DiffusionGemma:谷歌开源扩散式语言模型,推理速度提升4倍
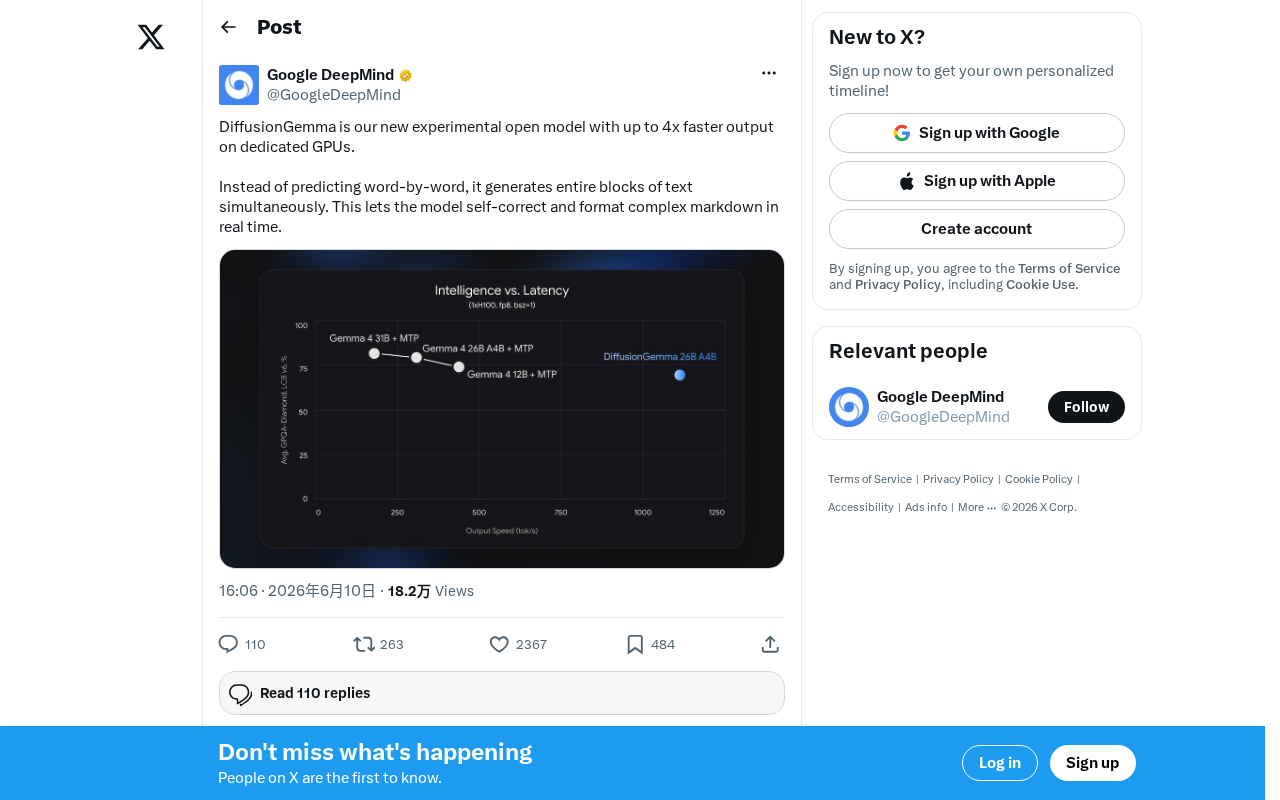
什么是DiffusionGemma
谷歌近日发布了一款名为DiffusionGemma的实验性开源模型,这是一种全新架构的语言模型——它不再像传统大语言模型那样逐词生成文本,而是借鉴扩散模型的思路,能够同时生成整块文本。据官方介绍,在专用GPU上,DiffusionGemma的输出速度最高可达传统方式的4倍。
这一消息标志着大语言模型在推理效率上的一次重要探索。当前主流的LLM(如GPT、Gemma、Llama等)均采用自回归(autoregressive)架构,即逐个token预测下一个词。这种方式虽然效果成熟,但在长文本生成时存在天然的速度瓶颈——生成速度与文本长度呈线性关系,难以并行化。
核心技术:从逐词生成到并行生成
扩散模型思路如何应用于文本生成
DiffusionGemma的核心创新在于将扩散模型(Diffusion Model)的理念从图像生成领域迁移到文本生成领域。在图像生成中,扩散模型通过逐步去噪的方式同时生成整张图片的所有像素,而非逐像素绘制。DiffusionGemma将类似的并行生成策略应用于文本:模型一次性生成整个文本块,然后通过迭代优化来提升质量。
这种方式带来了两个显著优势:
- 推理速度大幅提升:由于可以并行生成多个token,在专用GPU上实现了最高4倍的速度提升
- 全局一致性更强:模型在生成时能够"看到"整个文本块的全貌,而非仅依赖已生成的前文
实时自我纠错能力
谷歌特别强调了DiffusionGemma的自我纠错(self-correct)能力。传统自回归模型一旦生成了某个token,就很难回头修改——错误会沿着生成链条不断累积,这也是"幻觉"问题的成因之一。而DiffusionGemma采用迭代优化的生成方式,可以在生成过程中对已产出的内容进行修正和调整。
这一特性在处理复杂格式化内容时尤为突出。据官方描述,DiffusionGemma能够实时格式化复杂的Markdown文本,这意味着模型在生成结构化内容(如表格、代码块、嵌套列表等)时,可以在全局视角下确保格式的正确性,而不是像自回归模型那样"走一步看一步"。
技术意义与行业影响
扩散式LLM为何值得关注
DiffusionGemma并非扩散式语言模型的首次尝试。此前学术界已有多项相关研究,如MDLM、SEDD等工作探索了离散扩散模型在文本生成中的应用。但谷歌作为头部AI公司正式推出可用的开源模型,无疑将这一技术路线推向了更广泛的关注。
说个细节,DiffusionGemma被定位为"实验性"模型,这意味着它在某些任务上可能尚未达到成熟自回归模型的水平。但4倍的速度提升如果能在实际应用中得到验证,其商业价值将非常可观——推理成本正是当前LLM大规模部署的核心痛点之一。
开源策略的延续
谷歌选择将DiffusionGemma作为开源模型发布,延续了Gemma系列的开源策略。这不仅有助于社区对扩散式语言模型进行更深入的研究和改进,也体现了谷歌在开源生态建设上与Meta等竞争对手持续角力的态势。
展望:扩散式模型会成为LLM的未来吗
扩散式语言模型是否会成为下一代LLM的主流架构?目前下结论还为时尚早。自回归模型经过多年迭代,在推理质量、指令遵循、上下文理解等方面已经建立了深厚的技术积累。但DiffusionGemma所展示的速度优势和自纠错能力,确实为行业提供了一条值得探索的新路径。
未来可能出现的趋势是混合架构——在需要高速生成的场景(如实时对话、批量内容生产)中使用扩散式模型,在需要极高精度的场景中继续使用自回归模型。无论如何,DiffusionGemma的发布为LLM的技术演进增添了新的可能性。
相关推荐

Databricks开源Omni:统一管理所有AI Agent的元框架
Databricks以Apache 2.0协议开源Omni项目,通过元框架统一管理Claude Code、Codex等多个AI Agent。支持统一会话、跨供应商交叉审查、安全策略强制执行和实时协作,彻底解决多Agent协同与供应商锁定问题。
一句话提示词生成10款网页游戏:Claude Code实战体验
资深开发者用Claude Code命令行工具,仅凭一句话自然语言提示词,在一小时内生成2048、五子棋、俄罗斯方块等10款可玩网页游戏并部署上线。深度解析AI编程的真实能力与局限。

测试人必备的Cursor Skills五大技能包详解
详解测试工程师必备的五大Cursor Skills技能包,覆盖PRD需求分析、用例生成、JMeter脚本自动化、压测报告一键输出、Web自动化测试全流程,助你从执行者升级为质量架构师。