Gemini Omni多模态理解力测试:荒诞场景提示词挑战AI极限

Google的Gemini Omni模型最近在社交媒体上引发广泛关注。一位用户通过一个极其荒诞的提示词,对该模型进行了一次别出心裁的多模态理解力压力测试,结果令人印象深刻。
Gemini Omni是Google DeepMind推出的新一代原生多模态大模型,与早期将不同模态模块拼接在一起的方案不同,Gemini从训练之初就被设计为同时理解和生成文本、图像、音频和视频。这种"原生多模态"架构意味着模型在内部表征层面就实现了跨模态的深度融合,而非在推理阶段才进行模态间的翻译转换。这一设计使其在处理复杂的跨模态任务时,能够展现出更强的语义一致性和上下文连贯性。
一个"不可能"的提示词挑战
这个测试的提示词堪称AI领域最具创意的压力测试之一:要求生成一段"一个男人在吃蒜香面包的同时,骑着独轮车平衡在一个小平台上,平台下方是翻涌的番茄酱海洋,海洋中央坐着一颗戴着礼帽、有着明亮蓝眼睛的肉丸,而这个男人正在朗诵T.S.艾略特《荒原》中《水死》篇章"的场景。
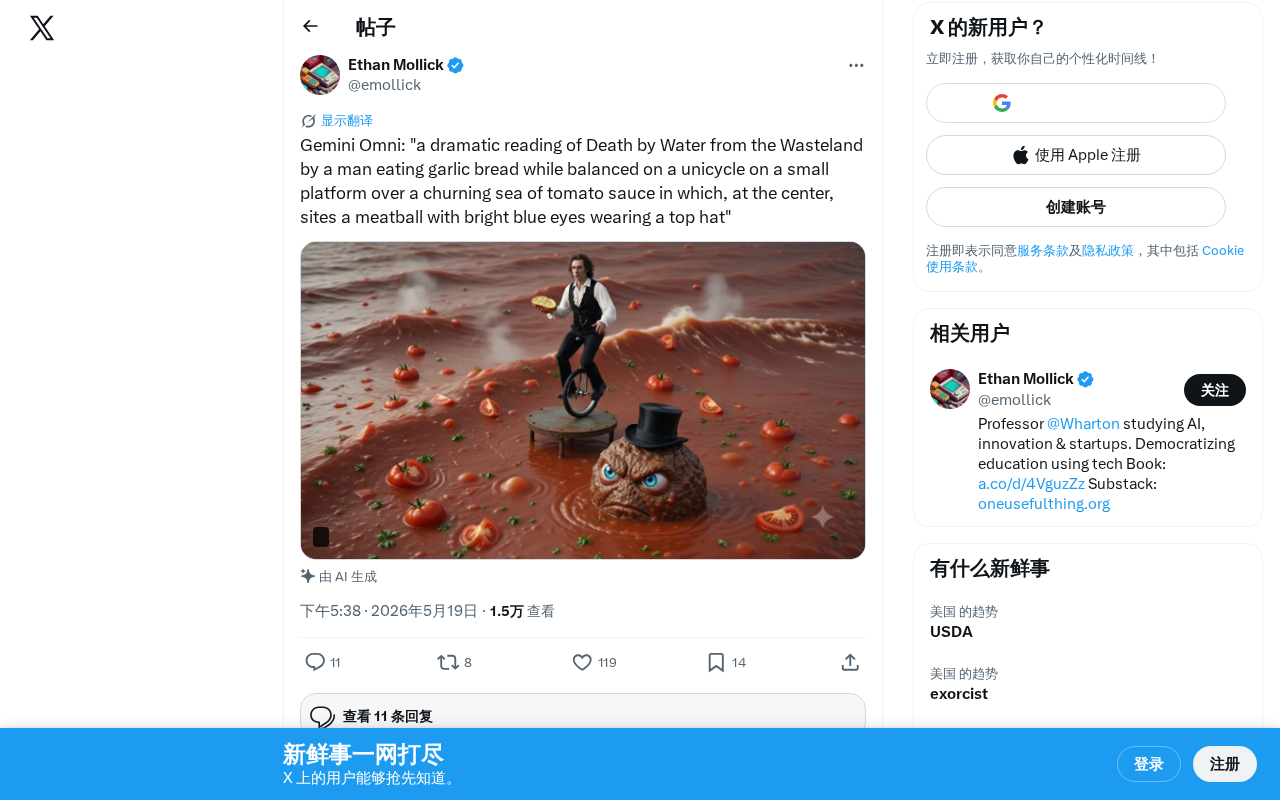
值得一提的是,T.S.艾略特的《荒原》(The Waste Land,1922年)是20世纪现代主义诗歌的里程碑之作,全诗分为五个部分,而提示词中提到的《水死》(Death by Water)是其中最短的第四部分,仅有十行,描述了腓尼基水手弗莱巴斯溺亡后在海底被洋流侵蚀的意象。选择这一篇章作为提示词的一部分,不仅要求模型具备经典文学的知识储备,还需要理解其中关于死亡、水与遗忘的深层隐喻——这与"番茄酱海洋"的荒诞设定形成了一种微妙的互文张力,进一步考验模型在严肃文学与超现实幽默之间维持语境平衡的能力。
这个提示词的复杂性体现在多个层面:
- 物理动作叠加:吃东西+骑独轮车+保持平衡
- 超现实场景构建:番茄酱海洋、拟人化肉丸
- 文化引用整合:经典文学作品的戏剧性朗诵
- 视觉元素堆叠:礼帽、蓝眼睛等细节要求
多模态AI的能力边界探索
这类测试实际上是在探索当前多模态AI模型的几个关键能力维度。要理解这些维度的技术含义,需要先了解多模态AI的基本工作原理:现代多模态模型通常基于Transformer架构,通过将不同模态的信息(如文本的token序列、图像的patch嵌入、音频的频谱特征)映射到统一的高维向量空间中进行联合表征学习。模型在海量的图文配对、视频字幕等多模态数据上进行预训练,从而学会不同模态之间的语义对应关系。当接收到一个复杂的文本提示词时,模型需要在这个共享的语义空间中构建出完整的场景表征,然后将其"解码"为目标模态的输出。
语义理解深度
Gemini Omni需要准确解析长句中的每一个元素及其相互关系,包括空间位置关系("在...上方"、"在中央")、同时进行的多个动作、以及各种修饰性细节。这对模型的自然语言理解能力提出了极高要求。
从技术角度看,这里涉及AI领域一个核心挑战——组合泛化(Compositional Generalization)。组合泛化是指模型将训练中学到的基本概念和关系,重新组合以理解和生成从未见过的新组合的能力。例如,模型可能在训练数据中分别见过"骑独轮车的人"和"番茄酱瓶子",但几乎不可能见过"在番茄酱海洋上方骑独轮车的人"。传统的深度学习模型在这种分布外(out-of-distribution)的组合场景中往往表现不佳,而大规模多模态模型通过海量数据和强大的注意力机制,正在逐步突破这一瓶颈。这个荒诞提示词之所以是一个优秀的测试案例,正是因为它将大量日常概念以极不寻常的方式组合在一起,直接考验了模型的组合泛化极限。
跨领域知识整合
这个提示词涉及文学(艾略特的《荒原》)、物理常识(独轮车平衡)、以及超现实主义艺术风格。模型需要将这些截然不同领域的知识融合到一个连贯的输出中,这正是多模态AI区别于单一模态模型的核心优势所在。
超现实主义(Surrealism)作为一种艺术流派,起源于20世纪20年代,强调通过梦境般的非理性并置来揭示潜意识的真实。萨尔瓦多·达利的融化时钟、勒内·马格利特的悬浮巨石等经典作品,都是将日常物品置于不可能的语境中。这个提示词本质上就是在要求AI进行一次超现实主义创作——将蒜香面包、独轮车、番茄酱海洋和经典诗歌这些毫不相干的元素,以内在逻辑自洽的方式融合在一起。模型能否成功完成这一任务,反映了它是否真正"理解"了这些元素的语义本质,而非仅仅进行表面的模式匹配。
创意生成能力
面对现实中不可能存在的场景,AI需要在保持内部逻辑一致性的同时,生成具有艺术表现力的内容。这种能力对于AI在创意产业中的应用至关重要。
荒诞测试对AI发展的启示
这类"荒诞测试"虽然看似娱乐性质,但实际上为AI研究和应用提供了有价值的参考。在AI安全和评估领域,类似的方法被称为"红队测试"(Red Teaming)或"对抗性评估"。传统的AI基准测试(如ImageNet、MMLU等)通常使用标准化的数据集和评分体系,但这些测试往往无法覆盖模型在真实世界中可能遇到的长尾场景。而用户自发进行的荒诞提示词测试,实际上构成了一种分布式的、创意驱动的压力测试网络——数以百万计的用户从各种意想不到的角度探测模型的能力边界,其覆盖面和创造性远超任何单一评估团队所能设计的测试方案。
- 压力测试方法论:通过极端案例发现多模态模型的能力边界和薄弱环节
- 创意应用潜力:展示AI在艺术创作、广告设计、影视概念开发等领域的巨大可能性
- 用户期望管理:帮助公众更准确地理解当前AI的真实能力水平
随着Gemini等多模态模型的持续进化,这类曾经被认为"不可能"的任务正在逐步成为可能。从行业趋势来看,多模态能力正在成为大模型竞争的核心战场——OpenAI的GPT-4o、Anthropic的Claude、Meta的Llama系列都在加速多模态能力的迭代。这场竞赛的终极目标不仅是让AI"看懂"或"听懂"单一模态的信息,而是实现真正的跨模态推理和创造,即像人类一样在视觉、听觉、语言和常识之间自由流转。这也预示着AI辅助创意工作的新阶段正在到来,创作者将获得更强大的工具来实现天马行空的想象。
核心要点
相关推荐
Claude Code 4个必改设置,开发效率直接翻倍
Claude Code 4个必改设置,开发效率直接翻倍
分享Claude Code最值得修改的4个设置:权限模式绕过、聊天记录永久保留、MCP合并规则理解、全局Skill精简到7个。改完告别确认框骚扰,节省6%上下文窗口,开发体验立刻提升。
RTK终端输出压缩工具:Claude Code省下80%Token消耗
RTK终端输出压缩工具:Claude Code省下80%Token消耗
RTK是一款用Rust编写的开源终端输出压缩工具,专为Claude Code设计。通过拦截和压缩git、npm等命令输出,将Token消耗从11.8万降至2.39万,节省约80%。免费、离线、两分钟安装即用。
笨豆:16岁独立拍纪录片,全网播放破亿的10后UP主
笨豆:16岁独立拍纪录片,全网播放破亿的10后UP主
B站UP主笨豆,16岁高一学生,从四年级开始做视频,独立完成印度、蒙古国等人文纪录片拍摄,全网粉丝超百万、播放量破亿。深入了解她的纸上剪辑法、一人纪录片工作流程及创作心路历程。