交互动画、状态管理等多个维度的编码需求。技术栈有明确约束,任务文档详细规定了各项功能和特效要求。
最终排名
测试结果与各大排行榜形成了鲜明反差:
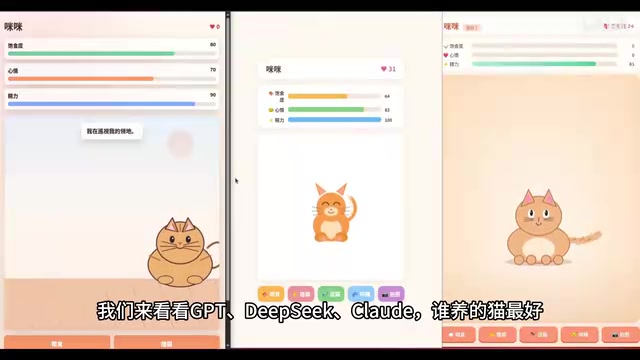
- Claude Opus:7分30秒一次成功,动画流畅、功能完整,排名第一
- DeepSeek V4 Pro:表现稳定,功能基本完整,部分动画存在短板
- GPT:布局传统,中规中矩,功能可正常运行
- Kimi K2.6:耗时22分钟以上反复重试,全部失败,未能生成可运行代码
说个细节,在Velse AI 4月23日的最新排名中,Kimi K2.6排第一,DeepSeek V4排第二,两者仅差0.07个百分点。在Coder Reina编码排行榜上,Kimi K2.6同样位居前列。然而在这个真实编码任务中,它一次都没跑通。
这说明了什么? 榜单衡量的是标准化小题的通过率,类似高考模拟题拿高分。但真实项目考验的是架构能力、上下文理解和错误恢复——这些恰恰是基准评测覆盖不到的。
四大模型实战编码细节对比
UI与布局设计差异
GPT的布局偏传统:上方显示猫名和爱心,三个进度条横排,下面一只橘猫配对话气泡,底部五个橘色按钮。整体像标准小游戏页面,功能齐全但缺乏亮点。
DeepSeek V4采用卡片式布局,居中白色卡片,猫闭眼微笑。进度条用了emoji图标(小鱼、笑脸、闪电),辨识度不错。不过页面留白过多,桌面端显得空旷。
Claude Opus最有设计感:猫名旁直接带状态标签,一眼就能看到猫的当前状态。猫的画面区域有大面积米色背景,猫画得较大且尾巴有花纹,按钮风格统一为圆角橘色,整体完成度最高。
交互动画表现对比
喂食环节是第一个分水岭:
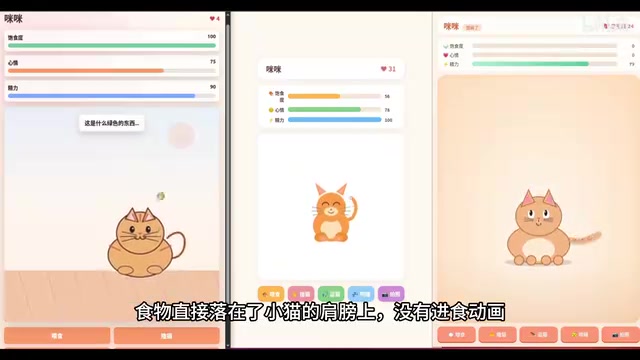
- GPT:点击喂食弹出三选一菜单,有食物评价和亲密度变化,但食物落在猫肩膀上,缺少进食动画
- DeepSeek V4:食物直接从猫身体穿过,动画存在明显穿帮
- Claude Opus:动画效果最好,有完整的进食特效,小猫眼睛还会追踪鼠标移动
逗猫环节最考验动画功力。任务要求鼠标变成逗猫棒,小猫要追着鼠标跑,并展现蹲伏、扭屁股、扑击的完整猫科动物狩猎动作。DeepSeek V4在这里表现不错,小猫可以上下左右移动,精力低于20时还会拒绝互动,逻辑处理到位。
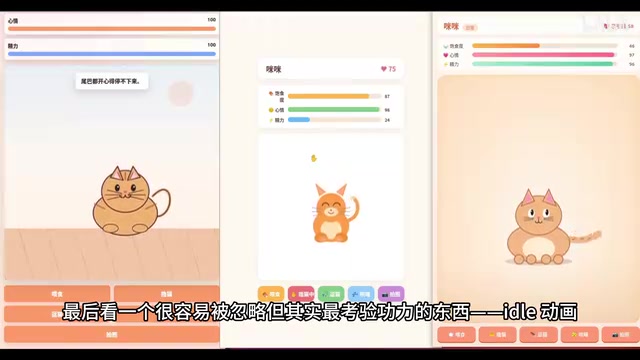
Idle动画:最考验AI编程功力的细节
任务要求三个持续动画:呼吸起伏、尾巴摇摆、每3-5秒眨一次眼。三个成功运行的模型都注意到了这些细节要求,但DeepSeek V4的小猫眼睛一直眯成一条缝,眨眼表现有所欠缺。
DeepSeek V4论文核心技术创新解读
虽然在动画细节上不是最优,但DeepSeek V4在复杂编码任务上的稳定性值得关注。这背后是论文中几项关键技术创新在支撑。
双模式注意力机制:支撑百万token长上下文
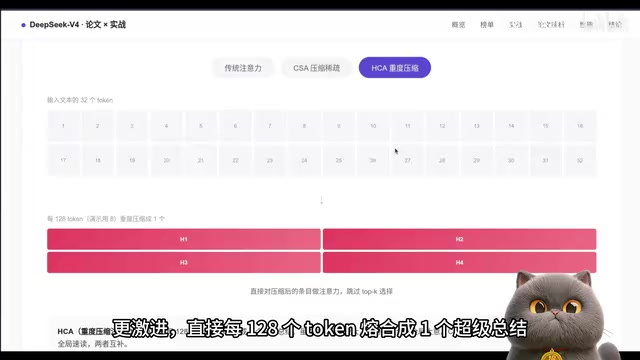
DeepSeek V4支持100万token的超长上下文,大约相当于十本《哈利波特与魔法石》或整部《三体》全集。理解这一突破,需要先了解其背后的计算瓶颈:标准Transformer的自注意力机制(Self-Attention)计算复杂度为O(n²),即序列长度翻倍,计算量变为四倍。对于100万token的超长上下文,朴素实现需要约10¹²次浮点运算,远超现有硬件的实时处理能力。为此,学界和工业界提出了多种改进方案,包括FlashAttention(分块计算减少显存读写)、Sliding Window Attention(局部窗口注意力)等。DeepSeek V4则采用了自研的分层压缩注意力策略,设计了两种注意力模式交替使用:
- CSA(压缩吸收注意力):每4个token打包成一个压缩条目,再从中挑选最相关的几个精读,计算量大幅下降
- HCA(重度压缩注意力):每128个token融合成一个超级总结,适合快速抓取全局大意
两者交替配合,局部精读加全局速读,互为补充。
MHC流形约束连接:深层网络的"稳压器"
这项技术给残差传递装了一个稳压装置,保证深层网络训练不会因信号逐层放大而崩溃。它解决了超大规模模型训练中长期存在的稳定性难题。在极深的神经网络中,梯度信号在反向传播过程中容易出现"梯度爆炸"或"梯度消失",流形约束通过将参数更新限制在特定几何流形上,使得信号传递更加平稳可控,是DeepSeek V4能够稳定训练至万亿参数规模的重要基础。
Muon优化器:首次在万亿参数MoE模型上验证
Muon(Momentum + Orthogonalization Update)优化器由Kosson等研究者提出,其核心改进在于对梯度更新矩阵进行正交化处理,使得每一步参数更新在参数空间中保持更好的方向性,避免了传统AdamW中常见的梯度方向退化问题。在中小规模模型上,Muon已被证明收敛速度更快、对学习率不那么敏感。DeepSeek V4将其首次应用于万亿参数量级的MoE(混合专家)模型——MoE架构将模型参数分成多个"专家"子网络,每次推理时由门控机制动态选择少数几个专家参与计算,在保持参数总量极大的同时控制实际计算量——在这一规模上验证Muon的可行性,是优化器工程领域的重要里程碑。
专家分训+在线蒸馏:避免多领域负迁移
知识蒸馏(Knowledge Distillation)最早由Hinton等人于2015年提出,核心思想是用大模型(教师)的输出软标签来指导小模型(学生)训练。在多领域联合训练中,负迁移(Negative Transfer)是一个长期难题——不同领域的数据分布差异较大,强行混合训练可能导致模型在某些领域性能下降。DeepSeek V4采用
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。