Gemini 3.5 Flash深度翻车:跑分亮眼实战拉胯,CLI工具千疮百孔
Gemini 3.5 Flash跑分亮眼但实战编码表现糟糕,价格暴涨且缺乏自我纠错能力。
Google I/O发布的Gemini 3.5 Flash虽然基准测试成绩优异,但存在严重问题:价格较前代暴涨3-20倍,token效率低下(消耗量是GPT-5.5的3.3倍),且在实际编码任务中是唯一无法完成游戏重写的模型。核心原因在于Google未攻克强化学习关键环节,模型缺乏自我检查和纠错能力,暴露了跑分与实战能力之间的巨大鸿沟。
Google I/O后的冷水:Gemini 3.5 Flash的真实表现
Google I/O 刚刚落幕,Gemini 3.5 Flash 作为重磅新品发布,跑分数据看起来光鲜亮丽。然而,知名科技博主 Theo 在拿到早期测试权限后,却给出了截然不同的评价——这个模型在实际编码任务中表现糟糕,配套的 CLI 工具千疮百孔,而 Google Cloud 同一天还搞出了封禁大客户的闹剧。更令人唏嘘的是,Google 内部优秀的开源团队被边缘化,取而代之的是一个连 demo 都藏不住抄袭痕迹的闭源产品。
Gemini 3.5 Flash跑分亮眼,但价格暴涨20倍
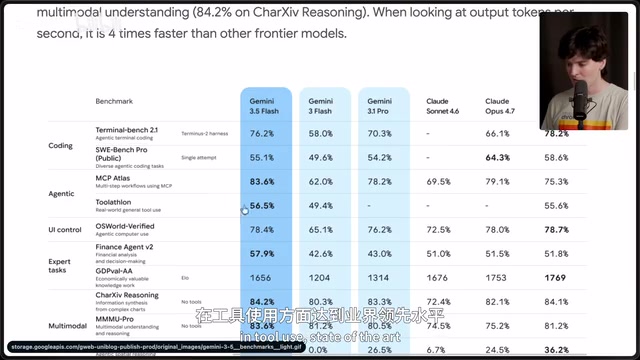
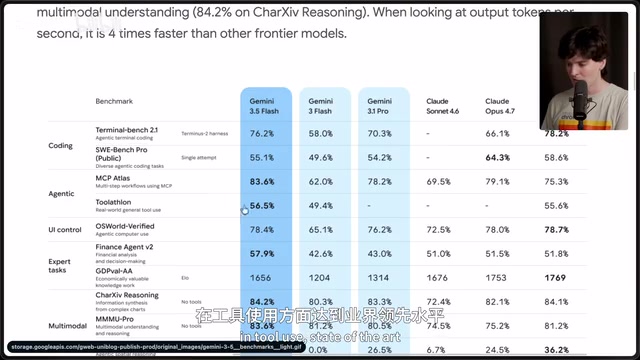
从纸面数据看,Gemini 3.5 Flash 确实亮眼。它在几乎所有基准测试中都超越了 Gemini 3.1 Pro,Terminal Bench 得分仅次于 GPT-5.5,在 Toolathon、金融代理、推理等多个维度拿到了 state-of-the-art 的成绩。Artificial Analysis 的智能指数显示,它在速度与性能的比值上遥遥领先,接近 300 token/秒的生成速度令人印象深刻。
值得注意的是,AI 模型的基准测试(Benchmark)体系本身存在系统性局限。当前主流评测如 MMLU、HumanEval、Terminal Bench 等,本质上是在特定数据集上测量模型的"考试能力",而非真实世界的工程能力。业界将这种现象称为"Benchmark Overfitting"——模型通过大量针对性训练在测试集上刷高分,但泛化能力并未同步提升。Artificial Analysis 等第三方评测机构虽然引入了速度、成本等维度,但仍难以捕捉"模型能否在复杂、多步骤的真实任务中自我纠错"这一关键能力。这也是为什么 Gemini 3.5 Flash 能在纸面上超越 Gemini 3.1 Pro,却在实战编码测试中彻底失败——后者考验的是模型的执行循环、错误感知和迭代修复能力,而这些恰恰是当前基准测试的盲区。
但 Google 在发布页面上刻意隐藏了一个关键信息:价格。整个页面没有一个美元符号。原因很简单——他们把价格翻了三倍。3.5 Flash 的定价是输入 $1.50/百万 token,输出 $9/百万 token。对比前代 3 Flash 的 $0.50 输入和 $3 输出,涨了三倍;而与 Theo 最爱的 2.0 Flash($0.10 输入、$0.40 输出)相比,涨幅超过 20 倍。
更要命的是 token 效率问题。Token 效率(Token Efficiency)是评估推理模型实际成本的关键指标,但在大多数营销材料中被刻意淡化。推理模型(Reasoning Model)与标准语言模型的核心区别在于:前者会在给出最终答案前生成大量"思维链"(Chain-of-Thought)内容,这些中间推理步骤同样计入 token 消耗。作为推理模型,3.5 Flash 在 Artificial Analysis 的基准测试中消耗了约 7200 万 token,而 OpenAI 的 GPT-5.5 Medium 仅用了 2200 万——不到前者的三分之一。这 3.3 倍的差距意味着即使单价更低,总账单可能更高。这一现象揭示了推理模型设计的核心权衡:更长的思维链通常带来更准确的答案,但也带来更高的延迟和成本。优秀的推理模型需要学会"适度思考"——在简单任务上快速收敛,在复杂任务上深度展开。3.5 Flash 已经成为这些基准测试中第四贵的模型,实际花费几乎是 3.1 Pro 的两倍。
速度快有什么用? 如果模型比别人快 2 倍,但生成的 token 量是别人的 4 倍,最终完成任务反而更慢。Token 效率低下不仅是成本问题,更是模型"不知道何时停止思考"的能力缺陷信号。
实战AI编程测试:唯一一个没跑通的模型
Theo 用自己开发中的游戏 Fish Slop 做了一个实战测试:给模型提供原始源码,让它重写成更稳定、更干净的代码库。结果令人震惊——Gemini 3.5 Flash 是他测试过的所有模型中唯一一个没能让游戏正常运行的。
它写出的代码直接就是坏的,而且不会自我检查、不会运行验证。当 Theo 要求它修复时,修复后的版本反而更差:画面出现了丑陋的光晕效果,游戏中的鱼太大无法操作,喂食机制不工作,老化机制不工作,生成的新图片质量低劣,有些甚至连透明度都没设对。
作为对比,GPT-5.5 不仅完美完成了同样的任务,Theo 甚至额外要求它把游戏改成 3D 版本,它也做到了。一个号称 state-of-the-art 的模型交出这样的答卷,Theo 直言"这是真正的耻辱"。
核心问题似乎在于:Google 仍然没有攻克 RL(强化学习)这一关,模型不知道如何检查自己的工作、不知道如何自我纠正,只是毫无目的地燃烧 token。这指向了当前 AI 编程助手的核心技术分水岭。传统的大语言模型训练依赖监督学习(SFT),模型学习"给定输入应该输出什么",但并不具备"验证自己输出是否正确"的能力。OpenAI 在 o 系列模型中大规模应用的 RLHF(基于人类反馈的强化学习)和 RLEF(基于执行反馈的强化学习)则让模型学会了一种元能力:运行代码、观察结果、根据错误信息修正策略。这种"思考-执行-验证"的循环(也称为 Agent Loop 或 ReAct 框架)是 GPT-5.5 能完成复杂游戏重写任务的关键。Gemini 3.5 Flash"只是毫无目的地燃烧 token"的描述,正是缺乏这种执行反馈训练的典型症状——模型在生成代码后没有内化"我需要验证这段代码是否能运行
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。