Gemini多模态Agent开发实战:理解到生成的全链路架构解析

利用Gemini API构建原生多模态Agent的技术方案与实现详解
Google DeepMind技术人员在AI Engineer大会上展示了基于Gemini API构建多模态Agent的完整方案。Gemini采用"Any2Any"架构,支持任意模态输入输出,以主模型负责理解、专用模型负责生成的分工架构为基础,通过函数调用机制让Agent自主调度图像、语音等生成模型。其100万token上下文窗口可一次处理9小时音频,并支持原生图像生成、多语言语音生成及实时交互等能力。
在AI Engineer大会上,Google DeepMind技术人员Patrick详细介绍了如何利用Gemini API构建原生多模态Agent。从多模态理解到图像、语音的原生生成,再到实时交互,他展示了一个完整的Notebook LM克隆应用的构建过程。本文将深入解析这一多模态Agent技术方案的架构设计与实现细节。
Any2Any:Gemini的多模态能力全景
Gemini的核心设计理念是"Any2Any"——任意模态输入,任意模态输出。在输入端,Gemini不仅能理解文本,还能处理代码、图像、音频、视频、URL甚至Google搜索结果。在输出端,除了传统的文本生成,现在还支持原生图像生成、语音生成、视频生成、函数调用和代码生成。
"Any2Any"架构代表了AI系统设计的一次范式转变。早期的AI系统通常只能处理单一类型的数据,例如GPT系列专注于文本,DALL-E专注于图像生成。而统一多模态架构通过**统一表示空间(Unified Representation Space)**将不同模态的信息编码为共同的向量表示,使模型能够跨模态理解和生成内容。这一理念的技术基础是Transformer架构的模态无关性:无论是文本token、图像patch还是音频帧,都可以被统一处理。Gemini更强调原生多模态训练而非后期融合,这与OpenAI的GPT-4o、Meta的ImageBind等方向既有共性又有差异。
不过Patrick坦诚指出,目前这并非由单一模型完成。当前的架构是以Gemini 3主模型为核心负责多模态理解(输出仍为文本),再配合专门的原生生成模型——如用于图像生成的Nanobanana模型和基于Gemini的语音生成模型。这种"理解+生成"的分工架构,正是构建多模态Agent的基础。

多模态理解:9小时音频一次性输入
极简的多模态输入代码
使用Gemini API进行多模态理解的代码极其简洁。通过Google GenAI SDK,开发者只需上传不同格式的文件(PDF、视频、MP3等),然后调用client.models.generate_content即可。对于较小的文件,还可以直接作为inline data传入。
# 上传文件并调用Gemini进行多模态理解
client.models.generate_content(
model="gemini-3-flash",
contents=[pdf_file, video_file, audio_file, prompt]
)
100万token上下文窗口的实际意义
一个值得关注的数据:Gemini拥有100万token的上下文窗口。对于音频来说,1分钟约等于1920个token,换算下来可以一次性输入超过9小时的音频内容;对于视频,大约可以处理1小时的素材。开发者还可以通过指定时间戳来分析特定片段,例如只分析第5分钟到第15分钟的内容。
上下文窗口(Context Window)是指语言模型在单次推理中能够处理的最大token数量。早期GPT-3的上下文窗口仅有4096个token,而Gemini的100万token窗口代表了约250倍的提升。这一突破的技术关键在于高效注意力机制的改进,包括Google提出的Multi-Query Attention和Ring Attention等技术,以及对KV Cache的优化管理。超长上下文窗口的实际意义远不止于处理长文档——它从根本上改变了RAG(检索增强生成)的必要性评估:当整本书、整部电影或整个代码库都能放入上下文时,传统的分块检索策略需要重新审视。当然,超长上下文也带来了"注意力稀释"问题,即模型对上下文中间部分的关注度下降,这是当前研究的重要课题。

此外,Patrick分享了两个实用技巧:一是可以直接传入YouTube URL进行内容分析;二是结合Context Caching功能,对于需要反复查询的长文件,可以节省高达90%的API调用成本。
多模态生成:原生图像与语音输出
Agent驱动的生成架构
与传统的硬编码工作流不同,Patrick提出的方案是构建一个真正的多模态Agent——由Gemini作为推理模型,通过函数调用(Function Calling)来驱动专门的生成模型。Agent能够自主决定哪些概念需要视觉图表、哪些章节适合音频摘要,而非由开发者预先规定流程。
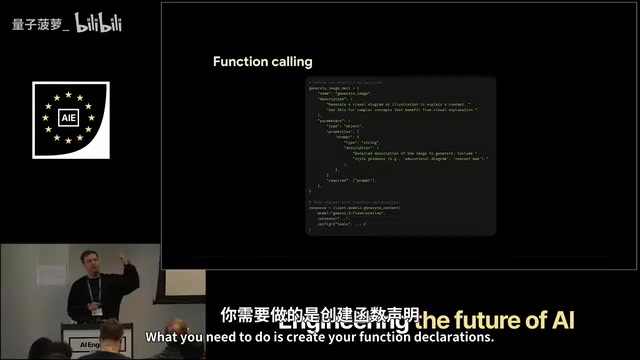
函数调用(Function Calling)是现代LLM Agent架构的核心机制,由OpenAI在2023年率先引入并迅速成为行业标准。其本质是让语言模型输出结构化的JSON格式指令,而非直接执行代码,由外部系统负责实际调用并将结果返回给模型。这种设计实现了**"推理与执行"的解耦**:模型专注于理解意图和规划步骤,工具层负责与外部世界交互。在多模态Agent场景中,Function Calling的价值尤为突出——它允许一个通用推理模型(Gemini)动态调度多个专门的生成模型,形成类似微服务架构的AI系统。与硬编码工作流相比,Agent化架构具有更强的适应性:当输入内容变化时,Agent能够自主调整调用哪些工具、调用多少次,而无需开发者预先枚举所有可能的执行路径。
具体实现上,开发者需要创建函数声明(Function Declarations),为每个函数提供名称、描述和参数定义,帮助模型理解何时调用哪个工具。
原生图像生成的独特优势
所谓"原生"图像生成,是因为这些模型基于Gemini训练,继承了Gemini对世界的深层理解能力。Patrick展示了两个令人印象深刻的案例:
- 地图理解与图像生成:在地图上画一个箭头指向某个位置,模型能识别出这是金门大桥并生成对应图片
- 数学批改:Nanobanana 2可以直接批改数学作业,生成带有修正标注的图片,因为它真正理解数学逻辑
在实际应用中,该模型特别擅长生成信息图表(Infographics),只需在prompt中指定"create an infographic"即可获得结构清晰的可视化内容。
多语言语音生成能力
语音生成模型目前基于Gemini 2.5,支持多语言和多口音输出。Patrick现场演示了英式口音和巴伐利亚德语口音的语音效果,听起来相当自然。该模型还支持双人对话模式,可以生成类似播客风格的音频内容——这正是Notebook LM最受欢迎的功能之一。

实时交互:Live API与音频到音频模型
Gemini还推出了一个全新的实时交互模型——Gemini 3.1 Flash Live。这是一个真正的"音频到音频
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。