Gemini 3.5 Pro深度评测:多模态断层领先,9.2分旗舰实力全解析
Google DeepMind发布Gemini 3.5 Pro,凭借MoE架构和多模态能力刷新多项AI基准纪录。
Gemini 3.5 Pro是Google DeepMind于2026年5月发布的旗舰AI模型,采用MoE混合专家架构,支持200万token上下文窗口和五种模态输入。该模型在MMLU Pro(89.4分)、ARC-AGI-2(42分)、Video ModeM(82.1分)等基准上表现领先,核心亮点包括DeepThink深度推理模式、强大的多模态理解能力、原生代码执行(30+语言)及自定义智能体功能。
Google DeepMind 2026年旗舰:Gemini 3.5 Pro全面解读
Gemini 3.5 Pro是Google DeepMind于2026年5月正式发布的旗舰级AI模型。它搭载200万token超长上下文窗口,支持文本、图片、视频、音频、代码五种模态输入,底层采用MoE(混合专家)架构,在多项行业基准上刷新了纪录。
关于MoE架构: MoE(Mixture of Experts,混合专家)是一种将大型神经网络拆分为多个"专家子网络"的设计范式。在推理时,模型不会激活全部参数,而是由一个轻量级的"路由器"(Router)根据输入内容动态选择少数几个最相关的专家模块参与计算。这种机制使模型在保持超大参数规模的同时,大幅降低单次推理的计算量,实现"参数规模大、推理成本低"的双重优势。GPT-4、Mistral等主流前沿模型均已采用MoE架构。Gemini 3.5 Pro在此基础上进一步优化了专家路由策略,使其在多模态输入场景下能够更精准地调度视觉、语言、代码等不同领域的专家模块,这也是其多模态能力大幅跃升的底层原因之一。
这款模型的核心亮点包括:
- 原生多模态理解能力大幅跃升
- 200万上下文窗口,目前业界最长
- DeepThink深度推理模式,支持多步骤规划与自我纠错
- 原生工具调用与代码执行能力
- Gemini Gems自定义智能体功能
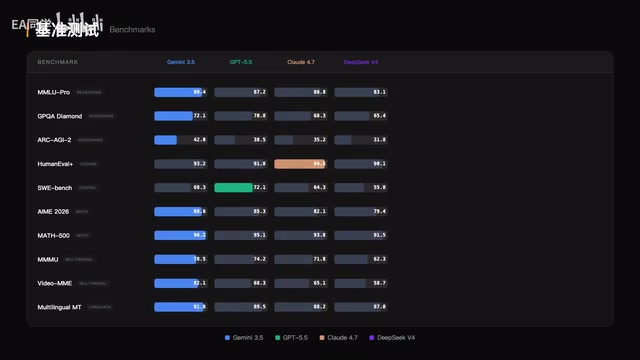
Gemini 3.5 Pro基准测试成绩汇总
在各项权威基准测试中,Gemini 3.5 Pro交出了一份相当有说服力的成绩单:
- MMLU Pro:89.4分,领先GPT 5.5和Claude
- ARC-AGI-2(通用智能评估):42分,远超同期竞品
- AIM-2026(数学推理):88.6分
- Video ModeM(多模态视频理解):82.1分,大幅领先其他模型
- SWE-bench(软件工程/编程):得分略低于GPT 5.5
理解这些基准的意义: MMLU Pro(Massive Multitask Language Understanding Pro)涵盖法律、医学、物理、历史等57个学科领域,人类专家平均得分约为78分,Gemini 3.5 Pro的89.4分意味着其专业知识广度已显著超越普通人类专家水平。ARC-AGI-2则由AI安全研究员François Chollet设计,专门测试模型的抽象推理和规律归纳能力,而非记忆已有知识——早期GPT-4在该测试上得分不足10%,人类平均得分约85%。Gemini 3.5 Pro的42分虽仍低于人类水平,但相较于前代模型已是巨大突破,标志着AI在"真正理解"而非"记忆检索"方向上的实质性进展。
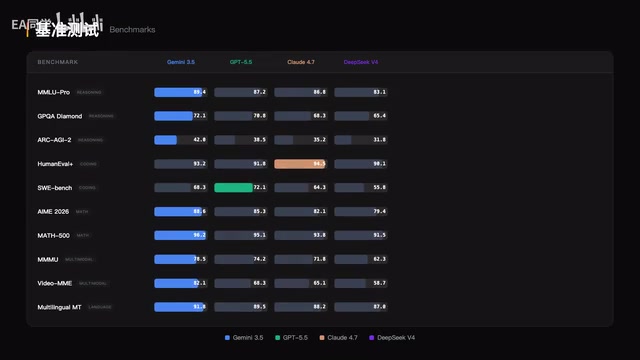
从数据来看,Gemini 3.5 Pro在推理、数学和多模态三个方向建立了明显优势。编程是它相对的短板,但差距并不算大。
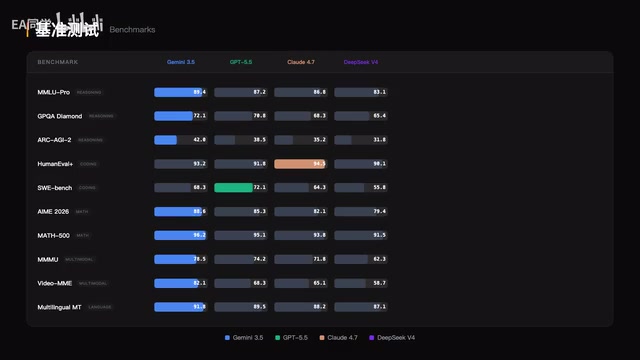
四大核心能力深度拆解
DeepThink推理模式:多步规划与自我纠错
DeepThink是Gemini 3.5 Pro引入的深度推理模式。面对复杂问题时,模型会进行分步思考,在推理链条中主动发现并修正错误。这种机制显著提升了输出结果的准确性,尤其在数学证明、逻辑分析、多条件决策等场景中效果突出。
技术背景: DeepThink模式的底层原理源于"思维链"(Chain-of-Thought,CoT)提示技术,该技术由Google Research于2022年提出。传统语言模型倾向于直接输出答案,而CoT让模型在给出最终结论前先生成一系列中间推理步骤,显著提升了复杂问题的准确率。DeepThink在此基础上引入了"自我反思"(Self-Reflection)机制:模型会在推理链中主动检测逻辑矛盾或计算错误,并回溯修正,类似人类"打草稿、检查、改正"的思维过程。这与OpenAI的o系列模型(o1、o3)以及Anthropic的扩展思考(Extended Thinking)模式属于同一技术路线,代表了大模型从"快速直觉"向"慢速深思"演进的核心趋势。在数学证明和多步骤逻辑推理任务中,这类模式通常能将准确率提升20%-40%。
多模态能力:视频、音频、图片全面碾压
多模态处理是Gemini 3.5 Pro最大的差异化卖点。它支持最长三小时的视频分析和音频理解,Video ModeM 82.1分的成绩远超所有竞品。无论是长视频内容摘要、图片细节识别还是会议录音转写与语义理解,都展现出了当前最强的综合处理水平。
代码能力:原生执行覆盖30+语言
Gemini 3.5 Pro支持原生代码执行,覆盖超过30种编程语言。虽然SWE-bench得分略逊于GPT 5.5和Claude 4.7,但原生执行的便利性和语言覆盖广度仍然是实际开发中的加分项。
关于SWE-bench: SWE-bench(Software Engineering Benchmark)由普林斯顿大学研究团队开发,其独特之处在于它不考察模型写出"正确代码片段
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。