Fable 5 vs Opus 4.8实测对比:三大项目验证谁是AI编程王者

引言:一场硬核的AI编程对决
当Anthropic的两款旗舰模型——Claude Opus 4.8和Fable 5——被放在同一起跑线上,用完全相同的提示词完成三个高难度项目时,结果会如何?一位B站UP主设计了一场极为严苛的测试:一个完整的电商网站、一个交互式3D艺术博物馆、以及一个帝国时代风格的即时战略游戏。规则很简单——一次性输出,不能修改,直接上线。
这不是简单的代码补全测试,而是对AI模型在架构设计、UI美学、数据处理、3D渲染等多维度能力的全面考验。结果令人震惊:Fable 5几乎在每个维度上都碾压了Opus 4.8。
第一战:电商网站——细节决定成败
测试设定
提示词要求为虚构蜡烛品牌"Soulburn"搭建完整电商网站,包含30种产品、各具特色的产品图、清晰的文字对比度、分类筛选等功能。这个项目一次性测试了首页设计、电商交互、数据库架构等多项能力。
Opus 4.8的表现
Opus 4.8交出的作品比之前动态工作流的版本有所进步——至少文字能看清了,蜡烛上也有了标签。但细节问题不少:蜡烛图放在了遮挡文字的位置,分类筛选器选项过多显得杂乱,购物车图标看起来像垃圾桶,导航栏体验糟糕。整体给人的感觉是"能用但粗糙"。
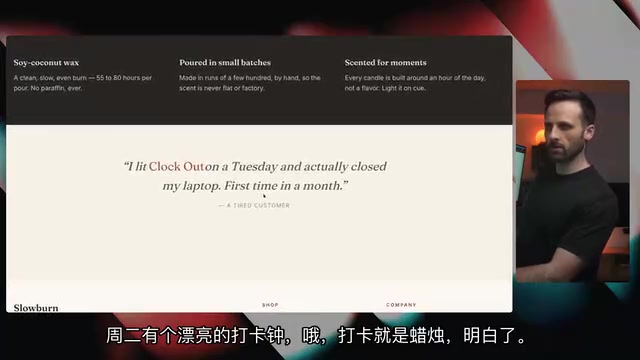
Fable 5的表现
Fable 5的输出则明显更有"电商味":顶部通知栏、精致的渐变背景、轮播按钮、产品悬停放大效果一应俱全。最令人惊叹的是图片生成质量——模型自主学会了如何提示图像生成模型,生成的蜡烛照片带有小树枝、阴影、阳光和纹理背景,甚至从蜡烛颜色中提取灵感来搭配整体色调。
这种"审美意识"的背后,反映的是模型对视觉设计原则的深层理解。传统的AI代码生成往往只关注功能实现,而Fable 5展现出了对色彩理论、视觉层次和品牌一致性的把握——它不仅在写代码,更像是在做产品设计。
数据对比
| 指标 | Opus 4.8 | Fable 5 |
|---|---|---|
| 输出Token | 489.8万 | 58.8万 |
| 预估成本 | $21.41 | $36.84 |
| 完成时间 | ~50分钟 | ~35分钟 |
Token是大语言模型处理文本的基本单位,通常一个英文单词对应1-2个Token,一行代码可能包含10-30个Token。Opus 4.8消耗了489.8万输出Token,而Fable 5仅用58.8万就实现了更好的效果——这意味着Fable 5的代码生成密度和精准度有了数量级的提升。Token效率的提高通常源于模型架构的优化、更好的注意力机制、以及训练数据中高质量代码样本的比例提升。更少的Token不仅意味着更低的延迟和成本,也说明模型大幅减少了冗余代码和无效尝试。
Fable 5虽然单价更贵,但Token使用效率极高,速度也快了约15分钟。第一局:Fable 5完胜。
第二战:3D艺术博物馆——从概念到震撼的飞跃
一个野心勃勃的构想
这个项目的难度陡然上升:要求构建一个可缩放的交互式时间线,涵盖所有主要艺术时期,点击艺术家后进入3D画廊浏览其作品。数据需要从维基百科API实时拉取并存入Neon数据库。UP主特别强调:"不能是敷衍的Three.js演示,画廊要尽可能逼真,包括光照和色调映射。"
这里提到的Neon是一种Serverless PostgreSQL数据库服务,它将传统的PostgreSQL与云原生架构结合,支持按需扩缩容和数据库分支管理。AI模型需要从维基百科API拉取数据并存入Neon,这涉及API调用、数据清洗、数据库Schema设计、ORM映射等一系列后端工程能力。而Three.js则是目前最流行的WebGL封装库,它将底层的OpenGL ES着色器编程抽象为JavaScript API,让开发者可以用相对简洁的代码在浏览器中构建3D场景。文中提到的色调映射(Tone Mapping)是3D渲染管线中的关键环节,它将高动态范围(HDR)的光照计算结果映射到显示器能呈现的低动态范围(LDR),直接决定了画面是否真实自然。AI模型要生成可运行的Three.js代码,不仅需要理解场景图、相机、光源等概念,还要处理纹理加载、射线检测(用于鼠标点击交互)、动画循环等复杂逻辑——这远比生成普通网页代码困难得多。
Opus 4.8:有想法但执行崩溃
Opus 4.8做出了颜色编码的时间线视图,在组织和视觉层次上有一定水准。但致命问题出现了——画布移动和点击事件冲突,导致用户根本无法点击进入艺术家画廊。这是前端开发中经典的事件冒泡与捕获问题:当用户在可拖拽的画布上点击时,浏览器无法区分"拖拽"和"点击"意图,需要通过设置移动阈值或延迟判断来解决。Agent本该做的质量检查显然没有到位。核心功能缺失,等于项目失败。
Fable 5:令人窒息的完成度
Fable 5的表现堪称惊艳。时间线采用了类似星图的设计,艺术家根据生活年代重叠排列,缩小后变成小点,放大后展开详细信息——完美实现了"无限画布"的构想。这种语义缩放(Semantic Zooming)交互模式借鉴了信息可视化领域的经典理念,根据缩放层级动态调整信息密度,让用户在宏观概览和微观细节之间自由切换。
更令人震撼的是3D画廊体验:点击德加后进入其专属画廊,用户可以用鼠标拖拽或箭头键在虚拟空间中漫步,欣赏墙上的画作,点击任意一幅即可查看详细信息。所有数据来自维基百科,覆盖数百位艺术家、近千幅画作。
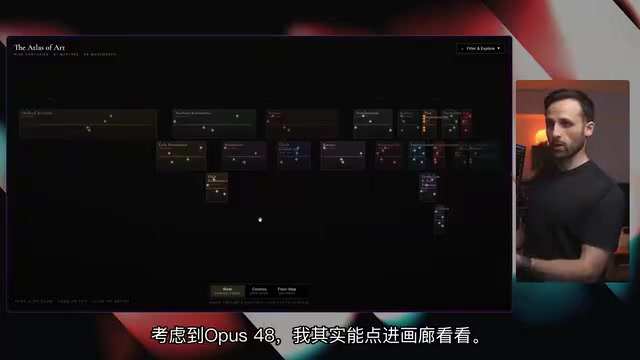
UP主的反应很真实:"太他妈酷了!想象一下小时候有这个,学习该多有趣!"这是他第一次看到AI模型能实现这种级别的细节和交互性。
成本与效率
| 指标 | Opus 4.8 | Fable 5 |
|---|---|---|
| 输入Token | 5.1万 | 5.4万 |
| 输出Token | 43.7万 | 28万 |
| 预估成本 | ~$46 | ~$64 |
Fable 5输出Token更少但成本更高(贵约37%),不过考虑到产出质量的天壤之别,这个溢价完全值得。有意思的是,Fable 5在构建过程中展现了出色的Agent协调能力——它能自主发现bug(如维基百科培根词条的歧义问题),甚至主动调整3D场景光照,这种"有主见"的行为是前所未见的。
所谓"Agent协调能力",指的是AI模型在Agentic编程模式下的表现。在这种模式中,模型不是一次性输出所有代码,而是像人类开发者一样迭代工作:编写代码、运行测试、发现问题、修复bug,形成完整的开发闭环。Fable 5能自主发现维基百科"培根"词条的歧义问题——画家弗朗西斯·培根(Francis Bacon, 1909-1992)与哲学家弗朗西斯·培根(Francis Bacon, 1561-1626)同名——说明模型具备了上下文推理和数据验证能力,而非盲目接受API返回的结果。这种自主纠错能力是AI从"代码生成工具"向"AI开发者"演进的关键标志。
第三战:帝国时代——差距变成鸿沟
终极挑战
最后一个项目要求在浏览器中构建一个可玩的帝国时代风格即时战略游戏:全3D世界、Three.js渲染、从城镇中心开始、有敌人攻击、完整的文明建造系统。UP主自己都"高度怀疑"能否接近原版水平。
帝国时代风格的即时战略(RTS)游戏是游戏开发中公认的高复杂度品类。它需要同时处理多个相互耦合的子系统:寻路算法(通常基于A*或流场寻路,需要在网格地图上为数十甚至数百个单位实时计算最优路径)、资源管理系统(食物、木材、石料、黄金的采集与消耗平衡)、建筑放置与碰撞检测、单位AI状态机(空闲、移动、攻击、采集等状态的切换逻辑)、战争迷雾、以及多实体的同步更新与渲染优化。即便是专业游戏团队,开发一个最小可玩的RTS原型也需要数周时间。
Opus 4.8:基本不可玩
Opus 4.8的输出只有一些色块,无法缩放、无法移动视角,建筑系统报错,整个应用几乎处于崩溃状态。UP主尝试了几分钟后放弃:"这个应用好像彻底崩了,我连在世界地图上移动都做不到。"
Fable 5:完成度远超预期
Fable 5生成的"黎明帝国"则完全是另一个次元的产物:低多边形(Low-Poly)卡通风格的3D世界,可以自由拖拽视角,单位可以移动和攻击,能建造农场和房屋,有敌方城镇中心,资源采集系统也在运作。低多边形风格是一种聪明的设计选择——它不仅降低了渲染复杂度,使游戏能在浏览器中流畅运行,还形成了独特的视觉美学,近年来在独立游戏领域广受欢迎。UP主惊呼:"这画面简直跟原版一模一样!Steam卖2.99都行!"
两个模型完成时间相近(Opus约33分钟,Fable约30分钟),但产出质量的差距已经不是"升级"能形容的——这是代际差异。
深度分析:Fable 5为何能碾压Opus 4.8
1. 图像生成的"审美意识"
Fable 5在电商项目中展现了惊人的图像提示能力——它不仅生成图片,还懂得用光影、纹理、色彩搭配来营造品牌美学。这说明模型对视觉设计有了更深层的理解。这种能力可能源于训练数据中包含了大量设计规范文档、品牌指南和UI/UX最佳实践,使模型内化了"好设计"的标准,而不仅仅是"能运行的代码"。
2. Agent协调与自主纠错
在3D博物馆项目中,Fable 5能自主发现维基百科数据的歧义问题,主动调整光照参数,甚至用Chrome扩展测试缩放交互。这种自主性远超传统的"生成-检查"流程。它表明Fable 5在Agent模式下具备了更强的"元认知"能力——不仅能执行任务,还能评估自己的执行结果并主动优化,这是向真正自主软件工程迈出的重要一步。
3. Token效率的质变
在多数测试中,Fable 5使用的输出Token明显少于Opus 4.8,但产出质量却大幅领先。这意味着模型不是在"堆量",而是在更精准地生成代码。从工程角度看,这类似于资深开发者与初级开发者的区别:前者能用更少的代码实现更好的效果,因为他们对问题域有更深的理解,知道哪些抽象是必要的,哪些代码可以省略。
4. 3D渲染能力的飞跃
从帝国时代的测试来看,Fable 5对Three.js的掌握已经达到了可以生成完整可玩游戏的水平,这在此前的任何AI模型中都未曾见过。这不仅涉及3D图形编程,还包括游戏循环设计(Game Loop)、实体组件系统(ECS)架构、碰撞检测、以及基本的游戏AI——这些知识跨越了图形学、软件工程和游戏设计多个领域,说明Fable 5的跨领域知识整合能力有了显著提升。
总结:AI编程能力的新标杆
三场测试,Fable 5三战全胜,而且每一场的优势都在扩大。从电商网站的"更精致",到3D博物馆的"质的飞跃",再到帝国时代的"代际碾压",Fable 5展现了当前AI编程能力的新上限。
当然,这些测试也有局限性——都是前端密集型项目,且只进行了一次构建,没有涉及后端分布式系统、数据库性能优化、安全审计等企业级开发场景。但确实的是,Fable 5在设计审美、代码质量、Agent协调、3D渲染等维度上都树立了新标杆。对于开发者而言,这意味着AI辅助开发正在从"能用"走向"好用",从"生成代码"走向"生成产品"。
唯一需要关注的是成本——Fable 5按使用量计费后价格约贵30-37%,但考虑到产出质量和效率的提升,这个溢价对大多数项目来说是值得的。更重要的是,随着模型能力的提升,AI编程的ROI计算方式正在改变:衡量标准不再是"每Token成本",而是"每个可交付产品的成本"——在这个维度上,Fable 5反而可能是更经济的选择。
相关推荐
Codex中自由切换Claude/DeepSeek等AI模型:CPA部署实战
详解如何通过CLI Proxy API(CPA)将Claude、DeepSeek、Grok、Gemini等多家AI模型聚合到OpenAI Codex中使用,涵盖VPS部署、Docker安装、管理面板配置及Codex++连接的完整流程。
Codex vs Claude Code:AI编程代理深度对比
深度对比Codex、Claude Code和Cursor三大AI编程代理的定价、功能、GitHub集成与团队协作能力,从底层模型成本到实际开发体验,帮助开发者选出最适合自己的AI编程工具。

7.9元用上Claude Code:国产模型平替配置全攻略
详解Claude Code安装配置与国产模型平替方案,通过硅基流动、DeepSeek等服务商,低至7.9元即可体验终端级AI编程助手,附环境变量配置教程与常见踩坑指南。