Dogra:开源自托管语音AI平台,告别VAPI天价账单

开源项目Dogra试图解决语音AI开发中的高成本与供应商锁定问题
语音AI开发面临成本叠加、供应商锁定和系统复杂性三大困境。开源项目Dogra通过提供语音引擎、可视化工作流构建器和平台层三大核心能力,让开发者可以自带服务商、用流程图设计对话逻辑、并获得完整的可观测性工具,从而在降低成本的同时掌控整个系统,支持Docker一键本地部署。
语音AI的隐痛:账单与失控
你刚搭建好一个语音AI Agent,运行效果不错,然后账单来了——LLM费用、语音合成费用、电话费用,再加上平台抽成。更糟糕的是,你并不真正拥有这个系统。平台涨价,你只能接受;平台改限制,你也只能接受;需要自定义部署?大概率直接撞墙。
这就是当前语音AI开发者面临的现实困境。而一个名为 Dogra 的开源项目,正试图从根本上改变这一局面。

语音AI开发远比想象中复杂
从外部看,语音AI的流程似乎很简单:接电话 → 语音转文字 → 发给LLM → 文字转语音 → 完成。但任何真正做过语音Agent的人都清楚,现实中的通话充满了不确定性。
用户会打断你,会突然沉默,会切换话题,会问出完全意想不到的问题。你的Agent需要调用各种外部API,当系统出问题时,你需要精确定位到底哪个环节出了问题。
一个语音Agent绝不仅仅是"带电话号码的ChatGPT"。它是一个包含大量活动组件的实时系统:语音转文字(STT)、大语言模型(LLM)、文字转语音(TTS)、状态管理、工具调用……
技术背景:语音AI的多层供应商生态
语音AI系统的技术栈由多个独立组件串联而成,每个组件都有其专业的供应商生态。STT(Speech-to-Text)领域的主要玩家包括 Deepgram、AssemblyAI 和 OpenAI Whisper,它们在延迟、准确率和价格上各有侧重;TTS(Text-to-Speech)领域则有 ElevenLabs(以高拟真度著称)、Cartesia(主打低延迟)和微软 Azure Neural Voice(企业级稳定性)等选择;LLM 层面则是 GPT-4、Claude、Gemini 等模型的竞争。这种多层供应商结构带来了独特的成本叠加效应——每一层都在独立计费,而托管平台往往在这些成本之上再加一层利润抽成,导致规模化后的账单远超预期。
当通话出错时,"机器人给了个错误回答"这种信息远远不够。是提示词写得有问题?是模型选错了?还是某个API调用超时了?你需要完整的调用链路来排查。
Dogra是什么?三大核心能力详解
Dogra本质上提供了三个层面的能力:语音引擎、可视化工作流构建器和平台层。这三者组合在一起,构成了一个完整的开源语音AI开发平台。
语音引擎:让通话真正跑起来
语音引擎是Dogra的核心,负责连接来电者、电话服务商、STT、LLM和TTS。它处理通话中所有实时交互场景,包括中断处理、静默检测等复杂情况。
其中,**中断处理(Interruption Handling)**是语音AI系统中技术难度最高的环节之一。当用户在AI说话时打断对话,系统需要在毫秒级别内完成:停止当前TTS音频流、丢弃已生成但未播放的内容、重置LLM上下文状态、重新进入STT监听模式。任何一个环节的延迟都会让用户感受到明显的卡顿或"鬼畜"现象。**静默检测(Silence Detection)**同样关键——系统需要区分用户"思考中的停顿"和"真正说完了",过于激进的检测会打断用户,过于保守则会让对话节奏拖沓。
最关键的一点是,你可以自带服务商——用自己的LLM、自己的TTS提供商,不会被任何单一供应商锁定。
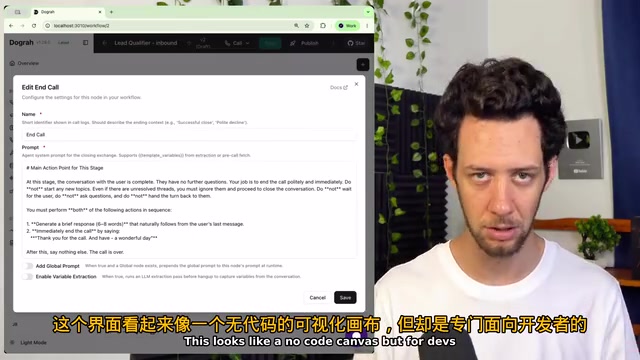
可视化工作流构建器:用流程图设计对话逻辑
工作流构建器让你能够以可视化方式设计整个对话逻辑。不再需要硬编码每一个提示词、分支判断、API调用和转接规则,而是像画流程图一样映射出完整流程:问这个问题 → 等待回答 → 调用这个API → 在这里分支 → 在那里转接。
这看起来像一个无代码画布,但它是为开发者设计的。它的价值不在于"无代码"本身,而在于不浪费代码——你不需要写大量胶水代码来串联各个组件。把代码用在真正需要自定义逻辑的地方,把流程编排交给构建器。
技术背景:对话流程编排的演进
对话系统的编排方式经历了从硬编码状态机、到基于规则的对话树、再到当前 LLM 驱动的动态流程的演进。早期的 IVR(Interactive Voice Response,交互式语音应答)系统完全依赖预定义的按键菜单,灵活性极差。现代语音AI引入LLM后,虽然大幅提升了自然语言理解能力,但也带来了新的挑战:纯LLM驱动的对话容易"跑偏",难以保证关键业务节点(如收集必要信息、触发特定API)的可靠执行。可视化工作流构建器的价值正在于此——它在LLM的灵活性与业务流程的确定性之间找到平衡,让开发者能够精确控制对话的骨架结构,同时在每个节点内保留LLM的自然语言能力。
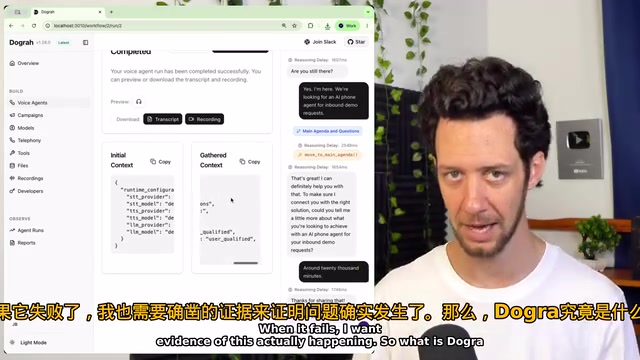
平台层:测试、追踪、录音、分析一站搞定
这是每个正式上线的语音AI项目最终都需要、但往往被忽视的部分。Dogra提供了完整的测试工具、调用追踪、通话录音和数据分析能力。当你的Agent出问题时,你可以看到完整的转录文本、执行追踪、实际触发的工具调用以及状态变化。
技术背景:可观测性(Observability)的三大支柱
可观测性是现代分布式系统工程的核心概念,由日志(Logs)、**指标(Metrics)和追踪(Traces)**三大支柱构成,这一框架由 CNCF(云原生计算基金会)在 OpenTelemetry 项目中标准化。对于语音AI这类实时系统,传统的监控手段往往不够用——一次失败的通话可能涉及网络延迟(电话运营商侧)、模型幻觉(LLM侧)、工具调用超时(API侧)等多种根因,且这些问题往往交织在一起。完整的调用链路追踪(Distributed Tracing)能够为每次通话生成一条带时间戳的事件序列,让开发者像"回放录像"一样复盘整个交互过程。这正是 Datadog、Jaeger 等 APM 工具在传统软件领域解决的问题,而 Dogra 将类似能力原生集成到了语音AI平台中。
这正是开发者真正需要的可观测性——不只是知道"机器人工作了",而是清楚为什么工作了,以及当它失败时,有充分的证据快速定位根因。
实战演示:构建一个线索筛选Agent
本地部署:Docker一键启动
Dogra的本地部署非常简洁,三步即可完成:
git clone <dogra-repo-url>
cd dogra
docker compose up
Docker Compose 是容器编排的事实标准工具,它通过一个 docker-compose.yml 配置文件定义多个服务(如数据库、后端API、前端UI、消息队列等)之间的依赖关系和网络配置,一条命令即可启动整个应用栈。对于 Dogra 这类包含多个微服务组件的平台来说,Docker 优先的部署方式意味着开发者无需手动配置各组件的运行环境,显著降低了"在我机器上能跑"问题的发生概率,也为后续迁移到 Kubernetes 等生产级编排平台奠定了基础。
容器运行后,直接访问Dogra的Web UI即可开始构建语音Agent。对于一个声称"为开发者打造
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。