Frontier Code深度解析:代码能跑≠能合并,编程基准测试迎来质量革命
编程基准测试的根本缺陷:通过测试≠可合并
Cognition 最近发布了一项名为 Frontier Code 的全新编程基准测试,其核心理念直击当前编程评测的痛点——大多数基准测试只关心模型生成的代码能否通过测试,而 Frontier Code 则追问一个更严苛的问题:项目维护者是否愿意合入这个 PR?
在现代软件开发中,Pull Request(PR)是协作工作流的核心机制。开发者完成代码修改后,不会直接将代码推送到主分支,而是创建一个 PR 请求项目维护者审查并合入。维护者会从代码风格、架构一致性、测试覆盖、性能影响等多个维度进行审查,不合格的 PR 会被要求修改甚至直接关闭。在大型开源项目中,PR 的合入率通常远低于提交率,这使得「可合并性」成为比「功能正确性」更高的质量标准。
这个差异至关重要。一个补丁即便能通过所有现有测试,质量也可能很差:改动范围过大、修改了无关文件、加入低质测试、忽略代码风格,或者虽然解决了眼前问题却导致后续维护更加困难。这类代码在实际的代码审查中往往会被维护者直接拒绝,但传统编程基准测试对此视而不见。
评估体系:三级嵌套子集与双重指标
Frontier Code 包含三个嵌套子集,覆盖不同难度梯度:
- Extended:完整基准,包含 150 个任务,涵盖较简单的任务
- Main:其中最难的 100 个任务
- Diamond:最严苛的 50 个任务
测试报告包含两个核心指标:通过率和评分。通过率是二元判定——只要有一项「阻碍性因素」(维护者视为硬性红线的问题)未满足,该次尝试即判定为失败。评分则是各项评估标准的加权总和,但关键在于:如果方案未能满足任何一项阻碍性因素,得分直接归零。
每个模型在各级推理力度下运行五次取平均值,图表显示的是该模型表现最好的推理力度设置。
Diamond级结果:最强模型也仅勉强及格
在最严苛的 Diamond 子集中,结果令人清醒:
| 模型 | 评分 | 通过率 |
|---|---|---|
| Claude 3.5 Sonnet | 13.4% | 14.5% |
| GPT-4o | 6.3% | 7.2% |
| Claude 3.0 Opus | 5.2% | — |
| Gemini 1.5 Pro | 4.7% | — |
| GPT-4o Mini | 4.6% | — |
| Kimi K2.6 | 3.8% | — |
即便是表现最佳的模型,也仅能解决极小部分任务。这正是该基准测试的设计初衷——难度最高的 50 项任务远未达到饱和。
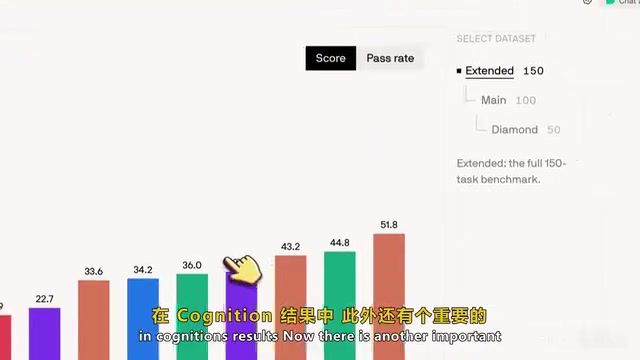
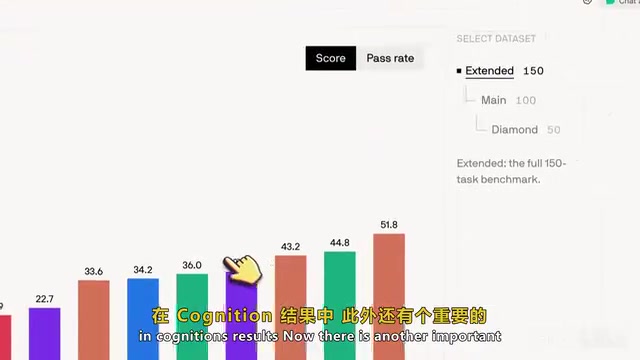
值得关注的是效率维度。Claude 3.5 Sonnet 虽然在 Diamond 级拿到了最高分,但代价不菲:每次运行约消耗 7 万输出 Token,平均成本约 8 美元,单次推演耗时约 7.7 分钟,需要约 83 次工具调用。在大语言模型的使用中,Token 是计费和衡量计算量的基本单位,一个 Token 大约对应英文中的 3/4 个单词或中文中的 1-2 个字符。输出 Token 的成本通常是输入 Token 的 3-6 倍,因为生成过程需要逐 Token 进行自回归推理。当编程智能体处理复杂任务时,它需要多次调用工具(如读取文件、执行命令、搜索代码库),每次交互都会累积 Token 消耗。7 万输出 Token 对应约 8 美元的成本,在企业级大规模部署场景下会迅速累积为可观的开支,因此 Token 效率成为评估编程智能体实用性的关键维度。相比之下,GPT-5.5 虽然得分稍低,但 Token 消耗量缩减到了原来的四分之一以下。这意味着在成本与性能之间存在明确的权衡取舍。
另一个需要注意的细节是:并非所有模型都使用相同的测试环境。OpenAI 模型使用 Codex,Gemini 模型对应 Gemini CLI,开源模型采用 Mini Agent,Devon 则用于 SWE-Bench。因此该基准衡量的是模型与智能体环境的综合表现。
旧基准为何不够好:误报率与漏报率对比
在编程基准测试的语境下,误报(False Positive)和漏报(False Negative)的概念借鉴自统计学中的假设检验框架。误报是指基准测试采纳了一个实际上错误的方案(通常因测试覆盖不全),漏报则是指基准测试拒绝了实际上正确的方案(通常因测试要求过于僵化)。高误报率意味着基准测试会「放行」有缺陷的代码,让人对模型能力产生过高估计;高漏报率则意味着基准测试过于僵化,会拒绝那些采用了不同但同样正确的实现方式的方案,导致低估模型的真实水平。理想的基准测试应同时将两者控制在较低水平。
| 基准测试 | 误报率 | 漏报率 |
|---|---|---|
| SWE-Bench Pro | 36.0% | 6.8% |
| DeepSuite | 44.9% | 1.2% |
| TerminalBench 2.0 | 6.8% | 5.9% |
| TerminalBench 2.1 | 5.6% | 2.8% |
| Frontier Code | 6.9% | — |
Frontier Code 的误报率相比 SWE-Bench Pro 降低了约 81%(从 36.0% 降至 6.9%)。值得一提的是,SWE-Bench 是由普林斯顿大学研究团队于 2023 年推出的编程智能体基准测试,基于真实 GitHub 仓库中的 Issue 和对应的 PR 构建,要求模型根据 Issue 描述自动生成代码补丁并通过仓库的测试套件验证。SWE-Bench 的出现标志着编程评测从算法竞赛式的题目转向真实软件工程场景,后续衍生出 SWE-Bench Lite、SWE-Bench Verified、SWE-Bench Pro 等变体,逐步提升评测的严谨性和难度,但其核心评判标准仍以测试通过为主——这正是 Frontier Code 试图超越的局限。虽然 Frontier Code 也并非完美无缺,依然存在误报和漏报,但其错误率显著低于早期基准测试。
语言覆盖与提示词设计的关键差异

Frontier Code Extended 的 150 个任务覆盖了更广泛的编程语言:TypeScript(19%)、JavaScript(15%)、C/C++(15%)、Python(13%)、Java(13%)、Go(10%)等。相比之下,SWE-Bench Pro 高度集中于 Python(36%)、Go(38%)和 TypeScript(19%)。语言多样性至关重要,因为编程智能体在不同生态系统下的表现可能大相径庭——不同语言有着截然不同的类型系统、包管理机制、构建工具链和社区编码规范,模型在 Python 生态中积累的能力未必能迁移到 C++ 或 Java 的复杂构建环境中。
在提示词长度方面,SWE-Bench Pro 的中位数为 30,098 个字符,而 Frontier Code 仅任务描述部分的中位数只有 9,082 个字符——仅为前者的三分之一。这意味着模型必须在更少的直接指令下推断出更多意图,同时仍需遵循仓库的通用标准。
补丁大小方面,Frontier Code 涉及约 6 个文件的修改,但代码行数中位数并不极端。它并非靠增大补丁来制造难度,而是通过质量要求和可维护性标准来提升任务难度。
六大质量维度:Frontier Code如何评估代码

Frontier Code 从六个维度全面评估提交方案的质量:
- 行为正确性:补丁是否真正解决了问题
- 回归安全性:是否破坏了原有功能
- 代码规范性:是否通过构建、格式化工具、Linter 检查
- 测试正确性:Agent 编写的测试是否真正体现了预期行为
- 影响范围:补丁是否仅触及了必要的代码部分
- 代码质量:代码是否与现有代码库契合,是否遵循合理的设计模式
其中,Linter 是一类静态代码分析工具,能够在不运行代码的情况下检测潜在的错误、风格不一致和可疑的编程模式。常见的 Linter 包括 Python 的 Pylint/Ruff、JavaScript 的 ESLint、Go 的 golangci-lint 等。在现代软件工程实践中,Linter 通常集成在 CI/CD 流水线中,代码提交后会自动运行检查。通过 Linter 检查是代码合入的基本门槛之一,但它只能捕获表层的代码质量问题,无法评估架构设计的合理性或业务逻辑的正确性——这也是为什么 Frontier Code 需要在 Linter 之上叠加更多维度的评估。
为评估这些维度,Frontier Code 采用了多种创新方法。其中最有趣的是逆向经典测试——获取智能体提交的测试并针对初始代码版本运行,如果在旧代码上通过,说明智能体的测试并未真正检测到 Bug 或代码行为的改变。此外还有自适应评分,利用名为 Mutagen 的工具动态调整参考测试,以适配智能体的不同实现方式,从而减少漏报。变异测试(Mutation Testing)是一种评估测试套件质量的高级技术,其核心思想是对源代码进行微小的、有意义的修改(称为「变异体」),例如将 > 改为 >=、删除一行代码或修改返回值,然后检查现有测试是否能检测到这些变化。如果测试套件无法发现某个变异体,说明该区域的测试覆盖存在盲区。Frontier Code 中使用的 Mutagen 工具正是基于这一原理,通过动态调整参考测试来适配智能体的不同实现方式,从而更准确地判断方案的正确性,减少因实现路径不同而导致的误判。
五阶段质控流程:每项任务超40小时打磨
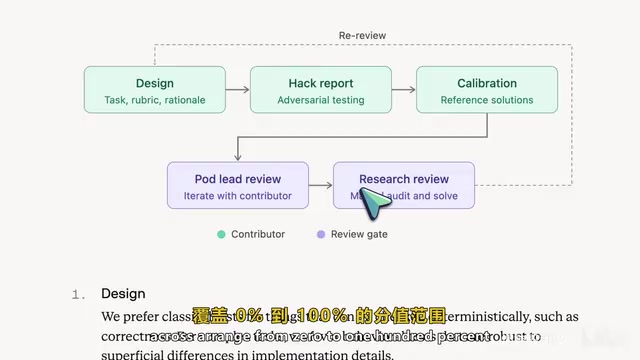
Frontier Code 的质控流程分为五个阶段,确保每项任务的评估标准经得起推敲:
- 设计任务:创建者决定哪些检查采用硬性自动化测试,哪些基于评分准则
- 破解报告:作者尝试用劣质方案攻破评分准则的漏洞,同时测试不同的有效方案以避免漏报
- 准则校准:编写覆盖 0% 到 100% 分值范围的四种不同程度方案,使评分更有区分度
- 组长审核:资深评估主管检查任务并与贡献者共同迭代优化
- 研究审核:Cognition 研究员对随机样本进行终审,亲自解题以确保指令清晰且评分公正
这些任务基于 36 个顶级开源项目的维护者合作完成,每项任务投入超过 40 小时。维护者深谙项目内部的设计模式、代码风格要求以及什么样的代码会被拒绝。这种深度参与确保了评估标准不是由外部观察者凭空制定,而是真正反映了实际开源社区的代码审查文化和质量预期。
典型案例:通过测试却不是好代码
以一个来自 JSON Schema C++ 仓库的任务为例:模型需要创建一个新的日志辅助函数,始终向标准错误输出并自动加上警告前缀,然后将所有现有的警告信息替换为新函数。
Claude Opus 在此项的得分仅为 4.8%。它将多行警告的首行改用 LogWarn 接口,但后续行仍直接使用标准错误输出。虽然目前运行效果一致,但这并不是好的抽象设计——因为调用方假设 LogWarn 会永远与标准错误指向同一个流。如果以后 LogWarn 改为将警告路由到其他位置或添加元数据,后续行的输出就会出错。这种问题在软件工程中被称为「抽象泄漏」(Leaky Abstraction)——代码表面上使用了抽象层,但实际上依赖了抽象层的内部实现细节,一旦底层实现发生变化,上层代码就会崩溃。
即使目前运行表现正常,这仍被视为质量缺陷。 这正是 Frontier Code 的核心价值所在——它评估的不仅是当下的功能正确性,更是代码的长期可维护性。
局限性与启示:代码质量成为AI编程下一个瓶颈
需要客观看待 Frontier Code 的局限性:
- 测试任务尚未公开(为避免数据污染),外部人员无法深入审查每一个评分标准。数据污染(Data Contamination)是 LLM 评测中的核心挑战之一——如果基准测试的题目和答案出现在模型的训练数据中,模型可能通过记忆而非推理来「解题」,导致评测结果虚高。这也是为什么越来越多的高质量基准测试选择不公开完整题库。
- 智能体测试环境差异意味着得分反映的是模型与工具的综合表现
- 基于提示词的评分虽能衡量单元测试无法触及的维度,但主观评分可能存在偏差
但更有价值的启示是:代码质量正成为编程智能体的下一个瓶颈。仅仅通过测试已不足以作为评测标准。模型编写的代码改动需要界限明确、易于维护、写法地道、充分测试,并能让代码库的所有者认可。这是一个更高的标准,而从目前的结果来看,还没有哪个模型能真正做到大功告成。
核心要点
相关推荐

AI工程化编程实战:Claude Code构建企业级项目的正确方法
深入解析Harness AI工程化编程方法论,探讨如何用Claude Code结合规范驱动开发(SDD)构建企业级项目,解决AI编程中死循环Bug、代码质量失控、幻觉风险等常见痛点,实现真正可维护的人机协作开发。
Claude Code实战指南:从安装配置到商业项目落地
详解Claude Code + Opus模型的完整配置流程,通过CCSwitch统一管理模型,实战演示4小时零手写代码完成支付系统二开,涵盖安装步骤、Prompt工程技巧与模型选择建议。

吴恩达联合Anthropic推出Claude Code权威教程深度解析
吴恩达与Anthropic工程师联合推出Claude Code系统课程,涵盖上下文管理、并行会话编排、MCP服务器集成等核心实践,通过RAG聊天机器人、数据分析、Figma设计转代码三大实战项目,全面提升AI辅助编程生产力。