Gemini 3.5 Flash实测对比Qwen3.6:排行榜高分与真实体验差多远?
Gemini 3.5 Flash实测表现与排行榜分数存在明显落差
文章对谷歌Gemini 3.5 Flash进行全面实测,并与开源模型Qwen3.6-27B横向对比。结果显示,在SWE Bench Pro等核心基准上两者差距微小,而Gemini 3.5 Flash在UI生成方面虽排行榜得分最高(78.4),实际效果却与DeepSeek V3.2相当,远低于预期。文章指出排行榜分数可能因基准测试污染而虚高,不能代表模型真实能力。
引言:排行榜分数与实际体验的落差
谷歌最新发布的 Gemini 3.5 Flash 模型在各大排行榜上表现抢眼,Coding 能力号称超过 Claude Opus 4.7,UI 生成得分 78.4 与 GPT-5.5 不相上下,MCP 智能体工作流更是拿下 83% 的高分。然而,当我们真正上手体验后,却发现一个值得深思的问题:排行榜上的分数,真的能代表模型的实际能力吗?
本文将从多模态理解、Agent 能力、编程与 UI 生成等维度,对 Gemini 3.5 Flash 进行全面实测,并与 Qwen3.6-27B 进行横向对比,帮助大家建立更客观的认知。
如何免费使用 Gemini 3.5 Flash
对于国内用户来说,直接访问 Google 的服务存在一定障碍。这里介绍一个无需任何特殊网络工具即可使用的方案——通过 Chatwise 客户端接入。
具体步骤非常简单:
- 获取 Gemini API Key(需自行解决)
- 在 Chatwise 中配置 API Key
- 选择 Gemini 3.5 Flash 模型即可开始使用
配置完成后,无需任何额外的网络设置就能直接调用模型。值得一提的是,免费账户的 tokens 生成速度也相当可观,这得益于谷歌强大的 TPU 算力基础设施。
TPU 算力背景:谷歌的 TPU(Tensor Processing Unit)是专为机器学习工作负载设计的定制化 ASIC 芯片,自 2016 年起已迭代至第五代(TPU v5)。与通用 GPU 相比,TPU 在矩阵乘法运算上具有显著的吞吐量优势,单芯片峰值算力可达数百 TFLOPS。谷歌将 TPU 集群部署于自有数据中心,通过 Cloud TPU 服务对外开放,这也是 Gemini 系列模型推理速度普遍优于竞品的核心硬件原因。
相比之下,阿里的 Qwen 系列模型(包括 3.7 Max 和 Plus)在推理速度上明显偏慢。
Gemini 3.5 Flash 与 Qwen3.6-27B 硬核对比
为什么选择 27B 模型做对比?
有人可能会质疑:拿谷歌的模型跟一个 27B 参数的模型比,是不是不公平?实际上这个对比非常合理,原因有三:
- Gemini 3.5 Flash 本身就是小模型定位,并非 Pro 级别的大模型
- Qwen3.6-27B 的实际能力并不比很多蒸馏后的大模型差,性价比极高
- 两者都支持多模态,可以在同一维度上进行公平比较
Qwen 系列由阿里巴巴达摩院研发,Qwen3.6-27B 属于其第三代架构的中等规模版本。27B 参数量在当前开源生态中属于"甜点区间"——相比 7B 模型具有明显的能力优势,同时对消费级 GPU(如单张 RTX 4090 或双张 RTX 3090)保持可部署性。值得注意的是,模型蒸馏(Knowledge Distillation)技术允许将大模型的"知识"迁移至小模型,使后者在特定任务上接近甚至超越参数量更大的基础模型,这也是 27B 开源模型能够与数百亿参数闭源模型一较高下的重要原因之一。
关键基准测试指标对比
在测试中,直接将包含分数数据的图片发送给两个模型,让它们提取数据并进行对比分析——这本身就是对多模态理解能力的考验。
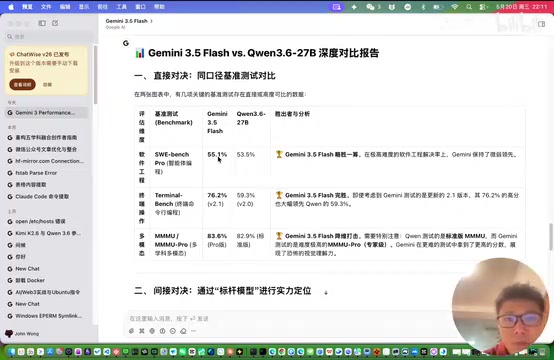
从对比结果来看:
- SWE Bench Pro(软件工程能力):Gemini 3.5 Flash 仅领先不到 2 分,差距微乎其微
- MMLU Pro(综合知识理解):Gemini 3.5 Flash 有一定优势
- 中端推理任务:Gemini 3.5 Flash 相比 27B 提升较为明显
关于这两项核心基准的背景:SWE-bench(Software Engineering Benchmark)是由普林斯顿大学研究团队提出的软件工程能力评测基准,通过从 GitHub 真实 Issue 中提取编程任务来考察模型的代码修复与工程实践能力,Pro 版本引入了更复杂的多文件修改场景,因任务来源于真实开发场景而较难通过针对性调优刷分。MMLU Pro 则在原版 57 学科四选一题目基础上扩展为十选一,并引入更多需要推理而非单纯记忆的题目,有效降低了模型通过猜测获得高分的概率。
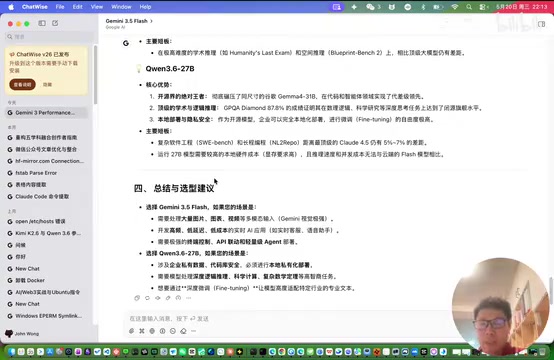
整体来看,Qwen3.6-27B 作为一个开源模型,能够与谷歌的闭源模型正面 PK,虽然以微弱劣势落后,但差距并不大。这对于开源社区来说是一个非常积极的信号。
智能体(Agent)能力评测
在 MCP 智能体工作流评测中,Gemini 3.5 Flash 取得了 83% 的分数,表现优于 Claude Opus 4.7。
MCP 协议背景:MCP(Model Context Protocol)是 Anthropic 于 2024 年底提出并开源的标准化协议,旨在解决 AI 模型与外部工具、数据源之间的集成碎片化问题。通过统一的客户端-服务器架构,MCP 允许模型以标准化方式调用文件系统、数据库、API 等外部资源,大幅降低 Agent 应用的开发复杂度。目前谷歌、OpenAI 等主流厂商已相继宣布支持 MCP,该协议正逐步成为 AI Agent 生态的事实标准,因此 MCP 工作流评测分数对于判断模型的实际 Agent 部署能力具有一定参考意义。
不过需要提醒的是,这类针对特定场景的评测分数不宜过度解读,因为部分基准测试可能是专门为某些大模型厂商设计的,不一定能全面反映真实使用场景中的表现。
UI 生成能力实测:分数与体验的矛盾
测试方案设计
既然 Gemini 3.5 Flash 在 UI 生成方面号称拿到了最高分(78.4),甚至超过了 Opus 4.7,那我们就拿它最强的领域来检验。测试方式是让模型用 HTML5 生成一个介绍页面。
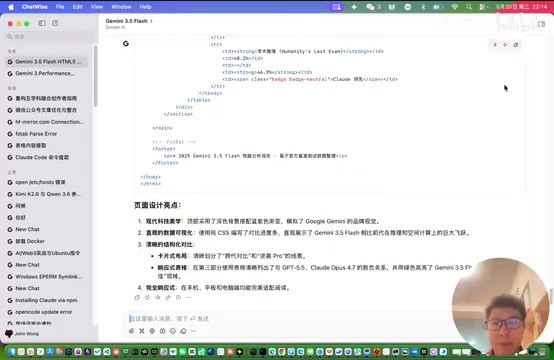
实测结果令人意外
坦率地说,生成效果与排行榜分数严重不匹配。从页面呈现来看:
- 整体效果大约与 DeepSeek V3.2 相当
- 甚至不如 V4 的表现
- 之前在网页端测试的效果更差
这并不是说 Gemini 3.5 Flash 这个模型不行,而是它在实际 UI 生成任务中展现出的能力与排行榜宣传的分数存在明显落差。这一现象背后,很可能与业界普遍存在的**基准测试污染(Benchmark Contamination)**问题有关——即模型在预训练或微调阶段接触到了评测数据集中的题目或高度相似内容,导致测试分数虚高。随着开源评测集的广泛传播,部分厂商还会针对特定排行榜进行定向优化(即"刷榜
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。