Gemma 4全面解析:Apache 2.0开源的Agent圣体
Google开源Gemma 4模型评测与选型指南,Agent能力突出但偏科严重
Google发布Apache 2.0开源的Gemma 4系列模型,包含31B(代码强、Token效率高)、26B MOE(Agent最优、推理快)和14B/12B(端侧语音)三档。文章详细评测了各版本优缺点,提供了Windows/Linux/Mac部署方案,以及基于MS-Swift的LoRA微调实战流程,建议开发者根据场景精准选型。
Google最新发布的Gemma 4系列模型,以Apache 2.0完全开源协议震撼登场,彻底解除了所有商业使用限制。这一举措不仅是技术上的突破,更是开源生态的重大利好。实测表明,Gemma 4在Agent能力和工作流构建方面展现出统治级表现,但不同尺寸模型之间的表现差异极大,选型需要格外谨慎。本文将从模型评测、部署方案到微调实战,为你提供一份完整的Gemma 4使用攻略。
三款模型红黑榜:各有所长,偏科严重
Gemma 4此次发布了多个尺寸版本,覆盖从云端到边缘的全场景需求。但正如B站UP主在实测中所言,这是一个"极其偏科的Agent圣体"——某些维度上表现惊艳,某些维度上却存在明显短板。
31B旗舰大杯:代码大神,Token效率之王
31B版本是Gemma 4的旗舰模型,定位为"代码大神"。其编程逻辑能力极强,在LiveCodeBench跑分中达到了80%的水平,生成前端HTML的排版精美程度直逼Gemini 3。
最核心的竞争力在于Token效率——完成同样任务的Token消耗仅为竞品的65%。这一优势在需要高频调用的本地Agent工作流中尤为关键,不仅速度更快,成本也显著降低。
但短板同样明显:数学精度不足,面对信息密度极大的长文本容易产生幻觉,而且在慢思考(Thinking)模式下偶尔会陷入死循环。

26B MOE性价比中杯:真正的Agent圣体
26B MOE版本堪称本次发布的最大惊喜,被评价为"真正的Agent圣体"。对于本地开发者而言,它是24G显存显卡的福音——虽然总参数量达到25.2B,但得益于MOE(混合专家)架构,推理时仅激活约3.8B参数,实测推理速度高达每秒60个Token。
配合256K的超长上下文窗口,它非常适合塞入复杂的系统提示词来构建本地自主智能体。对于需要在有限硬件资源上运行复杂Agent工作流的开发者来说,这个版本几乎是目前的最优选择。
不过,它的文本生成质量是短板所在:中文写作表现平庸,部分开发者反馈其生成内容存在"灌水"现象,信息密度不高。
14B和12B端侧小杯:边缘设备的语音王牌
14B和12B两款小尺寸模型瞄准的是边缘设备场景。最惊艳的特性是原生支持端侧语音输入,最高支持30秒音频,这意味着无需外挂ASR(语音转文字)模型,离线英文语音转写几乎完美,极其适合构建IoT语音交互设备。

但需要注意的是,这两款模型的视觉和OCR能力是"重灾区"——面对发票或手机截图时,文字提取错漏百出,完全无法胜任需要视觉操作的网页自动化任务。选型时务必根据实际需求权衡。
部署方案:三大平台各有最优解
不同操作系统和使用场景下,Gemma 4的部署策略有所不同,以下是经过验证的推荐方案。
Windows用户:Ollama一键启动
Windows用户建议直接使用Ollama,安装完成后在终端执行一条命令即可启动Gemma 4的31B版本,上手门槛极低。
Linux / WSL2用户:vLLM高并发部署
如果你在Linux或Windows的WSL2环境下需要部署高并发服务,强烈建议使用vLLM框架。推荐采用4Bit量化版本,可以显著降低显存压力并提升响应速度。部署时需要注意两个关键参数:
- 端口:确认8000端口未被占用
- 最大模型长度:设置为6000,确保服务稳定运行
Mac用户:暂时选择Ollama
目前MLX框架对Gemma 4的适配还不完美,Mac用户现阶段最稳妥的方案依然是使用Ollama来运行。
微调实战:从环境搭建到模型上传
对于希望将Gemma 4适配到特定业务场景的开发者,微调是必经之路。以下是基于MS-Swift框架的完整微调流程。
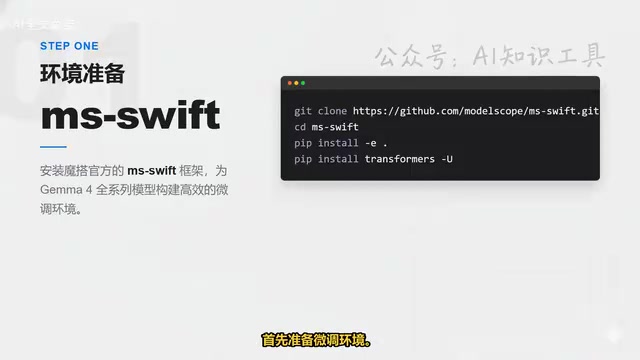
环境准备:MS-Swift框架安装
首先需要安装魔搭(ModelScope)官方的MS-Swift框架,它已经第一时间支持了Gemma 4全系列模型。操作步骤很简单:克隆仓库、进入目录、执行安装命令,并同步更新Transformers库到最新版本。
核心训练:LoRA量化微调方案
以12B视觉微调为例,推荐采用LoRA量化微调方案。通过设置LoRA Rank为8,仅更新极少量参数,在保证效果的同时大幅降低算力需求。
有两个关键的Freeze参数需要特别注意:
- VIT冻结:保护模型原有的视觉编码能力
- Aligner冻结:保护多模态对齐层不被破坏
为了在多卡环境下高效运行,建议开启DeepSpeed Zero 2优化显存。执行训练命令后,框架会自动加载LaTeX OCR数据集进行训练。
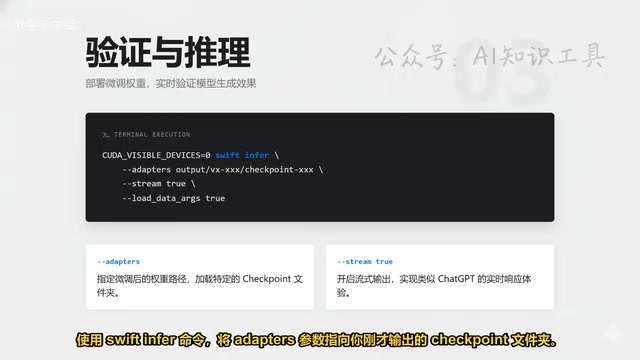
效果验证与自定义数据集准备
训练完成后,使用swift infer命令进行效果验证,将Adapter参数指向输出的Checkpoint文件夹,即可实时查看模型的生成结果。
如果你想用自己的数据进行微调,需要准备JSONL格式的文件:
- 纯文本模式:标准的对话消息列表(messages格式)
- 图像多模态:在messages之外增加
images字段,指向图片路径 - 语音多模态:增加
audio字段,指向音频文件路径
这样模型才能将多模态输入与文本回复正确关联。
模型上传:一键推送到ModelScope云端
最后一步是将微调好的适配器推送至ModelScope。执行swift export命令,填入模型ID和SDK Token,即可将本地权重上传到云端Hub,方便在不同设备上快速调用。
选型建议与总结
Gemma 4的发布标志着Google在开源大模型领域的重大战略转向。Apache 2.0协议的采用,让它在商业友好度上直接拉满。从实际表现来看:
- 构建本地Agent工作流:首选26B MOE版本,性价比无敌
- 代码生成和开发辅助:选择31B旗舰版,编程能力顶级
- 边缘设备语音交互:14B/12B端侧版本是最佳选择
- 中文写作和视觉OCR:Gemma 4目前并非最优选,建议观望后续更新
总体而言,Gemma 4是一个"偏科生"——在Agent、代码、Token效率等维度上表现卓越,但在数学精度、中文质量、视觉OCR等方面仍有提升空间。开发者应根据具体场景精准选型,而非盲目追求最大参数量。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。