Claude Fable 5编程实测:三个硬核任务全过,附混合省钱方案
Anthropic 发布 Claude Fable 5 仅两天,就有开发者拿出了三个从简单到复杂的真实任务对其进行压力测试。结果令人意外——三个任务全部一次通过,而 API 费用合计仅十几美元。更关键的是,当前正处于一个限时免费窗口期,错过就要按量付费了。
任务A:一句话需求生成三维世界
第一个测试是最直观的:仅用一句话描述需求,让 Fable 5 生成一个可交互的三维场景。
结果是,16分49秒内,模型交出了 750行原生 WebGL 代码。测试者原本只要求四种材质,模型给出了13种,还自带真实阴影和昼夜循环系统,打开浏览器就能直接运行。
这里需要理解一个关键背景:WebGL(Web Graphics Library)是一种基于 OpenGL ES 的 JavaScript API,允许开发者在浏览器中直接渲染高性能的 2D 和 3D 图形,无需安装任何插件。与 Three.js 等封装库不同,原生 WebGL 代码需要开发者直接操作着色器(Shader)、顶点缓冲区和纹理映射等底层图形管线概念,编写难度显著更高。
具体来说,一段完整的 WebGL 程序需要经历着色器源码编写、编译、链接为程序对象、配置顶点属性指针(Vertex Attribute Pointer)、创建并绑定帧缓冲区(Framebuffer)等一系列严格有序的步骤,任何一步出错都会导致整个渲染管线静默失败——浏览器不会报出明确的错误信息,只会显示一块黑屏。而模型生成的昼夜循环系统更增加了复杂度:它需要在每一帧动态更新光源方向向量、对环境光(Ambient)、漫反射(Diffuse)和镜面反射(Specular)三个分量进行参数插值,并同步更新阴影贴图(Shadow Map)的光源视角矩阵。这意味着模型不仅掌握了 GLSL 着色器语言和矩阵变换,还理解了实时光照模型的完整数学框架。
750 行无报错的原生 WebGL 代码意味着模型不仅理解了 JavaScript 语法,还掌握了 GLSL 着色器语言、矩阵变换、光照模型等计算机图形学的核心知识。
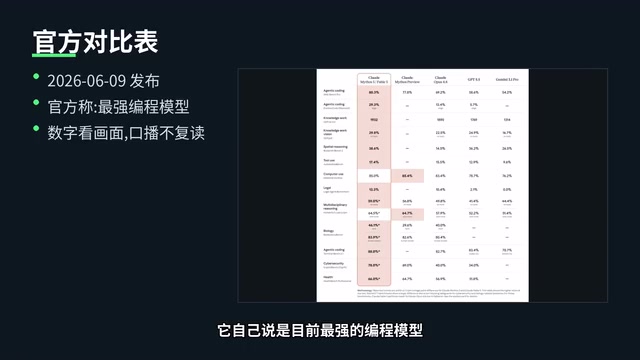
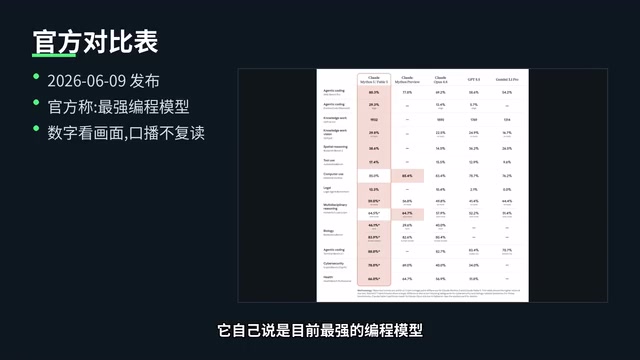
从官方放出的对比表来看,Fable 5 自称是目前最强的编程模型。抛开官方宣传不谈,仅从这个任务的输出质量来看,750行无报错的 WebGL 代码、超出预期的材质数量、以及开箱即用的完整度,确实展现了相当强的代码生成能力。
任务B:真实代码仓库的Bug修复
第二个任务跳出了"玩具场景",直接用真实的代码仓库(repo)进行测试。这才是检验编程模型实际价值的关键——能不能在复杂的现有代码库中定位并修复问题。
在软件工程实践中,真实代码仓库与人为构造的编程题有本质区别。真实仓库通常包含数十甚至数百个文件、复杂的模块依赖关系、历史遗留代码和隐式的业务逻辑约定。传统的 AI 编程助手在这类场景中往往表现不佳,因为它们需要理解跨文件的上下文关联和项目的整体架构意图。
为了量化 AI 在真实仓库中的表现,学术界和工业界已经建立了专门的基准测试。其中最具代表性的是 SWE-bench,它从 GitHub 上的真实开源项目中提取了数千个已解决的 Issue,要求 AI 模型在完整的代码仓库上下文中自主定位问题文件、理解修复意图并生成正确的补丁。截至 2025 年初,即使是最强的 AI 编程系统在 SWE-bench 的完整测试集上的通过率也仅在 50% 左右,而在更严格的 SWE-bench Verified 子集上,许多模型的表现还会进一步下降。AI 编程助手在真实仓库中的典型失败模式包括:修改了错误的文件、只处理了表面症状而未触及根因、生成的补丁引入了新的回归 bug、以及无法理解项目特有的编码约定和架构模式。
测试结果:Fable 5 在 87秒内 完成了以下操作:
- 自主运行测试,还原了 bug 的触发条件
- 定位根因:找到了时区处理的数据源头问题
- 修复方式正确:修的是数据源头,而不是在展示端做表面修补
- 额外收获:顺手发现并清理了一个过时接口的潜在隐患
这个任务最能体现 Fable 5 的工程理解力。它没有简单地"头痛医头",而是沿着数据流追溯到源头进行修复,这是有经验的开发者才会采取的策略。在软件工程中,这种方法被称为"根因修复"(Root Cause Fix),与之相对的是"症状修复"(Symptomatic Fix)——后者虽然能暂时解决问题,但往往会在其他地方引发新的 bug,甚至埋下更深层的技术债务。值得一提的是,时区处理本身就是软件工程中臭名昭著的"地雷区":不同数据库、编程语言和框架对时区的默认处理方式各不相同,UTC 偏移量、夏令时转换、时区数据库版本差异等因素交织在一起,使得时区相关的 bug 往往具有极强的隐蔽性和传播性。模型能在 87 秒内穿透这些复杂性直达根因,确实令人印象深刻。
任务C:教科书级物理耦合模拟
第三个任务是难度天花板:刚体 + 布料 + 流体的三项耦合模拟。这在计算机图形学中属于教科书级别的难题,因为三种物理系统之间的相互作用极其复杂。
具体来说,刚体(Rigid Body)、布料(Cloth)和流体(Fluid)分别属于三种截然不同的物理模拟范式。刚体模拟基于牛顿力学和碰撞检测;布料模拟通常采用质点-弹簧模型或有限元方法,需要处理大量约束条件;流体模拟则常用 SPH(光滑粒子流体动力学)或欧拉网格法。三者的耦合意味着它们之间必须实时交换力和位移信息——例如流体推动布料、布料包裹刚体、刚体搅动流体——这会导致数值稳定性问题急剧恶化。
在技术实现层面,三项耦合模拟面临的核心挑战是时间步长同步和数值稳定性。刚体、布料和流体各自的最优时间步长往往差异巨大:刚体碰撞检测可能需要极小的时间步长来避免穿透(Tunneling),布料模拟中的弹簧系统在大步长下容易发散(尤其是显式积分方法),而流体模拟则受 CFL 条件(Courant-Friedrichs-Lewy Condition)约束——粒子在单个时间步内的移动距离不能超过网格单元尺寸,否则模拟会立即崩溃。工业界的常见做法是采用隐式积分(Implicit Integration)来换取更大的稳定时间步长,但这需要求解大规模稀疏线性方程组,计算成本极高。在专业工作室中,一个稳定的三项耦合模拟系统通常需要图形学工程师数周甚至数月的开发和调试时间。
在工业界,这类耦合模拟通常由 Houdini、NVIDIA PhysX 等专业引擎处理,能用纯代码一次性生成并稳定运行在 60 帧,确实是极高难度的任务。

你可能没注意到,Fable 5 在生成的文件头部主动声明了"未经运行验证"。这种诚实的自我标注是一个好信号——模型清楚自己的能力边界。
但实际验证结果是:14分13秒,一把过,稳定60帧。模型的"谦虚"声明和实际表现形成了有趣的反差。
成本分析:三个任务仅十几美元
三个任务的 API 费用合计仅 十几美元,不是几百,是十几美元。对于这个级别的代码输出量和质量来说,性价比相当惊人。

但更重要的是当前的窗口期策略:
- 6月22日之前:Pro 和 Max 订阅用户可以直接使用 Fable 5,不额外收费
- 6月23日起:转为按量计费
这意味着现在是零边际成本体验 Fable 5 的最佳时机。
窗口期之后的省钱方案:Claude Fable 5 + DeepSeek 混合分工
免费期结束后,高强度用户可以考虑一个实用的混合策略:
- Claude Fable 5:负责架构设计和复杂逻辑推理
- DeepSeek V4:承担重复性的大量代码实现
这不是替代关系,而是分工协作。这种策略背后的逻辑是:架构设计和复杂推理对模型的"智力上限"要求极高,适合用最强模型处理;而大量的样板代码编写、单元测试生成、文档补全等任务,对模型能力的要求相对较低,用成本更低的模型即可胜任。
从经济学角度来看,这种混合分工的收益非常显著。以典型的中型项目为例,架构设计和核心逻辑编写通常只占总代码量的 15%-25%,而样板代码、CRUD 接口、配置文件、测试用例等重复性工作占到了 60%-75%。如果将高价模型的使用严格限制在前者,而将后者交给成本更低的模型,整体 API 支出可以降低 50% 以上。这种"分层调度"的思路在云计算领域并不新鲜——它本质上类似于 AWS 的计算实例分级策略:关键任务用高性能实例,后台批处理用低成本的 Spot 实例。AI 编程工具的成熟用户正在将同样的成本优化思维应用到模型选择上。
切换方式也很简单——只需修改两行环境变量,用 OpenRouter 的 key 就能直接调用 DeepSeek,连单独注册账号都不需要。OpenRouter 是一个 AI 模型聚合网关,它提供统一的 API 接口来访问多家厂商的大语言模型,包括 Anthropic 的 Claude 系列、DeepSeek、Meta 的 Llama 等。开发者只需持有一个 OpenRouter API Key,就能通过修改请求中的模型名称参数来切换不同的底层模型,而无需分别注册各家平台的账号和管理多套密钥。这种聚合网关模式的另一个隐藏优势是故障转移(Failover):当某家模型提供商出现服务中断时,开发者可以在几秒内切换到备选模型,而无需修改任何业务代码。如果想要图形化界面,还有一个开源工具叫 CC Switch 可以使用。
不过有一个坑需要注意:不要通过询问模型"你是谁"来确认切换是否成功。测试者实测了两次,模型一次自称是 Fable 5,一次才老实承认是 DeepSeek。
这个现象涉及大语言模型的一个已知局限:模型的自我身份认知并不可靠。大语言模型的回答是基于训练数据中的统计模式生成的,当被问及"你是谁"时,模型可能会根据对话上下文、系统提示词(System Prompt)甚至用户的措辞倾向来"迎合"回答,而非反映真实的模型身份。这种现象的技术根源在于 RLHF(基于人类反馈的强化学习)训练过程:模型在训练阶段被反复强化"以特定身份回答问题"的行为模式,但这种身份绑定是通过系统提示词实现的软约束,而非硬编码在模型权重中的固有属性。当模型通过 OpenRouter 等第三方网关被调用时,系统提示词可能被替换或缺失,导致模型的"身份锚点"变得模糊。此外,如果对话上下文中频繁出现某个模型的名称(例如用户反复提到 Claude),模型会倾向于在统计层面"顺着"这个上下文生成回答,从而产生身份冒充的假象。
正确的验证方式是看左下角状态栏,以及后台账单记录——账单不会骗人。API 返回的模型标识字段和计费记录中的模型名称才是客观可靠的判断依据。
总结与行动建议
Fable 5 在编程能力上确实展现了顶级水准:从简单的一句话需求到复杂的物理耦合模拟,三个难度递增的任务全部一次通过。更难得的是,它在真实代码库中的 bug 修复表现出了工程级的理解深度。
行动建议:
| 用户类型 | 建议 |
|---|---|
| 已有 Pro/Max 订阅 | 6月22日前尽快体验,零额外成本 |
| 高强度开发者 | 6月23日后走 Claude Fable 5 + DeepSeek 混合路线 |
| 轻度用户 | 可以观望,等社区沉淀更多最佳实践 |
窗口期有限,值得尽早动手验证。
相关推荐
AI Agent核心架构拆解:从概念到企业级智能体搭建
深度解析AI Agent智能体的三大核心架构:感知模块、大脑模块与行动模块,详解RAG记忆系统、工具调用机制及Chain of Thought推理能力,附企业级智能体开发技能路线图。
200行Python代码从零搭建AI Agent智能体实战教程
用200行Python代码从零搭建AI Agent智能体,逐步拆解提示词、记忆、工具调用、RAG检索增强和Skill技能五大核心模块,适合Python开发者快速入门Agent开发。
Anthropic撤回Claude隐形限制AI研究者的争议政策
Anthropic因Claude Fable/Mythos模型隐形限制前沿LLM开发请求的政策遭社区强烈反对后迅速撤回。本文详解事件始末、隐形安全措施的争议本质、Anthropic的修正方案及对AI行业透明度的深远启示。