Dify搭建AI Agent智能体教程:工具调用与Exa搜索实战
基于Dify平台零代码搭建AI Agent的完整教程与实战指南
本文详细讲解了如何在Dify平台上搭建AI Agent,涵盖Agent与聊天助手的核心区别(推理策略与工具调用能力)、Dify插件生态中161个工具的使用、Exa搜索工具的深度配置,以及Agent时间感知问题的解决方案。文章强调Agent单次对话最多调用5次工具,建议按功能拆分为多个专用Agent,并推荐搭配DeepSeek V3等强模型以实现更智能的工具编排。
前言
AI Agent(智能体)是大语言模型应用中最值得关注的方向之一。和普通聊天助手不同,Agent能自主调用工具、获取实时信息、完成多步骤任务。这篇教程基于Dify零代码平台,从头拆解Agent搭建的完整流程——包括核心设定、工具调用、Exa搜索配置、时间感知问题的解决,帮你快速上手构建自己的AI智能体。
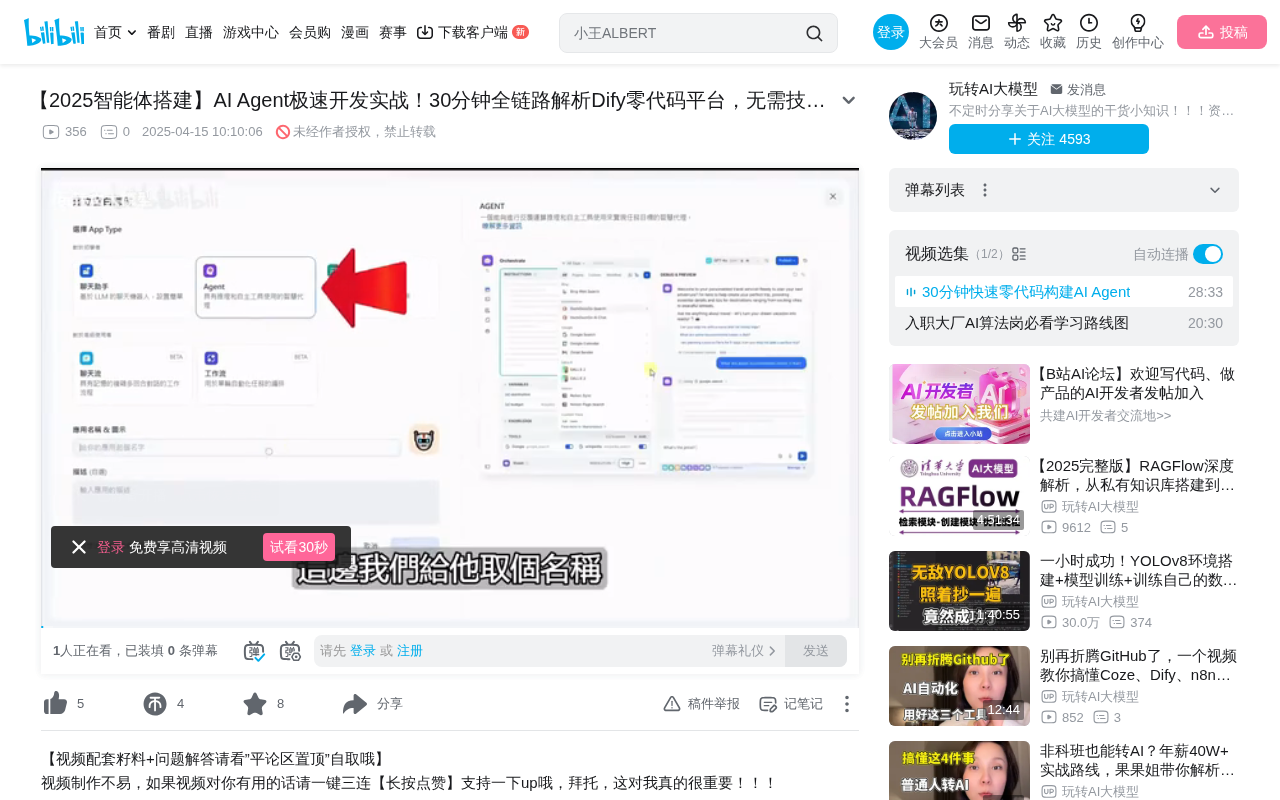
Agent与聊天助手的核心区别
在Dify中创建Agent的入口和聊天助手类似:选择空白应用、选Agent类型、命名后进入编辑界面。界面布局也差不多,左侧写提示词,右侧做对话测试。
那Agent和聊天助手到底有什么不同?关键差异在两点:
第一,Agent有独立的推理策略设定。 默认使用Function Call模式,这是OpenAI提供的工具调用API标准,目前大部分支持工具调用的模型都兼容这个协议。对于不支持Function Call的模型(比如DeepSeek R1推理模型),Dify会自动切换为ReAct模式——通过反复查询、迭代、总结的方式,用提示词技巧模拟工具调用能力。
Function Call是OpenAI在2023年6月随GPT-3.5/4 API更新引入的能力,它允许开发者在API请求中定义可用函数的JSON Schema描述,模型会根据用户意图判断是否需要调用某个函数,并生成结构化的参数输出。这种方式的优势在于模型原生支持,调用精准且token消耗低。ReAct(Reasoning + Acting)则是2022年由普林斯顿大学和Google Brain联合提出的框架,其核心思想是让模型交替进行"思考"(Thought)和"行动"(Action),每一步都先推理当前状态,再决定下一步操作,最后观察结果(Observation)。在Dify中,ReAct模式通过精心设计的提示词模板,引导模型按照固定格式输出工具调用指令,虽然灵活性更高、兼容性更广,但相比Function Call会消耗更多token且准确率略低。
第二,Agent可以挂载和调用外部工具。 这是Agent最强大的能力,也是它和普通聊天助手的根本区别。
工具调用次数限制
有一点需要特别注意:Dify中Agent单次对话最多只能调用5次工具。也就是说,即使你挂载了大量工具,Agent在一轮对话中也只能使用5次。所以建议把不同功能拆分成独立的Agent:一个专门查新闻做总结,一个专门查天气,一个专门做股票分析,各司其职,效果更好。
Dify工具生态:161个插件任你选
Dify 1.0之后,预设工具精简为少数几个(如CurrentTime、Audio等),更多工具需要通过插件市场(Marketplace)自行下载安装。
Dify从0.x版本到1.0经历了重大架构升级。早期版本将工具硬编码在平台中,扩展性有限。1.0版本引入了插件化架构(Plugin System),将工具、模型提供商、扩展功能等都抽象为可独立安装和更新的插件。这种设计借鉴了VS Code的扩展市场理念,开发者可以按照标准化的插件协议(包括manifest.yaml配置文件和Python/TypeScript实现)开发自定义工具,并发布到Marketplace供社区使用。这种架构的优势在于:平台核心保持轻量,用户按需安装所需功能,同时社区贡献形成正向循环。目前161个插件涵盖了搜索、生成、数据处理、通知等多个类别,且数量仍在快速增长。
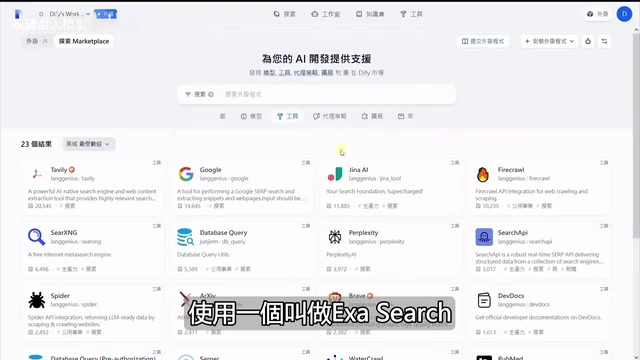
点击「外掛」→「探索Marketplace」,就能浏览目前已有的161个工具插件,支持按热门程度、最近更新、最新发布等维度筛选。
热门工具一览
- Tavily:下载量超2万,网络搜索查询工具,抓取网页内容并返回结果
- Google Search:Google搜索集成
- Jina:类似Tavily的网络内容查询工具
- DALL-E:OpenAI图片生成模型的独立工具封装
- FireCrawl:深度网页爬取工具,可设定爬取层级,将整个网站内容完整抓取
- Poke:将Markdown转换为PPT演示文稿
- Email:邮件发送工具,可将查询结果直接发送到指定邮箱
推荐搜索工具:Exa深度解析
在众多搜索工具中,我特别推荐Exa。它和Tavily、Jina最大的区别在于:Exa采用了类似RAG(检索增强生成)的技术架构。它预先把网站内容抓取并存储在自己的向量数据库中,查询时通过语义模糊匹配来检索信息,而不是传统的关键词搜索。
RAG(Retrieval-Augmented Generation,检索增强生成)是Meta AI在2020年提出的技术范式,核心思想是将外部知识检索与语言模型生成相结合。传统搜索引擎依赖倒排索引和BM25等关键词匹配算法,而RAG架构则先将文档通过Embedding模型转换为高维向量,存储在向量数据库(如Pinecone、Milvus、Weaviate)中,查询时将用户问题同样向量化,通过余弦相似度或内积等度量方式找到语义最相近的文档片段。Exa正是将这一技术应用于互联网规模的搜索场景——它持续爬取并索引数十亿网页,将内容预先向量化存储,使得查询时能够理解自然语言的语义意图,而非仅匹配字面关键词。这解释了为什么Exa的URL Content功能比实时爬取更快,因为内容已经在其数据库中预处理完毕。
Exa的四大功能模块
- Exa Search:核心搜索功能,支持三种搜索模式——神经网络语义搜索(向量检索)、关键词精确匹配、以及混合模式(Auto,推荐使用)
- URL Content:给定URL直接获取网页内容,类似FireCrawl但速度更快(因为内容已预先爬取)
- Similar Link:输入一个URL,通过语义相似度找到相关网站,实现「以链找链」
- Exa Answer:直接回答问题并给出总结(更适合在Exa官网使用,自建Agent建议用Search)
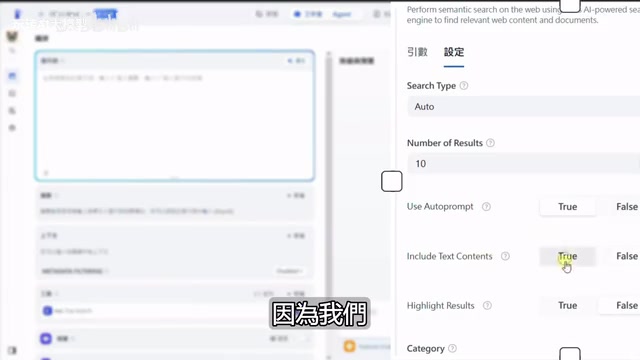
Exa关键参数配置
| 参数 | 建议设置 | 说明 |
|---|---|---|
| 搜索模式 | Auto(混合模式) | 兼顾语义搜索和关键词匹配 |
| 返回条数 | 按需调整 | 新闻查询10条够用,深度研究报告建议数百条 |
| Use Auto-Prompt | 按需开启 | 未优化提示词时建议开启 |
| Text Content | 必须勾选 | 否则只返回摘要,缺少完整内容 |
| Category | 按场景选择 | 如News查新闻、GitHub查代码、Twitter查社交动态 |
注册与费用
Exa注册后会赠送大量免费额度,完成新手任务后约有230美元的使用额度,基本可以长期免费使用。API Key在Exa官网生成后,粘贴到Dify的工具认证页面即可完成配置。
实战踩坑:Agent的时间感知问题
配置好Exa搜索工具后,来做一个实际测试:「请给我AI相关新闻」。
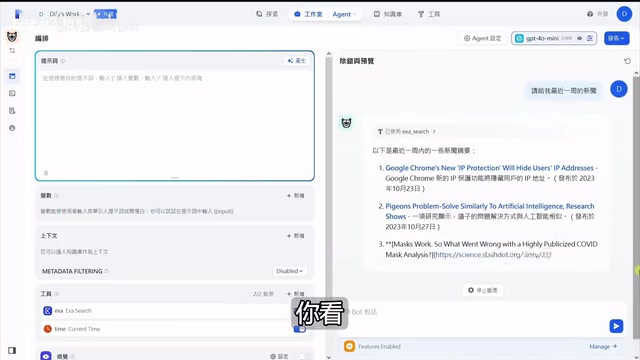
Agent确实通过Exa查到了新闻,但返回的全是2023年甚至更早的内容——现在都2025年了!这暴露了一个关键问题:大语言模型没有实时时间概念。
大语言模型的训练数据有明确的截止日期(knowledge cutoff),例如GPT-4o的训练数据截止到2024年初,这意味着模型对训练截止日期之后发生的事件一无所知。更深层的问题是,即使模型"知道"当前日期(通过系统提示词注入),它也缺乏将时间信息主动应用于工具参数的推理能力——这需要模型具备较强的规划(Planning)和工具使用(Tool Use)能力。较弱的模型(如GPT-4o mini)虽然在文本生成上表现不错,但在多步推理和工具编排方面能力有限,往往无法自主判断"用户问最近新闻→需要先获取当前时间→再用时间约束搜索范围"这样的推理链条。这也是为什么Agent场景对模型智能水平要求更高的原因。
解决方案:添加时间工具 + 选择更强模型
第一步,添加CurrentTime工具,让Agent获取当前时间。但光这样还不够——使用GPT-4o mini时,即使加了时间工具,Agent仍然不会主动调用它来约束搜索时间范围。
关键在第二步:切换到更强的模型。把模型从GPT-4o mini换成DeepSeek V3后,效果立竿见影:
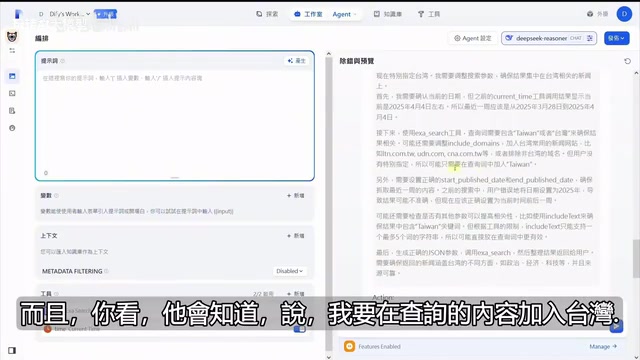
更聪明的模型会自动执行以下推理链:
- 先调用CurrentTime获取当前日期
- 计算「最近一周」的时间范围
- 把时间参数传入Exa搜索工具
- 根据用户提到的「台湾」自动在查询中加入地域限定
更令人印象深刻的是,Agent具备对话记忆能力。在第二轮对话中,它记住了上一轮已获取的时间信息,不再重复调用CurrentTime,直接用缓存的时间进行搜索,效率更高。
Agent的对话记忆能力依赖于上下文窗口(Context Window)机制。在多轮对话中,Dify会将之前的对话历史(包括用户输入、模型输出、工具调用结果)作为上下文一并发送给大语言模型。这意味着模型可以"看到"之前已经获取的信息,从而避免重复调用。但这也带来了token消耗的问题——随着对话轮次增加,上下文越来越长,API调用成本也随之上升。目前主流模型的上下文窗口从8K到128K不等(DeepSeek V3支持128K),超出窗口限制后早期对话内容会被截断。在生产环境中,通常会结合对话摘要、关键信息提取等策略来优化长对话场景的记忆效率。
Agent搭建的最佳实践
功能拆分原则
由于工具调用上限为5次,不要试图把所有能力塞进一个Agent。推荐的做法是:
- 新闻Agent:Exa搜索 + CurrentTime,专注新闻查询与总结
- 知识库Agent:挂载本地知识库,专注企业内部问答
- 数据分析Agent:股票查询 + 图表生成等专业工具
辅助功能配置
在Agent的管理设置中,还有几个实用功能值得关注:
- 开场白:为不善提问的用户提供示例问题,降低使用门槛
- 下一步建议:利用大模型预测能力,自动推荐后续可能的提问方向
- 知识库引用:后续讲解知识库时需要开启的功能
- 标注回复:适用于客服场景,可设定特定问题的标准化回答格式
总结
Dify平台让Agent搭建变得非常简单,但「简单」不等于「随意」。要构建一个真正好用的AI智能体,你需要理解工具调用机制、合理配置搜索参数、选择匹配的大语言模型,并遵循功能拆分的设计原则。掌握这些要点后,即使没有编程背景,也能快速搭建出具备实时信息获取、智能分析等能力的Agent。
核心要点
- Dify Agent最多调用5次工具,建议按功能拆分为多个专用Agent
- Exa搜索工具采用RAG技术架构,支持语义搜索、关键词匹配和混合模式,注册即送约230美元免费额度
- Agent缺乏时间感知能力,需要添加CurrentTime工具并搭配更强模型(如DeepSeek V3)才能正确处理时效性查询
- 不支持Function Call的模型(如DeepSeek R1)会自动切换为ReAct模式,通过提示词技巧模拟工具调用
- Agent具备对话记忆能力,可在多轮对话中复用之前获取的信息,避免重复调用工具
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。