Docker Model Runner使用教程:一条命令本地运行AI模型

Docker Model Runner让本地AI模型部署像Docker容器一样简单
Docker Model Runner通过将AI模型运行标准化为Docker工作流,解决了本地部署AI模型时CUDA版本管理、依赖冲突等痛点。它支持一条命令拉取和运行模型,与Docker Compose深度集成,兼容OpenAI API标准接口,让开发者可以像管理普通容器服务一样编排AI模型,大幅降低了本地AI开发的门槛。
为什么需要 Docker Model Runner?
在本地部署AI模型,传统方式往往让人头疼:安装Python、配置CUDA、管理各种依赖库,还要祈祷它们之间不会产生版本冲突。即便使用Ollama等工具,也需要额外搭建API层。开发者花在环境配置上的时间,往往远超实际构建应用的时间。
这一痛点的根源在于CUDA(Compute Unified Device Architecture)——NVIDIA推出的并行计算平台,几乎是本地运行大型语言模型的标配。然而CUDA的版本管理极为复杂:不同的模型框架(PyTorch、TensorFlow)对CUDA版本有严格要求,而CUDA版本又与显卡驱动版本强绑定。一台机器上同时维护多个CUDA版本几乎是噩梦,这也是为什么"在我机器上能跑"成为AI开发领域的经典梗。
Docker Model Runner 的出现正是为了解决这个痛点。它将AI模型的运行标准化为Docker工作流——一条命令拉取模型,一条命令启动运行,无需任何额外配置,底层的CUDA依赖和驱动适配被完全封装在内部。更关键的是,它能直接集成到 Docker Compose 中,让AI模型像普通容器服务一样被编排和管理。
快速上手:像拉取镜像一样拉取模型
Docker Model Runner 引入了一个新的关键字:model。如果你已经安装了最新版 Docker Desktop,只需在设置中启用 Docker Model 功能即可开始使用。
这种"像拉取镜像一样拉取模型"的体验,背后依赖的是OCI(Open Container Initiative)标准的扩展。传统Docker镜像使用OCI Image Spec存储和分发,而模型文件(通常是GGUF格式——一种专为推理优化的量化模型格式)同样可以被打包为符合OCI规范的artifact,存储在容器镜像仓库中。这意味着现有的镜像仓库基础设施(包括Docker Hub、私有Registry)可以直接复用来托管和分发AI模型,无需建立新的模型存储体系。
核心命令非常简洁:
# 拉取模型
docker model pull ai/gpt-oss
docker model pull ai/llama-3.2
# 查看已拉取的模型
docker model list
# 直接运行模型(未拉取会自动下载)
docker model run ai/gpt-oss
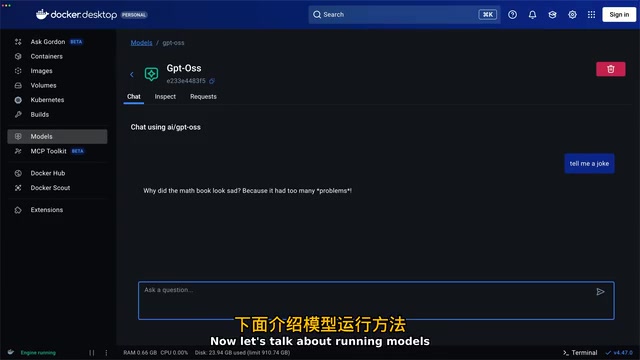
运行后会进入CLI交互界面,可以直接与模型对话。首次请求需要等待模型加载到内存,之后的响应速度非常快。如果你不喜欢命令行,Docker Desktop 中也提供了图形化的模型管理界面,支持一键拉取、运行和对话。
这种体验与拉取Docker镜像几乎一致,大幅降低了AI模型本地部署的门槛。
与 Docker Compose 深度集成
Docker Model Runner 真正的杀手锏在于它与 Docker Compose 的无缝集成。你可以将AI模型作为一个服务定义在 docker-compose.yml 中,与其他应用服务一起编排。
以下是一个使用 Open WebUI 作为前端、Docker Model Runner 作为后端模型服务的配置示例:
services:
webui:
image: open-webui
ports:
- "3000:3000"
model-runner:
provider:
type: model
options:
model: ai/gpt-oss
关键配置有两点:一是 provider 类型设为 model;二是应用通过 model-runner.docker.internal 这个内部DNS与模型服务通信。
model-runner.docker.internal 是Docker为容器间通信设计的内部DNS解析机制的延伸。在Docker网络中,容器可以通过服务名直接相互访问,而 *.docker.internal 域名则专门用于容器访问宿主机或Docker特殊服务。这种设计避免了硬编码IP地址的问题,同时也解决了开发环境(localhost:12434)与容器环境(model-runner.docker.internal)的地址差异——只需通过环境变量切换,应用代码本身无需任何改动,体现了十二要素应用(12-Factor App)中配置与代码分离的最佳实践。
运行 docker compose up 后,两个服务同时启动,Open WebUI 能自动发现本地模型并在界面中切换使用。
由于 Docker Model Runner 兼容标准的 OpenAI API 接口,后续更换模型只需修改一行配置。值得一提的是,自2023年起,OpenAI的Chat Completions API(/v1/chat/completions)已事实上成为大语言模型服务的行业标准接口——Ollama、LM Studio、vLLM、LocalAI等几乎所有本地推理框架都选择兼容这一接口。这意味着任何为OpenAI API编写的客户端代码,包括LangChain、LlamaIndex等主流AI应用框架,无需任何修改即可切换到本地模型。你可以把模型服务当作 Compose 文件中的普通服务来对待——启动、停止、重启,完全是你已经熟悉的Docker工作流。
实战:构建自定义AI聊天应用
为了展示实际开发场景,下面介绍一个完整的聊天机器人应用案例,技术栈包括 Next.js、TypeScript、Tailwind CSS 和 React,后端通过 Docker Model Runner 提供模型推理能力。
应用架构
应用的核心架构非常清晰:
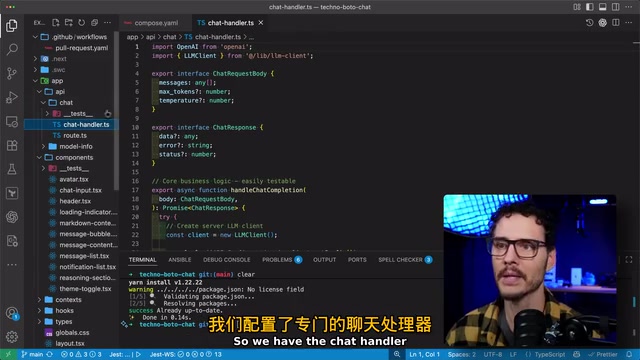
- API层:包含
/chat和/model-info两个端点 - 消息流:用户发送消息 → Node.js 服务端 → Docker Model Runner API → 返回推理结果 → 渲染到客户端
- 环境配置:通过
.env.local文件管理,本地开发时模型API地址为localhost:12434,容器内运行时使用model-runner.docker.internal
运行效果
启动应用后,用户可以直接在聊天界面与本地模型交互。
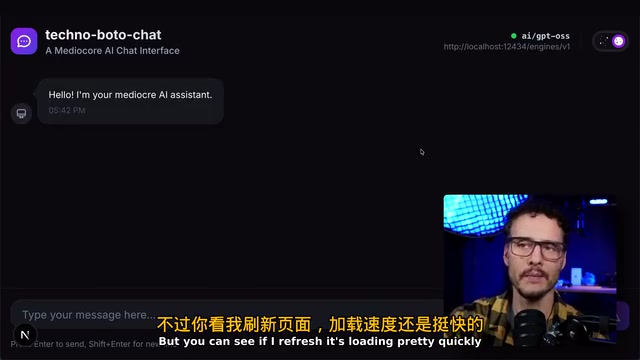
测试了「规划一次去海王星的旅行」这样的提示词,使用的是支持思维链(Chain of Thought)的模型。思维链(CoT)是由Google Research在2022年提出的提示工程技术,后来演变为一类专门训练的模型能力——模型在给出最终答案前,会先输出一段结构化的推理过程(通常包裹在 <think> 标签中),这种"先思考后回答
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。