DeepSeek接入QQ机器人教程:POST请求调用AI接口全流程详解

DeepSeek接入QQ机器人的原理与实现方法详解
本文介绍了将DeepSeek大语言模型接入QQ机器人的核心原理和实操方法。核心机制是通过POST请求调用AI的API接口,需要准备请求URL、Headers(含API Key认证)和JSON格式的Body参数。上下文对话通过每次将完整对话历史一并发送实现,因模型本身无状态。文章还介绍了三种接入方式,推荐使用标准POST请求方式。
前言
随着DeepSeek等大语言模型的普及,越来越多开发者想把AI能力集成到日常社交工具中。将DeepSeek接入QQ机器人,不仅能实现智能对话,还能在群聊中提供娱乐互动、智能问答等功能。本文系统梳理DeepSeek接入QQ机器人的核心原理与实现方法,帮助入门开发者快速上手。
核心原理:POST请求调用AI接口
为什么AI接口都用POST请求?
无论是DeepSeek、讯飞还是其他AI大模型,它们对外提供的API接口几乎都采用POST请求进行调用。要理解这一设计选择,需要了解HTTP协议的基本规范。
HTTP协议定义了多种请求方法,其中GET和POST是最常用的两种。GET请求将数据附加在URL后面传输,受限于浏览器和服务器对URL长度的限制(通常为2KB至8KB),适合获取简单资源;而POST请求将数据放在请求体(Body)中传输,理论上没有大小限制,更适合传输复杂的结构化数据。这种设计源自RESTful API规范——一种由Roy Fielding在2000年提出、如今已成为Web API设计事实标准的软件架构风格。
AI对话需要传递角色设定、对话历史、用户问题等复杂参数,往往包含数千字符的内容,GET请求的URL长度限制根本无法满足需求,POST请求因此成为唯一合理的选择。
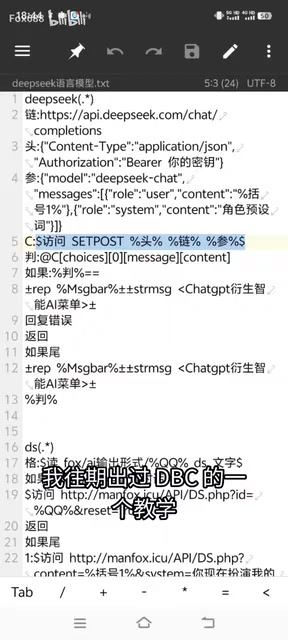
打开任何一个AI平台的官方文档,你都会发现它提供的调用示例(通常以cURL或Python代码呈现)本质上都是POST请求。QQ机器人插件中调用AI的原理完全一致——通过POST请求将用户消息发送给AI接口,再将返回结果展示在聊天窗口中。
POST请求的三要素
要成功调用DeepSeek的API,需要准备三个核心要素:
1. 请求链接(URL)
这是AI服务商提供的API端点地址。不同AI平台的链接不同,但功能类似。DeepSeek的API地址可以在其官方文档中找到。
2. 请求头(Headers)
请求头中包含认证信息和内容类型声明,按照官方文档格式填写即可:
Content-Type: application/jsonAuthorization: Bearer your-api-key
这里的认证方式采用的是OAuth 2.0标准定义的Bearer Token机制——「Bearer」意为「持有者」,即持有该令牌的任何人都可以访问对应资源。API Key是服务商用于识别调用方身份的凭证,一旦泄露他人即可冒用你的配额,因此切勿将API Key硬编码在源代码中,应存储在环境变量或加密配置文件里,并通过.gitignore防止其被上传到公开代码仓库。
3. 请求参数(Body)
这是最关键的部分,以JSON格式传递。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,以键值对组织数据,支持嵌套对象和数组,是现代API通信的标准格式。请求参数主要包含:
- 角色调教词(system prompt):定义AI的人设和行为规范
- 用户问题(content):用户实际发送的消息
- 模型选择:指定使用哪个DeepSeek模型版本
其中,System Prompt是大语言模型对话中一个特殊的消息角色,在messages数组中以"role": "system"标识。它在对话开始前就被注入,相当于给AI下达「元指令」——可以设定AI的身份、回复风格、知识边界,甚至限制机器人只回答特定领域的问题,是定制化AI体验的核心工具。
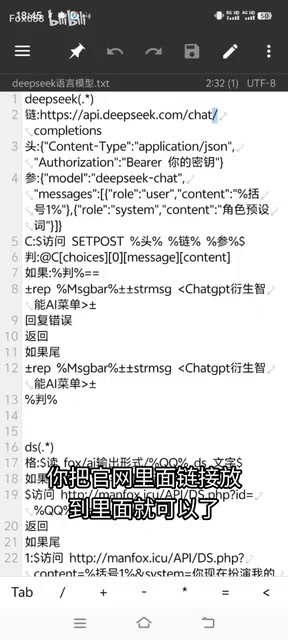
上下文对话的实现原理
数据驱动的对话记忆机制
很多人好奇QQ机器人中的AI是如何「记住」之前对话的。要理解这一机制,首先需要知道:大语言模型本身是无状态的——每次API调用都是独立的,模型不会自动记住上一次对话内容。所谓的「上下文记忆」,实际上是一种工程层面的模拟实现。
原理并不复杂:每次请求时,都会将之前所有的对话历史一并发送给DeepSeek。对话历史以数组形式存储,每条记录包含两个关键字段:
role:标识是用户(user)还是AI助手(assistant)content:对应的消息内容
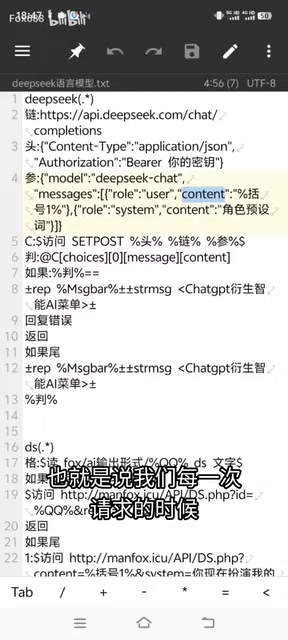
每次用户提问时,机器人将历史对话记录与新问题拼接在一起,作为请求参数发送给API。这就是请求参数使用JSON数组的原因——方便存储和拼接多轮对话数据。
然而,这种设计带来了一个重要的技术约束:上下文窗口(Context Window)。每个模型都有最大Token处理限制,例如DeepSeek-V3支持64K Token的上下文长度。Token是模型处理文本的基本单位,中文约1.5至2个字符对应1个Token,英文约4个字符对应1个Token。当对话历史过长时,超出限制的内容会被截断,同时也会增加API调用成本。在进阶开发中,需要设计滑动窗口或摘要压缩策略来平衡上下文完整性与Token消耗。
本地存储保证对话连续性
要在QQ机器人中实现上下文记忆,需要在本地或数据库中持久化存储每个用户的对话历史。这样即使机器人重启,也能保持对话的连续性。这部分属于进阶功能,需要结合具体的机器人框架来实现。
实操:三种DeepSeek接入QQ机器人的方式
在动手实践之前,有必要了解QQ机器人的开发生态背景。目前主流的开发框架包括:基于Python异步架构的NoneBot2(插件生态丰富)、基于Node.js的Koishi(支持多平台)以及各类基于OneBot协议的实现。OneBot是一个统一的聊天机器人应用接口标准,使得开发者编写的插件可以跨平台运行。腾讯官方也推出了QQ开放平台,提供合规的机器人接入方式。选择适合自己技术栈的框架,是集成AI能力的第一步。
方式一:标准POST请求(推荐)
这是最通用、最灵活的接入方式,基本流程如下:
- 在DeepSeek官网注册账号并获取API Key
- 查阅官方文档,找到API端点和请求格式
- 在机器人插件中编写POST请求代码
- 将请求链接、请求头、请求参数按照规范组装
- 发送请求并解析返回的JSON数据
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。