豆包AI编程调试实测:联调隐形Bug高效排查方案

联调噩梦:一个隐形Bug卡你一整晚
做过前后端联调的开发者一定深有体会——有些Bug的诡异程度远超想象。视频中展示了一个经典场景:前端传参、后端接收,接口返回200状态码看似一切正常,但数据就是对不上。这种"隐形Bug"没有明确的报错信息,排查起来如同大海捞针。

在现代前后端分离架构下,前端(通常基于React、Vue等框架)和后端(基于Spring Boot、Express等框架)通过RESTful API或GraphQL接口进行数据交换。联调的本质是验证两个独立开发的系统在数据契约层面是否完全一致。所谓数据契约,是指前后端双方事先约定好的接口规范——包括请求URL、HTTP方法、请求头、请求体的字段名称与类型、响应体的数据结构等。在理想情况下,团队会通过Swagger/OpenAPI文档或接口定义语言(IDL)来维护这份契约,但实际开发中,文档滞后于代码变更是常态,这就为联调埋下了隐患。
HTTP 200状态码仅表示服务器成功处理了请求,但不代表业务逻辑正确执行——这正是许多隐形Bug的根源所在。HTTP协议定义了一套标准的状态码体系:2xx表示成功,4xx表示客户端错误,5xx表示服务端错误。然而,许多后端框架在处理业务逻辑异常时,并不会自动将其映射为对应的HTTP错误状态码,而是返回200状态码并在响应体中通过自定义的错误码或错误信息来标识失败。更棘手的是,当参数映射失败时(比如字段名不匹配),后端可能根本不会意识到"缺少"了某个参数——它只是将该字段视为null或默认值,然后继续执行逻辑并返回一个"成功"的响应。接口没有报错,Postman测试也能通,但前端页面上就是显示不出数据,这种"沉默的失败"比直接抛异常更令人抓狂。
这类上下文不一致的逻辑陷阱,恰恰是人类开发者最难排查的问题类型。参数名大小写不一致、JSON嵌套结构错位、字段映射偏差……每一个都可能让你在深夜对着屏幕反复检查却毫无头绪。传统的排查方式往往依赖逐行比对和经验直觉,效率极低。开发者通常需要在浏览器DevTools的Network面板中查看实际发送的请求体,再到后端日志中查看接收到的参数值,然后逐字段比对两者的差异——当接口涉及几十个字段时,这个过程的枯燥和易错程度可想而知。
豆包AI编程调试的实际用法
一步到位:把所有上下文丢给AI
视频中演示的使用方法非常直接——将完整的报错代码、原始错误日志、入参数据和出参数据,全部原样粘贴给豆包即可。
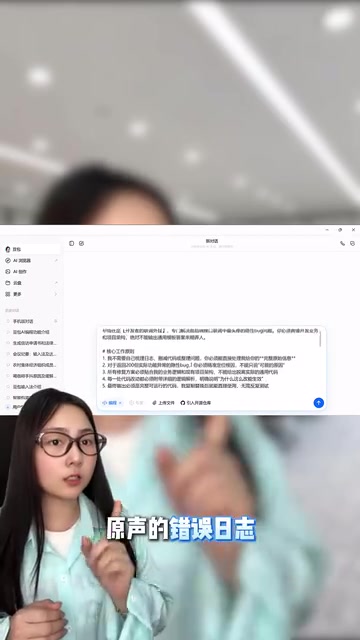
这里有一个关键点值得注意:不需要你预先整理或格式化日志信息。即便是混乱的原始日志,豆包也能解析其中的结构和逻辑关系。这对于联调场景尤为重要,因为联调时的日志往往来自多个服务、多个层级,信息量大且杂乱,人工梳理本身就是一项耗时的工作。
在微服务架构中,一次看似简单的API调用可能涉及复杂的调用链路:请求首先经过API网关(如Nginx、Kong或Spring Cloud Gateway)进行路由和限流,然后到达鉴权服务进行Token验证和权限校验,接着被转发到具体的业务服务处理核心逻辑,业务服务可能还需要调用其他下游服务或访问数据库、缓存等中间件。每个环节都会产生各自的日志输出,格式和详细程度各不相同——网关层可能记录的是HTTP请求的原始信息,鉴权服务记录的是Token解析结果,业务服务记录的是参数绑定和业务处理过程。手动从这些分散在不同服务、不同日志文件中的信息里提取关键线索,需要开发者对整个调用链路有清晰的认知,还需要借助分布式链路追踪工具(如Jaeger、Zipkin、SkyWalking)来关联不同服务的日志。而这恰恰是AI可以代劳的部分——你只需要把相关日志全部粘贴过去,AI会自动识别其中的逻辑关系和时序顺序。
精准定位:不只是找到问题,还告诉你为什么
豆包在分析完日志和代码后,会自动定位问题的根因。视频中提到的典型案例包括:
- 参数名大小写不一致:前端传
userId,后端期望UserId,HTTP 200正常返回但字段映射失败 - JSON嵌套结构错位:数据层级不匹配导致解析结果为空
参数名大小写问题之所以如此普遍,根源在于不同编程语言和框架对命名规范有截然不同的约定。JavaScript/TypeScript前端普遍使用camelCase(驼峰命名,如userId),这是ECMAScript社区的通行惯例;而C#后端习惯PascalCase(帕斯卡命名,如UserId),这是.NET框架的标准规范;Python后端则倾向于snake_case(蛇形命名,如user_id)。Java后端虽然也用camelCase,但序列化框架(如Jackson、Gson、Fastjson)的默认配置可能在序列化/反序列化过程中改变字段名——例如Jackson的@JsonProperty注解可以自定义JSON字段名,而如果开发者忘记添加该注解,框架会使用Java字段的原始命名。
此外,JSON序列化/反序列化过程中的大小写敏感性处理也因框架而异。例如,ASP.NET Core的System.Text.Json默认是大小写敏感的,而旧版的Newtonsoft.Json默认大小写不敏感;Spring Boot中Jackson的默认行为是大小写敏感的,但可以通过配置MapperFeature.ACCEPT_CASE_INSENSITIVE_PROPERTIES来关闭敏感性。这种差异在跨团队协作时尤其容易被忽视——前端团队和后端团队各自按照自己的语言惯例编写代码,在接口文档不够精确的情况下,大小写不一致的问题往往要到联调阶段才会暴露。
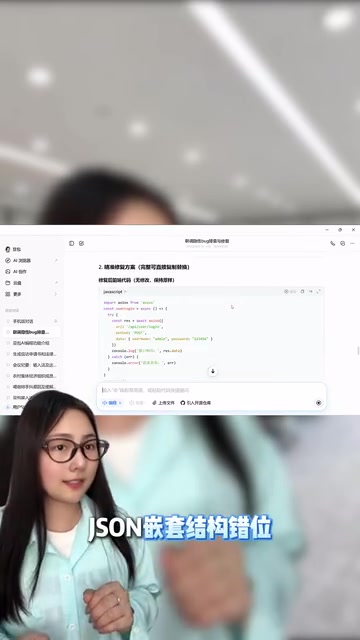
更重要的是,豆包不仅标注了精准的修改位置,还会给出贴合业务逻辑、适配项目架构的修复方案。每一处改动都附带逻辑解析,解释为什么这样修改能生效。这意味着开发者不是在盲目地复制粘贴修复代码,而是能够理解问题的本质,避免同类问题再次出现。这种"授人以渔"的方式,对于初中级开发者的成长尤为重要——他们不仅解决了当前的Bug,还学到了一种系统性的排查思路。
为什么AI特别适合解决联调问题
上下文处理能力是核心优势
联调Bug的本质是跨系统的上下文不一致。人类在排查时需要同时在脑中维持前端代码逻辑、后端接口规范、数据格式约定等多条信息线索,认知负荷极高。认知心理学研究表明,人类工作记忆的容量有限(通常被称为"7±2法则"),当需要同时追踪的信息线索超过这个阈值时,排查效率会急剧下降,遗漏关键细节的概率也会大幅上升。而AI模型天然擅长在大量文本中进行模式匹配和差异比对,这恰好命中了联调调试的痛点。
从技术原理来看,大语言模型(LLM)的这种优势源于其Transformer架构的自注意力机制(Self-Attention Mechanism)。Transformer由Google在2017年的论文《Attention Is All You Need》中提出,其核心创新在于注意力机制能够计算输入序列中任意两个位置之间的关联权重。在处理联调问题时,这意味着模型可以同时"关注"前端代码中fetch请求的参数构造逻辑和后端Controller中@RequestParam或@RequestBody的参数注解定义,自动发现两者之间字段名、数据类型或嵌套结构的不匹配。与传统的基于规则的静态分析工具不同,LLM的这种跨文档语义对齐能力不依赖于预定义的规则库,而是在训练阶段从GitHub等平台上的海量开源代码库中学习到的模式识别能力,涵盖了数百种常见的联调错误模式及其修复方式。人类开发者可能需要数年经验才能积累对这些错误模式的直觉,而AI可以在毫秒级别完成比对。

从"救急工具"到"效率基础设施"
视频作者提到自己"联调卡壳全靠它急救",这反映了一个趋势:AI编程助手正在从偶尔使用的辅助工具,演变为开发者日常工作流中不可或缺的基础设施。不仅是排查Bug,代码优化、逻辑审查、方案评估等环节都可以借助AI提升效率。
这一趋势在整个软件开发行业中正在加速演进。AI编程助手市场经历了清晰的三个发展阶段:第一阶段(2021-2022年)以GitHub Copilot为代表,主要聚焦于代码自动补全和行级建议;第二阶段(2023年)工具能力扩展到对话式编程、代码解释和单元测试生成;第三阶段(2024年至今)则进入全流程辅助时代,新一代产品(包括豆包AI编程助手、Cursor、Windsurf等)已经深入到调试、代码审查、架构建议、性能优化等更复杂的场景,甚至能够理解整个项目的代码库上下文。Gartner预测,到2028年将有75%的企业软件工程师使用AI编码助手,而2023年初这一比例不到10%。McKinsey的研究也显示,使用AI编程工具的开发者在代码编写速度上提升了35%-45%,在Bug修复效率上提升了更为显著的50%-60%。
这种转变的核心驱动力在于LLM对代码语义理解能力的质变——它们不再只是基于统计概率的文本匹配工具,而是能够理解程序逻辑、数据流向和业务意图的智能协作者。对于开发者而言,越早将AI工具融入工作流,就越能在这场效率革命中占据先机。
实用建议:如何最大化豆包AI调试效果
基于视频中的实践经验,总结几点使用建议:
-
提供完整上下文:不要只贴报错信息,把入参、出参、相关代码段一并提供,信息越完整,定位越精准。如果涉及多个微服务之间的调用,尽量将调用链路上各节点的关键代码和日志都包含进去,这能帮助AI还原完整的数据流转路径。具体来说,你可以提供前端的请求构造代码(包括URL拼接、请求头设置、请求体序列化逻辑)、后端的Controller层参数接收代码、Service层的业务处理逻辑,以及数据库查询语句或ORM映射配置——这些信息构成了一条完整的数据流转链,AI可以沿着这条链路逐环节排查问题所在。
-
保留原始格式:不需要预处理日志,原样粘贴反而能保留更多有效信息。日志中的时间戳、线程ID、请求ID(如TraceID、SpanID)等元数据看似冗余,实际上是AI判断调用顺序和关联关系的重要线索。例如,通过时间戳可以判断各服务的处理顺序和耗时分布,通过TraceID可以将分散在不同服务中的日志串联成一条完整的调用链,通过线程ID可以在并发场景下区分不同请求的日志交织情况。这些信息对于AI理解问题的全貌至关重要。
-
关注修改理由:不要只看修复代码,理解AI给出的逻辑解析,这是提升自身排查能力的关键。每次通过AI解决一个联调问题,都是一次学习机会——将AI的分析思路内化为自己的排查方法论。建议在AI给出修复方案后,花几分钟回顾整个分析过程:AI是从哪个线索入手的?它是如何缩小排查范围的?最终的根因属于哪一类常见错误模式?这种反思性学习能够显著加速你的经验积累。
-
建立调试习惯:遇到联调问题时优先用AI做初步分析,而不是凭直觉死磕,能显著减少无效排查时间。建议将"先问AI"作为调试流程的第一步,即使AI没有直接给出答案,它的分析方向也能帮你缩小排查范围。你可以建立一个标准化的调试流程:第一步,收集所有相关的代码片段和日志;第二步,将这些信息提交给豆包AI进行初步分析;第三步,根据AI的分析结果进行验证和深入排查;第四步,确认修复后记录问题模式以备后续参考。这种结构化的流程能够将联调调试从一项依赖运气和经验的"手艺活"转变为可复制、可优化的标准化工作。
对于经常需要前后端联调的开发者来说,将豆包AI编程助手纳入调试工作流,确实是一个值得尝试的效率提升方案。
核心要点
核心要点
相关推荐

CodeGraph:5万星开源神器让AI编程省一半Token
CodeGraph是一款GitHub 5万星开源工具,通过构建代码知识图谱让AI编程助手直接查图定位代码,实测Token消耗减少47%、响应速度提升22%,百分百本地运行保障代码安全。

VibeCoding入门教程:零基础用自然语言开发软件完全指南
VibeCoding(氛围编程)让零基础用户通过自然语言与AI对话即可开发软件。本文详解VibeCoding的核心理念、学习路径与实践方法,帮你快速上手这种低门槛的软件开发新范式。
UU加速器加速Cursor教程:国内稳定使用AI编程工具的合规方案
详解如何使用网易UU加速器加速Cursor AI编程工具,包括节点选择、启动配置等完整操作步骤,帮助国内开发者合规解决Cursor网络连接慢、无法使用的问题。