Gemini 2.5 Pro编程实测:Rust重构吊打Claude,前端却翻车
Gemini 2.5 Pro擅长代码重构和后端逻辑,但前端开发明显拉胯
海外博主对Gemini 2.5 Pro进行多维度编程实测:Rust代码重构表现惊艳,超越Claude;终极井字棋等后端逻辑开发一次成功;但前端落地页制作效果差,Tailwind配置出错、与设计稿差距大。多项基准测试成绩领先,但训练数据时效性不如宣传。博主建议按任务类型选用不同AI工具,期待其接入IDE后成为主力。
Google最新发布的Gemini 2.5 Pro被不少开发者称为"用过最好的编程AI"。一位海外技术博主对它进行了多维度的编程实测——从像素风小游戏到终极井字棋,从落地页开发到Rust代码重构,结果既有惊喜也有翻车。
本文将逐一拆解这些测试结果,帮你判断Gemini 2.5 Pro的编程能力到底几斤几两,以及它在哪些场景下值得用、哪些场景下不如Claude。
游戏开发实测:像素风小游戏与终极井字棋
Kitten Cannon克隆:三次提示搞定
博主首先挑战了一个经典的发射类小游戏——类似Kitten Cannon的像素风游戏,要求使用P5.js实现。P5.js是基于Processing语言理念构建的JavaScript创意编程库,专为艺术家、设计师和编程初学者设计,提供了简洁的API来操作Canvas进行2D/3D图形渲染、动画和交互。它在独立游戏开发和创意编码社区中非常流行,因为开发者可以用极少的代码快速实现物理模拟、粒子效果和碰撞检测等游戏核心机制。而Kitten Cannon本身是2000年代中期的一款经典Flash网页小游戏,玩家通过发射角色并利用各种道具延长飞行距离来获取高分,其核心涉及抛物线运动模拟、碰撞检测和分数计算等编程逻辑。
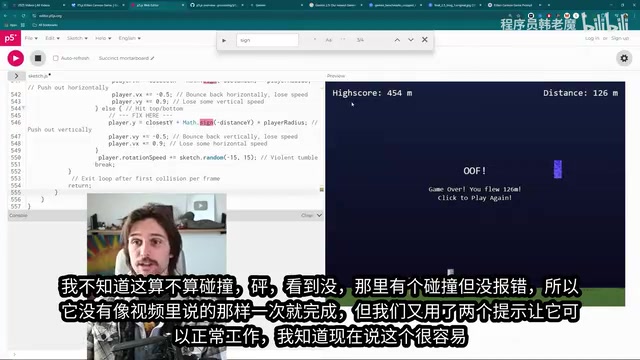
第一次生成的636行代码出现了类型错误,无法正常运行。但通过将错误信息直接反馈给模型(甚至没有提供额外上下文),Gemini 2.5 Pro成功修复了问题。总共经过三次提示,游戏就跑起来了。
虽然没有做到"一次成功",但博主提出了一个值得深思的观点:五年前我们甚至不知道AI能做什么,而现在只需要一到三个提示就能生成一个完整的像素风游戏。 我们正处在一个"享乐跑步机"上,对技术进步的感知在不断钝化,但客观来看,这种AI写代码的能力依然令人震撼。
终极井字棋:一次提示直接成功
更让人意外的是终极井字棋(Ultimate Tic-Tac-Toe)的测试。终极井字棋是普通井字棋的递归升级版,由数学家在2000年代提出。这个游戏要求在3x3的大网格中嵌套9个小井字棋棋盘,需要管理激活状态、鼠标输入、获胜条件检测等复杂逻辑。它的复杂度远超普通井字棋——普通井字棋的状态空间约为5,478个合法局面,而终极井字棋的状态空间呈指数级增长,需要同时管理81个格子的状态、9个子棋盘的胜负判定、当前激活棋盘的约束规则以及全局胜负条件。
Gemini 2.5 Pro生成了三个Java Swing代码文件:MiniBoardPanel.java、GameBoardPanel.java和UltimateTicTacToe.java。Java Swing是Java标准库中的GUI工具包,诞生于1997年,虽然在现代开发中已被JavaFX等框架逐步取代,但它在教育领域和企业遗留系统中仍有广泛使用。AI能正确生成Swing代码说明其训练数据覆盖了大量经典Java生态的知识。按照它提供的说明编译运行后,游戏一次就跑通了——所有功能正常工作,包括棋盘激活管理和胜负判定。对于Java Swing这种相对"古老"的UI框架来说,这个表现相当出色。
这两个测试说明,Gemini 2.5 Pro在游戏逻辑开发方面实力不俗,尤其是处理复杂状态管理和算法实现时表现稳定。
Gemini 2.5 Pro基准测试成绩:数据说话
在正式的基准测试中,Gemini 2.5 Pro的表现同样亮眼。这里有必要先了解各项基准测试的含义和侧重点:
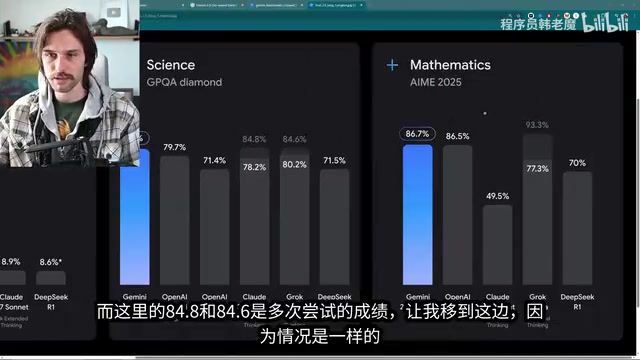
- 推理与知识(Humanities Last Exam):18.8%的得分远超O3 Mini的14%和其他模型的10%以下,增幅达34%。HLE是由数百位人文学科专家联合设计的超高难度测试集,涵盖哲学、历史、语言学等领域,旨在测试AI的深层推理和跨学科知识整合能力,大多数模型得分在10%以下,因此18.8%已经是显著突破。
- 科学领域(GPQA钻石测试):84分,超过所有其他模型的单次尝试成绩。GPQA(Graduate-Level Google-Proof Q&A)钻石测试集包含由博士级专家编写的科学问题,这些问题即使通过Google搜索也难以直接找到答案,专门用于衡量模型的深度科学推理能力。
- 数学能力:与O3 Mini持平,两者都将其他模型远远甩在身后
- 代码编辑(Aider Polyglot):优于所有竞争对手。Aider Polyglot是基于开源AI编程助手Aider的多语言代码编辑基准,测试模型在Python、JavaScript、Rust等多种语言中进行代码修改的准确性。
- 智能体编程(SWE-Bench Verified):仅次于Claude 3.7 Sonnet。SWE-Bench Verified模拟真实的软件工程任务,要求AI根据GitHub issue描述自主定位代码、编写补丁并通过测试,是目前衡量AI智能体编程能力最权威的基准之一。
说个细节,虽然Claude 3.7 Sonnet在SWE-Bench上略胜一筹,但博主指出它存在一个实际问题:3.7 Sonnet经常做很多你没有要求它做的事情,这反而导致博主退回使用3.5 Sonnet。这提醒我们,基准测试分数并不等于实际使用体验,选择AI编程工具时还需要考虑可控性和听话程度。
训练数据时效性:宣传与现实有差距
Gemini 2.5 Pro号称训练数据延伸到2025年3月,但在测试中直接询问React.js当前版本时,它回答的是18.3.1(截至2024年5月的信息)。只有在开启Google搜索接地功能后,才正确回答了React 19。
这说明训练数据的截止日期和模型实际掌握的知识之间存在差距,开发者在使用时需要对框架版本、API变更等信息多留个心眼。这种现象在大语言模型中其实很常见——训练数据的截止日期指的是语料收集的最晚时间点,但模型对不同知识领域的"记忆"深度并不均匀,高频出现在训练数据中的信息会被更牢固地编码,而低频或边缘信息则可能被模糊化甚至遗忘。
前端开发能力:落地页与UI复刻明显拉胯
落地页制作:效果令人失望
博主尝试让Gemini 2.5 Pro根据设计稿(mockup)制作一个React + Tailwind CSS的落地页。Tailwind CSS是一种实用优先(utility-first)的CSS框架,与Bootstrap等传统组件化框架不同,它提供大量原子级的CSS类名(如p-4、text-center、bg-blue-500),开发者通过组合这些类名直接在HTML中构建样式,避免了编写自定义CSS的繁琐。Tailwind在2020年后迅速成为前端开发的主流选择,尤其在React和Next.js生态中几乎成为标配。然而,Tailwind项目的初始化配置涉及PostCSS插件链、purge配置和主题定制等步骤,这对AI来说是一个不小的挑战。
虽然生成速度很快(约70秒),但最终结果相当拉胯。
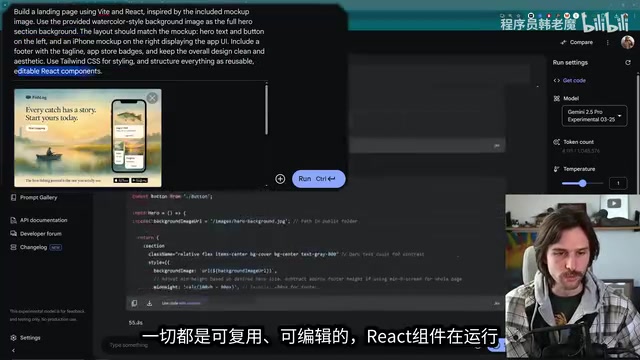
具体问题包括:
- Tailwind CSS的安装命令有拼写错误——前端工具链的碎片化和快速迭代使得AI难以始终跟踪最新的CLI命令和配置格式
- 无法直接下载代码导入项目,需要手动创建每个文件
- 只包含了背景图,没有logo和应用图标
- 最终效果与设计稿差距很大,"这真不是做落地页该有的样子"
X(Twitter)UI复刻:视觉尚可但功能缺失
复刻X网站桌面版UI的测试中,Gemini 2.5 Pro借助Google搜索功能查看了X的当前界面,生成了一个单HTML文件的静态页面。视觉效果"还不错",但当然无法实现任何实际功能。
博主的结论很直接:前端开发不是Gemini 2.5 Pro的强项。 如果你的主要工作是前端UI开发,目前可能还需要搭配其他AI工具使用。
Rust代码重构:Gemini 2.5 Pro最大的亮点
如果说前端是短板,那么Rust代码重构就是Gemini 2.5 Pro真正封神的地方。博主用同一段Rust代码在多个AI模型上测试了"将for循环重构为迭代器方法"的任务。
这里需要理解为什么这个任务如此有含金量。Rust语言的迭代器(Iterator)模式是其零成本抽象(zero-cost abstraction)哲学的核心体现。与传统的for循环相比,迭代器链式调用(如.iter().filter().map().collect())不仅代码更简洁,还能让编译器进行更激进的优化——Rust编译器会将迭代器链内联展开,生成与手写循环性能相当甚至更优的机器码。这种重构不是简单的语法替换,而是需要深入理解Rust的所有权系统、生命周期和借用规则。
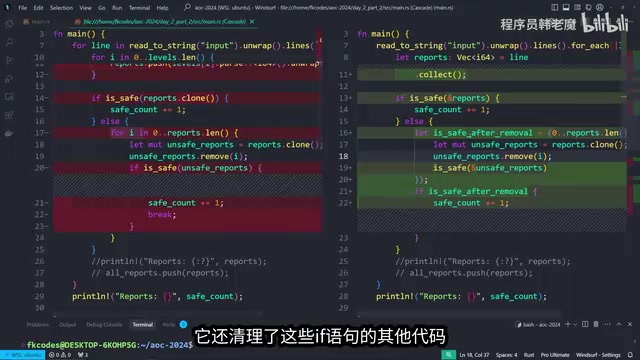
Gemini 2.5 Pro的重构结果令人惊艳:
- 彻底消除了所有for循环,全部替换为惯用的迭代器方法(
.iter()、.map()等) - 将Vec替换为slice,这是更符合Rust最佳实践的做法。slice(
&[T])是对连续内存的借用视图,避免了不必要的所有权转移,减少了内存分配开销,同时提高了函数的通用性——接受slice的函数可以同时处理Vec、数组和其他连续内存容器的数据 - 优化了逻辑结构,例如将安全检查重构为更优雅的趋势判断(递增或递减)
- 清理了周边代码,不仅仅是机械替换,而是理解了代码意图后进行整体优化
博主评价这个重构"比Claude 3.5强,比3.7也强",代码写得"真的很干净"。这种深层次的代码理解和重构能力,可能是Gemini 2.5 Pro在AI编程领域最具竞争力的特性。对于日常需要处理代码优化和重构任务的开发者来说,这个能力非常实用。
Gemini 2.5 Pro适合哪些开发场景?
通过以上多个维度的实测,我们可以清晰地看到Gemini 2.5 Pro在编程领域的优势和短板:
擅长的领域:
- 后端逻辑和算法实现(终极井字棋一次成功)
- 代码重构和优化(Rust重构表现远超Claude)
- 游戏逻辑开发(少量提示即可完成复杂游戏)
- 多语言代码编辑(Aider基准测试领先)
有待提升的方面:
- 前端UI开发和落地页制作效果不理想
- 训练数据时效性不如官方宣传
- 缺乏IDE深度集成(目前尚未接入Windsurf等工具)
关于IDE集成这一点值得展开说明。Windsurf(原Codeium团队推出)是新一代AI原生IDE,与Cursor、GitHub Copilot Workspace等工具同属AI辅助编程的前沿产品。这类工具的核心价值在于将AI模型与开发环境深度集成——不仅提供代码补全,还能感知整个项目的代码库上下文、文件结构、依赖关系和终端输出,从而实现跨文件编辑、自动调试和端到端的功能开发。模型能力与IDE集成是AI编程体验的两个独立维度:即使模型本身很强大,如果缺乏IDE层面的上下文注入和工作流编排,开发者仍然需要手动复制粘贴代码和错误信息,大幅降低效率。
博主最终表示:等Gemini 2.5 Pro接入Windsurf后,可能会将其作为主力编程工具,因为它"真的很好用,而且很便宜"。这个评价或许代表了很多开发者的心声——我们需要的不是一个在所有方面都完美的AI,而是一个在核心编程任务上足够强大、足够可靠的助手。
对于开发者来说,当前最务实的策略可能是:根据任务类型选择不同的AI编程工具。代码重构和后端逻辑用Gemini 2.5 Pro,前端开发可能还是Claude更合适。AI编程工具的"全能时代"还没有到来,但每一次迭代都在缩小差距。
核心要点
- Gemini 2.5 Pro在代码重构方面表现惊艳,Rust代码重构质量超越Claude 3.5和3.7
- 后端逻辑开发能力突出,终极井字棋Java Swing项目一次生成成功
- 前端开发是明显短板,落地页制作和UI复刻效果不理想
- 在多项基准测试中领先,但训练数据时效性不如官方宣传的2025年3月
- 性价比高,博主认为接入IDE后可能成为主力编程工具
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。