DeepSeek本地部署教程:Ollama一键安装运行指南
通过Ollama三步本地部署DeepSeek R1,告别官网卡顿
本文介绍如何使用Ollama开源框架在本地一键部署DeepSeek R1大模型。整个流程仅需三步:安装Ollama、选择合适的模型版本(推荐7B,需16GB内存+8GB显存)、执行一条命令即可完成部署。本地部署可解决官网卡顿排队问题,保障数据隐私,还可结合Open WebUI等工具实现图形界面和本地知识库功能。
想用DeepSeek却频繁遭遇官网卡顿、排队等待?本地部署是最佳解决方案。本文将手把手教你通过Ollama在本地部署DeepSeek R1,告别网络拥堵,10分钟实现私有化AI体验。
为什么要在本地部署DeepSeek?
DeepSeek R1作为国产顶级大模型,在春节期间已经刷屏全网。然而,官网的高并发访问导致响应缓慢、频繁断连,严重影响使用体验。将DeepSeek部署到本地,优势非常明显:
- 零延迟:无需排队,即问即答
- 数据隐私:所有对话数据留在本地,适合处理敏感信息
- 离线可用:不依赖网络,随时随地使用
- 可扩展性:后续可接入本地知识库,构建私域AI应用
而实现这一切的关键工具,就是Ollama——一个专为本地运行大语言模型设计的开源框架,支持一条命令完成模型的下载和启动。
Ollama诞生于2023年底,其核心价值在于将复杂的模型推理环境打包成单一可执行文件。底层基于llama.cpp引擎,后者通过C++实现了高效的量化推理,能在消费级CPU/GPU上运行原本需要数据中心级硬件的大模型。Ollama还内置了模型仓库管理、REST API服务和多模型并发调度能力,使其不仅适合个人使用,也可作为轻量级AI服务后端供开发者调用。
第一步:下载安装Ollama
Ollama的官方网站界面非常简洁,访问后直接点击"Download"按钮即可进入下载页面。
下载页面提供了macOS、Linux和Windows三个平台的安装包,根据自己的操作系统选择对应版本即可。以Windows为例,下载完成后会得到一个带有小羊驼图标的安装程序。
Ollama安装过程的注意事项
双击运行安装程序后,你会发现Ollama的安装流程异常简洁——没有任何可配置的选项,不需要选择安装路径、不需要勾选组件,只需点击安装然后等待完成。
由于Ollama程序体积较大,安装时间可能稍长,请耐心等待。安装完成后,打开Windows终端(CMD或PowerShell),输入以下命令验证是否安装成功:
ollama
如果终端显示了Ollama的帮助信息和可用命令列表,说明安装已经成功,可以进入下一步了。
第二步:选择合适的DeepSeek模型版本
回到Ollama官网,点击左上角的"Models"标签,可以看到当前支持的所有大模型列表。找到并点击"DeepSeek R1",进入模型详情页面。
这里的关键决策是选择合适的参数版本。DeepSeek R1提供了从1.5B到671B的多个版本,参数量越大推理能力越强,但对硬件的要求也越高。
值得注意的是,Ollama分发的各版本均经过GGUF格式量化处理(通常为Q4_K_M或Q8_0精度),将每个参数从原始的16位浮点数压缩至4-8位,显存占用因此减少50%–75%,而推理质量损失通常在5%以内。以7B版本为例,原始FP16精度约需14GB存储,量化后仅需4.7GB,这正是普通消费级硬件能够运行它的根本原因。原始671B满血版以FP16精度存储则需要超过1TB显存,目前仍属企业级专属领域。
以下是各版本的硬件需求参考:
| 模型版本 | CPU | 内存 | 硬盘空间 | 显存 | 适用场景 |
|---|---|---|---|---|---|
| 1.5B | 4核+ | 8GB | 2GB | 4GB | 入门体验,性能较弱 |
| 7B/8B | 8核+ | 16GB | 8GB | 8GB | 日常使用,性价比最高 |
| 14B | 8核+ | 32GB | 14GB | 16GB | 进阶使用,效果更好 |
| 671B(满血版) | 高端服务器 | 极大 | 极大 | 极大 | 企业级,个人难以承受 |
对于大多数个人用户,推荐选择7B版本——它在推理性能和硬件需求之间取得了良好平衡,4.7GB的模型大小也在可接受范围内。如果你的电脑配置较高(32GB内存+16GB显存),可以考虑14B版本以获得更好的回答质量。
第三步:一键部署DeepSeek R1
选择好模型版本后(以7B为例),页面上会显示对应的安装命令。
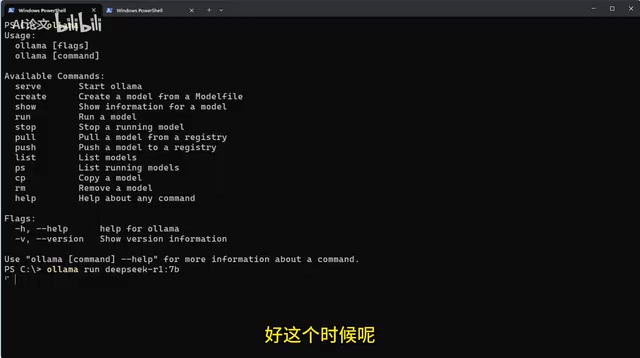
复制该命令,回到终端窗口粘贴并回车执行:
ollama run deepseek-r1:7b
首次运行时,Ollama会自动从远程服务器下载模型文件。DeepSeek R1 7B版本总大小约4.7GB,下载时间取决于你的网络速度。终端会实时显示下载进度,耐心等待即可。
当终端显示"success"字样时,恭喜你——DeepSeek R1已在本地部署成功!
第四步:本地对话体验
部署成功后,终端会自动进入对话模式。你可以直接输入问题与DeepSeek R1交互。例如输入"你是谁",模型会先进入思考过程,然后给出回答:它是由中国深度求索(DeepSeek)公司开发的人工智能助手。
这个"思考过程"是DeepSeek R1的标志性特性——推理链(Chain-of-Thought)。R1在训练阶段引入了强化学习(GRPO算法),激励模型在输出最终答案前进行显式的逐步推理,这些中间思考步骤以<think>标签包裹呈现给用户。这一机制使R1在数学推理、代码生成和逻辑分析任务上的表现显著优于同参数量的普通指令微调模型,其推理能力在多项基准测试中接近OpenAI o1系列。
在功能层面,本地部署的DeepSeek R1与网页版没有本质区别,同样具备深度推理能力。不同之处在于:
- 响应速度取决于本地硬件性能,而非网络状况
- 使用界面目前是命令行形式,不如网页版直观
- 无使用限制,不存在并发排队问题
进阶玩法:图形界面与本地知识库
命令行的交互方式对大多数用户来说并不友好,尤其是后续如果要接入本地知识库,纯命令行操作更是力不从心。目前社区有多种开源方案可以为Ollama搭配图形化界面,常见的选择包括:
- Open WebUI:提供类似ChatGPT的网页交互界面,部署简单
- AnythingLLM:支持本地知识库构建,可实现私域数据的RAG检索增强生成
- Cherry Studio:桌面端AI客户端,支持多模型管理和切换
其中,RAG(检索增强生成) 是本地知识库方案的核心技术架构,值得深入了解。其工作原理是:将私有文档切片后通过Embedding模型转化为向量,存入本地向量数据库(如ChromaDB、Milvus);用户提问时先在向量库中检索语义相似的文档片段,再将检索结果作为上下文注入大模型的Prompt中生成回答。这种方式绕过了大模型知识截止日期的限制,且无需对模型进行微调,是目前企业私有化AI部署的主流技术路线。AnythingLLM等工具已将这一完整流程封装为零代码操作界面,普通用户也可轻松上手。
通过这些工具的配合,你可以在本地构建一个完整的私域AI知识库系统,实现对私有数据的秒级检索和问答,同时确保数据安全不外泄。
总结
本地部署DeepSeek R1的核心流程非常简单:安装Ollama → 选择模型版本 → 一条命令部署。整个过程不需要任何编程基础,也不需要复杂的环境配置。关键是根据自己的硬件条件选择合适的模型版本——7B版本对于16GB内存、8GB显存的主流配置来说完全够用。
如果你受够了DeepSeek官网的卡顿和排队,不妨花10分钟试试通过Ollama本地部署,体验一下无延迟的AI对话。
核心要点
- 通过Ollama开源框架可以一键在本地部署DeepSeek R1,无需编程基础
- 7B版本是个人用户的最佳选择,仅需8核CPU、16GB内存、8GB显存即可运行
- 整个部署流程仅需三步:安装Ollama、选择模型版本、执行一条命令
- 本地部署可彻底解决官网卡顿问题,同时保障数据隐私安全
- 后续可结合Open WebUI等工具实现图形化界面和本地知识库功能
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。