Fable 5发布:专为复杂软件工程打造的AI编程工具
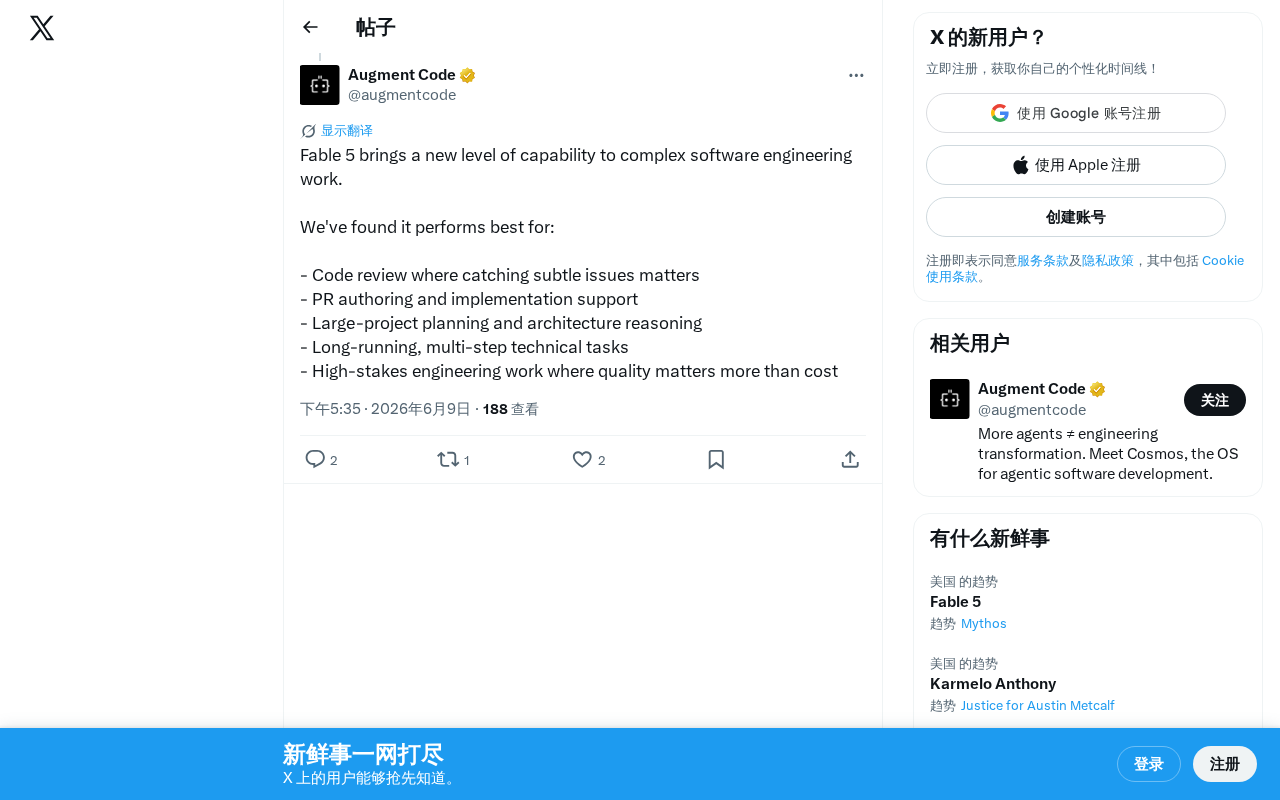
Fable 5 正式亮相:瞄准高难度软件工程场景
AI编程工具赛道又迎来一位新选手。近日,Fable团队在社交媒体上正式发布了Fable 5,宣称其为复杂软件工程工作带来了"全新水平的能力"。与市面上众多追求通用性的AI编码助手不同,Fable 5明确将自身定位于高质量、高复杂度的工程任务,而非简单的代码补全。
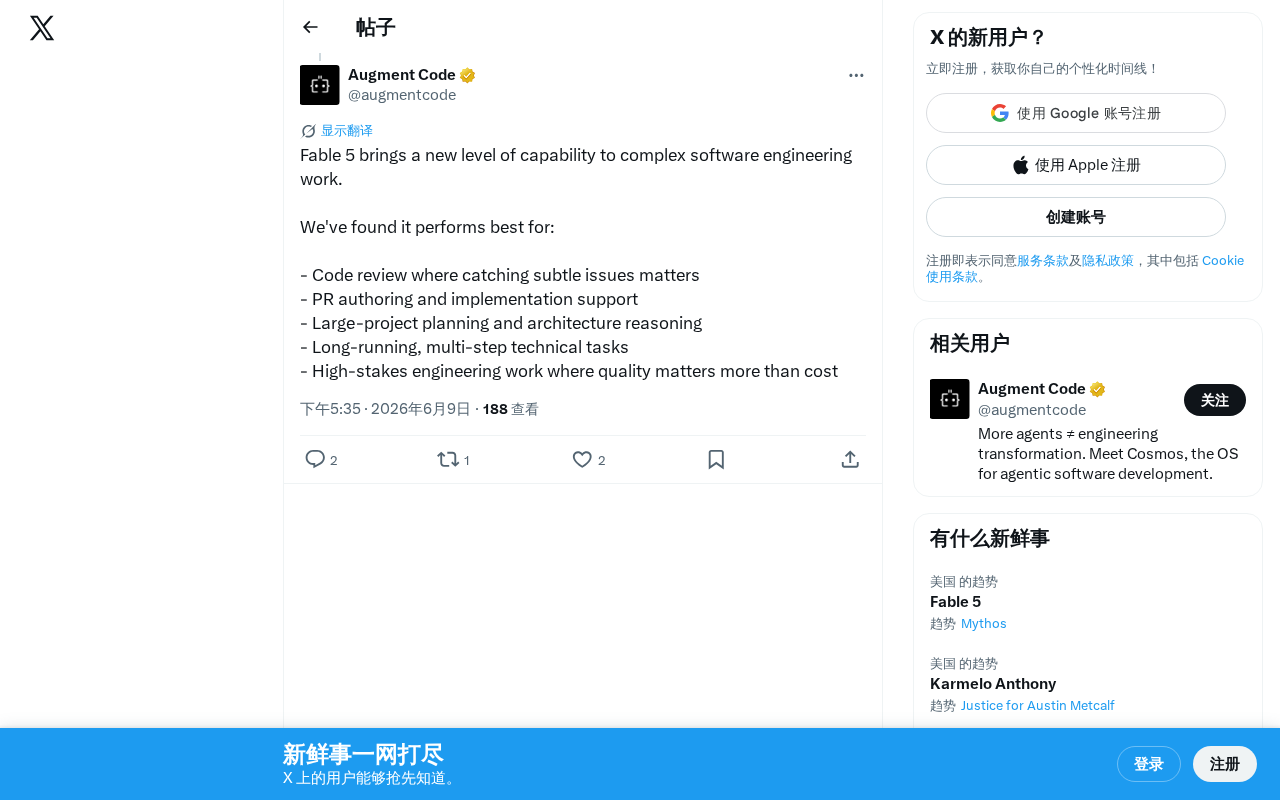
五大核心能力:从代码审查到架构推理
根据官方公布的信息,Fable 5在以下五个场景中表现最为突出:
1. 代码审查:捕捉微妙问题
Fable 5强调其在代码审查(Code Review)中的能力,尤其擅长捕捉那些容易被人眼忽略的微妙问题。它不仅仅做语法检查或风格规范校验,而是能够理解代码逻辑深层的潜在缺陷——比如边界条件遗漏、并发竞态、隐含的性能瓶颈等。这类能力对于大型团队协作中的质量把控至关重要。
代码审查作为软件工程的核心实践之一,其历史可追溯至1970年代IBM的Fagan检查法(Fagan Inspection),这是最早的系统化代码检查方法论。现代代码审查通常通过Pull Request机制在版本控制平台上进行,研究表明人工审查平均能发现60-70%的缺陷,但审查质量高度依赖审查者的经验和注意力。竞态条件(Race Condition)和边界条件遗漏尤其难以通过人工审查发现,因为它们需要对程序执行的时序和状态空间进行系统性推理——一个包含多线程交互的模块可能有数百万种可能的执行序列,人脑几乎不可能穷举所有情况。传统的静态分析工具(如SonarQube、CodeQL、Coverity)虽然能检测部分模式化问题,但对语义层面的逻辑缺陷检测能力有限,误报率也居高不下。Fable 5试图在这一能力维度上实现突破,将深层语义理解引入自动化审查流程,这意味着它需要具备对代码意图(而非仅仅是代码文本)的理解能力。
2. PR编写与实现支持
Pull Request(PR)的编写和实现支持是Fable 5的另一个重点方向。在实际开发流程中,PR不仅需要代码变更,还需要清晰的描述、合理的拆分和完整的测试覆盖。Fable 5能够辅助开发者完成从PR描述撰写到具体代码实现的全流程,直接提升团队协作效率。
PR机制最早由GitHub在2008年推广开来,如今已成为现代软件开发协作的核心工作流,几乎所有规模化的开发团队都采用某种形式的PR流程。Google的工程实践研究显示,PR的大小与审查效率呈负相关——超过400行变更的PR,审查质量会显著下降,审查者的注意力在20-30分钟后开始衰减。因此,合理的PR拆分(将大型变更分解为逻辑独立的小PR)本身就是一项重要的工程技能,需要对变更的依赖关系和逻辑边界有清晰的认知。一个优秀的PR还应包含清晰的动机说明、变更影响分析、测试策略描述以及对审查者的引导信息。当前AI工具在PR辅助方面的尝试包括GitHub Copilot的PR Summary自动生成功能、Graphite的PR堆叠管理,以及各类变更影响分析工具,但从PR规划、拆分策略到完整实现的端到端支持仍处于早期阶段。Fable 5在这一方向上的深入,意味着它试图覆盖开发者日常工作流中更完整的环节,将AI的辅助从"写代码"延伸到"管理变更"。
3. 大型项目规划与架构推理
大型项目规划与架构推理是Fable 5最引人注目的能力之一。当前大多数AI编程工具擅长处理函数级别或文件级别的任务,但在涉及整个项目架构设计、模块划分、技术选型等宏观层面的推理时往往力不从心。Fable 5声称能够胜任这一层级的工作,如果确实如此,这将是AI编程工具在能力边界上的一次重要突破。
软件架构推理之所以困难,在于它需要综合考虑功能需求、非功能需求(性能、可扩展性、可维护性、安全性)、团队能力、技术债务、组织结构等多维因素,并在多个权衡(trade-off)之间做出判断。正如Conway定律所揭示的,系统架构往往反映组织的沟通结构,这意味着架构决策不仅是技术问题,还涉及组织动力学。当前大语言模型面临的核心技术挑战是上下文窗口限制——一个中型项目可能包含数十万行代码和数百个文件,远超单次推理的token容量(即使是最新的百万token窗口模型,也难以完整加载一个大型代码库)。此外,架构决策往往没有唯一正确答案,需要超越模式匹配的深层推理能力,需要理解"为什么这样设计"而非仅仅"别人怎样设计"。业界目前的探索方向包括代码图谱构建(将代码库表示为调用图、依赖图等结构化形式)、分层摘要(对不同粒度的代码单元生成语义摘要)和检索增强生成(RAG,根据当前任务动态检索相关代码片段)等技术。Fable 5很可能在这些方向上有所创新,或者采用了某种新颖的代码库理解和表示方法。
4. 长周期多步骤技术任务
软件工程中的许多任务并非一步完成,而是需要多个步骤的连续推理和执行。例如,一次大规模的代码重构可能涉及依赖分析、接口修改、测试更新等多个环节。Fable 5针对这类长周期、多步骤任务进行了专门优化,具备更强的上下文保持能力和任务分解能力。
这类任务对AI系统提出了两个核心技术挑战:一是上下文保持(Context Retention),即在多轮交互或长序列推理中维持对先前信息的准确记忆,避免"遗忘"早期步骤中的关键约束和决策;二是任务分解(Task Decomposition),即将复杂目标拆解为可执行的子任务序列,并正确处理子任务之间的依赖关系。在大规模重构场景中,系统需要首先构建依赖图(Dependency Graph),识别变更的传播路径——例如修改一个接口定义可能影响数十个调用方——然后按拓扑顺序逐步执行修改,同时确保每一步的中间状态仍然保持系统的编译和测试通过(即所谓的"绿色重构"原则)。这类能力与当前热门的Agent架构密切相关——通过规划(Planning)、执行(Execution)、反思(Reflection)的循环来完成复杂任务。这一范式源自认知科学中的"目标-手段分析"理论,在AI领域被具象化为ReAct(Reasoning + Acting)等框架。OpenAI的o1/o3系列推理模型通过链式思维(Chain-of-Thought)增强了多步推理能力,Anthropic的Claude通过工具使用和长上下文支持复杂任务,而Devin、SWE-Agent等编程Agent则通过与开发环境的交互(执行命令、读写文件、运行测试)来完成端到端的工程任务。Fable 5在这一方向上的优化,可能涉及更高效的状态管理机制和更精确的任务规划算法。
5. 高风险工程场景
最后一点尤为值得关注:Fable 5明确表示适用于"质量比成本更重要"的高风险工程场景。这一定位暗示其可能采用更大规模的模型或更复杂的推理流程,在推理成本上可能高于竞品,但换来的是更高的输出质量和可靠性。
在金融交易系统、医疗设备软件、航空航天控制系统、自动驾驶等领域,一个微小的代码缺陷可能导致数百万美元的损失甚至危及生命安全。2012年Knight Capital因软件缺陷在45分钟内损失4.4亿美元,波音737 MAX的MCAS系统缺陷导致两起空难,这些案例深刻说明了高风险场景中代码质量的极端重要性。这些场景对代码质量的要求远高于普通应用开发,传统上依赖严格的形式化验证(如模型检验、定理证明)、多轮人工审查(通常需要3-5位资深工程师独立审查)、大量测试(包括单元测试、集成测试、模糊测试、变异测试等)以及DO-178C(航空)、IEC 62304(医疗)等行业认证标准来保障。Fable 5瞄准这一市场,意味着它需要在输出的准确性和可靠性上达到极高标准——不仅要生成正确的代码,还要避免引入新的缺陷。同时,它可能需要提供可解释性(Explainability)——让开发者理解AI的推理过程和决策依据,因为在这些领域,"AI说这样做"不足以作为工程决策的依据,审计和追溯能力是合规要求的一部分。
市场定位分析:与Cursor、Copilot的差异化竞争
从Fable 5的功能描述来看,其市场策略非常清晰——不与Cursor、GitHub Copilot等工具在日常编码辅助的红海中竞争,而是瞄准企业级、高复杂度的软件工程场景。
当前AI编程工具市场已形成多层次竞争格局。第一梯队是以GitHub Copilot(基于OpenAI Codex/GPT-4,月活用户超过130万)和Cursor(集成多模型的智能IDE,2024年估值已超过25亿美元)为代表的通用编码助手,主要服务于日常代码补全和生成场景。第二梯队是以Devin(Cognition Labs开发,号称"首个AI软件工程师")、SWE-Agent(普林斯顿大学开源项目)、OpenHands为代表的自主编程Agent,试图独立完成完整的开发任务。第三梯队则是面向特定场景的垂直工具,如Snyk(安全漏洞扫描)、Qodo/CodiumAI(测试生成)、Sourcegraph Cody(代码搜索与理解)等。在基准测试方面,SWE-bench已成为评估AI编程能力的行业标准之一,它包含来自12个真实GitHub开源仓库(如Django、scikit-learn、sympy等)的2294个软件工程问题,要求AI系统理解问题描述并生成正确的代码补丁。当前最优模型在SWE-bench Verified子集上的解决率约为50-55%左右,这意味着仍有近一半的真实工程问题超出了AI的能力范围。Fable 5的定位似乎介于自主Agent和垂直工具之间,聚焦于高复杂度工程场景的深度能力,走"少而精"而非"广而浅"的路线。
这种定位有其合理性。随着AI编程工具的普及,简单的代码补全和生成已经趋于同质化,真正的差异化价值在于能否处理更复杂、更关键的工程任务。架构级推理、跨文件的代码审查、多步骤任务编排——这些恰恰是当前AI编程工具的短板所在。
不过,Fable 5目前公开的信息仍然有限。官方尚未披露具体的技术架构、底层模型选择(是自研模型还是基于现有基础模型的微调和增强)、定价策略以及实际的基准测试数据。对于"质量比成本更重要"这一表述,开发者社区也需要更多实际案例来验证其真实表现——毕竟在AI领域,宣传与实际能力之间往往存在差距。
展望:AI编程工具从"写代码"迈向"做工程"
Fable 5的发布反映了AI编程工具领域的一个重要趋势:从"写代码"向"做工程"的能力跃迁。未来的AI编程助手不仅要能生成代码片段,更要能理解项目全局、参与架构决策、保障工程质量。这一趋势的背后是大语言模型推理能力的持续提升(从GPT-3.5到GPT-4再到o1/o3,推理能力呈阶梯式增长),以及Agent框架在工程实践中的逐步成熟。
从更宏观的视角来看,软件工程的本质不仅是编写代码,更是管理复杂性。Fred Brooks在1986年的经典论文《没有银弹》以及更早的《人月神话》(1975年)中提出的"本质复杂性"(Essential Complexity)与"偶然复杂性"(Accidental Complexity)的区分至今仍然适用。偶然复杂性源于工具和语言的不完善——如手动内存管理、冗长的样板代码、复杂的构建配置等;本质复杂性则源于问题域本身的固有难度——如业务规则的内在矛盾、分布式系统的一致性挑战、需求的持续演化等。AI工具已经在消除偶然复杂性方面取得显著进展(代码补全消除了打字负担,自动生成消除了样板代码,智能重构消除了机械性修改),而Fable 5等新一代工具正试图触及本质复杂性的边界,即帮助开发者应对系统设计、模块交互和长期演化中的根本挑战。Brooks当年断言"没有任何单一技术或管理进步能在十年内将软件生产力提升一个数量级",而AI是否能打破这一预言,正是当前行业最令人期待的悬念之一。
对于关注AI编程领域的开发者而言,Fable 5值得持续关注。其在复杂工程场景中的实际表现,将是检验这一代AI编程工具能力上限的重要参考。
相关推荐
Claude Code安装教程与AI编程工具五大发展阶段全解析
详解Claude Code安装配置全流程,梳理AI编程工具从手动编码到智能体的五个发展阶段,分析0到1项目构建优势与1到100迭代挑战,帮助开发者快速上手AI编程。

企业级AI项目Rules文件:5条硬规矩+6个写法门道
AI编程项目总被AI乱改代码?本文分享企业级Rules文件的5条硬规矩和6个写法门道,涵盖Claude Code、Cursor等工具的规则文档写法,附三类项目Rules模板,让AI按你的规矩稳定交付。
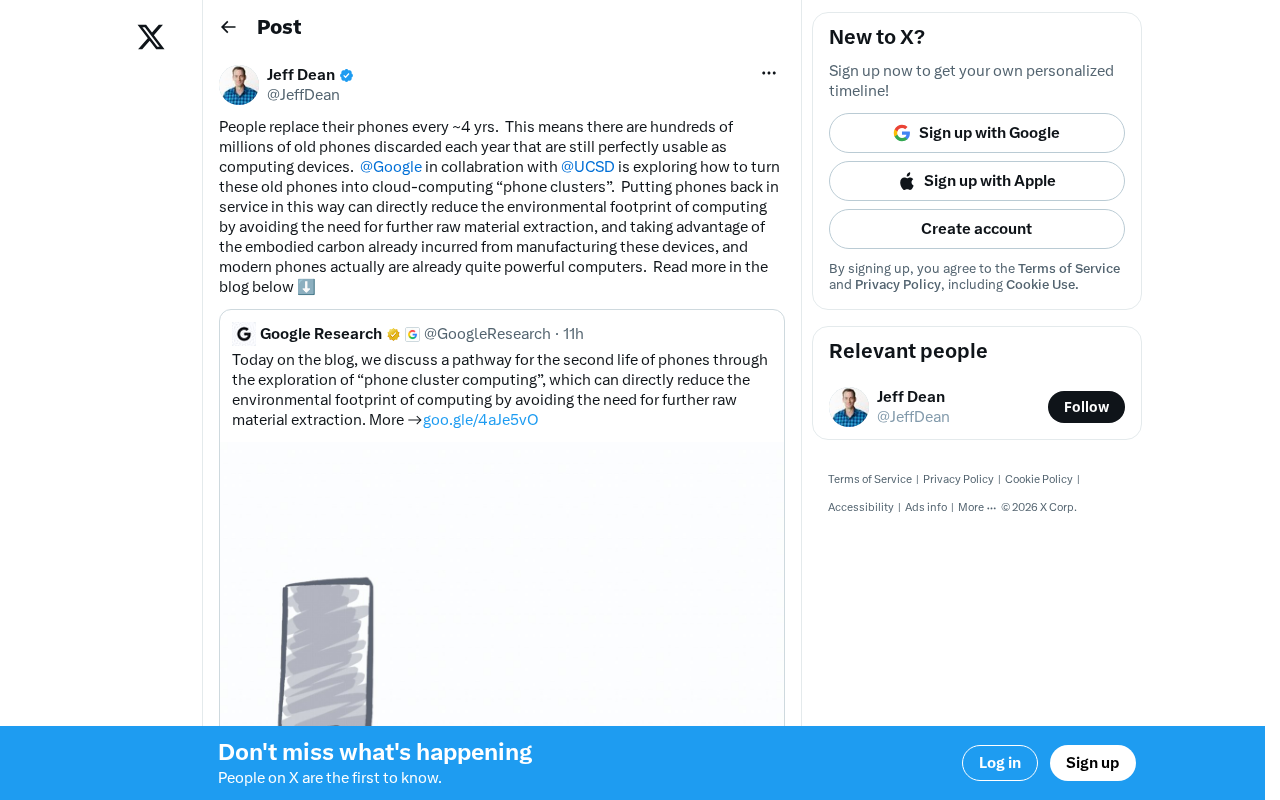
旧手机组建云计算集群:谷歌联合UCSD探索可持续计算新路径
谷歌与UCSD合作探索将旧手机组建为云计算集群,利用手机的ARM芯片高能效比优势,减少电子废弃物和数据中心碳足迹。本文分析手机集群的技术可行性、环境效益及在边缘计算、联邦学习等场景的应用前景。