GitNexus:用知识图谱让AI编程告别盲改代码
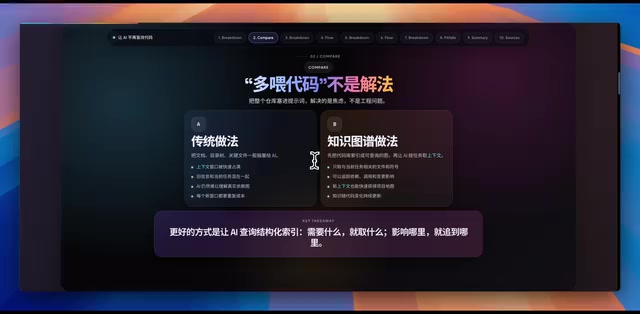
GitNexus通过知识图谱让AI编程工具按需精准获取代码信息,降低Token消耗并避免盲目修改。
文章介绍了开源工具GitNexus如何解决AI编程中的痛点。它将代码库构建为知识图谱,记录函数、类、模块间的依赖和调用关系,使AI能按需精准获取相关代码片段,而非全量加载。这不仅大幅降低Token消耗,还能在修改代码前通过反向查询分析影响范围,避免连锁反应破坏已有功能。
为什么AI编程需要知识图谱?
使用AI编程工具进行项目开发时,随着项目规模增长,我们会频繁遇到几个痛点:
- 每次新开对话窗口,都需要重复向AI解释项目架构、规范和注意事项
- 担心AI不了解项目全貌,修改代码时产生连锁反应,破坏已有功能
- 把文档、目录、关键文件全塞给AI,上下文窗口很快被挤满,Token成本飙升
传统做法是将所有相关文件一股脑塞给AI,这不仅浪费Token,还会导致AI在长对话中逐渐遗忘前面的规范和约定。
这里有必要理解大语言模型「上下文窗口」的深层矛盾。上下文窗口是指模型在单次推理中能处理的最大文本长度,以Token为单位计量(1个Token约等于0.75个英文单词或0.5个中文字符)。主流模型的上下文窗口从早期的4K Token发展到如今的128K甚至200K Token,但这并不意味着问题消失——更长的上下文带来两个新问题:一是成本线性增长,输入Token通常按量计费;二是「迷失在中间」(Lost in the Middle)现象,研究表明模型对上下文首尾信息的注意力显著高于中间部分,当代码文件被大量塞入时,关键规范信息可能被模型「忽视」。
我们需要的是一种更智能的方式——让AI按需获取信息,而不是全量加载。
GitNexus 是什么?
GitNexus 是一个开源工具(目前已获得36K Star),它的核心能力是将代码库从简单的文件列表转化为一个结构化的关系网络——即知识图谱。
知识图谱(Knowledge Graph)最初由Google于2012年提出,用于组织互联网上的实体关系。在代码库场景中,知识图谱将代码中的函数、类、模块、变量等抽象为「节点」,将调用关系、继承关系、依赖关系抽象为「边」,形成一张可查询的有向图结构。这与传统的文件树索引有本质区别:文件树只记录「文件在哪里」,而知识图谱还记录「文件之间如何关联」。这种图结构天然支持图遍历算法,使得「找到所有调用了函数A的地方」这类查询可以在毫秒级完成,而无需扫描整个代码库。
具体来说,GitNexus 做了这几件事:
- 扫描代码库,构建知识图谱:分析代码间的依赖关系、调用链、模块边界
- 本地运行,安装MCP和Skills:通过标准化接口让各种AI编程工具都能查询索引
- 按需索引,精准取用:AI根据当前任务,只读取与之相关的文件和符号
- 追踪变更影响:修改代码前,先分析会影响哪些模块和流程
简单理解:GitNexus就像给AI配了一张「项目地图」,AI不再需要阅读整个代码库,而是根据任务沿着关系链精准定位需要的信息。
实际使用效果如何?
AI自己怎么看这个工具
在实际使用中,AI对GitNexus的评价是:"它就像一个代码地图+影响分析器,可以在改代码之前知道哪里被引用、会影响哪些流程,避免盲目修改。"

Token消耗极低
GitNexus一个非常突出的优势是上下文Token消耗很低。它的工作流程是:
- AI触发GitNexus工具时,先检查是否有新修改未更新索引
- 自动刷新索引(只读索引更新,不涉及源码修改)
- 根据任务进行边界查询和依赖分析
- 只返回与当前任务相关的代码片段和关系信息
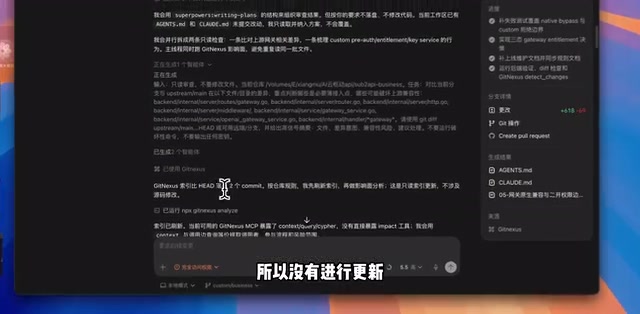
整个流程就像沿着一条线索追查——需要什么取什么,影响什么就追查到哪里,而不是把整个代码库都读一遍。GitNexus的按需索引策略本质上是将「大海捞针」问题转化为「精准导航」问题,从根本上规避了Token浪费和注意力分散两个缺陷。
解决代码修改的连锁反应问题
以前让AI修改某个功能时,它可能不知道这段代码被其他10个地方引用。这一问题的根源在于代码依赖分析的复杂性。GitNexus在构建知识图谱时,会对代码执行多层次的静态分析(Static Program Analysis):语法层面通过AST(抽象语法树)解析函数定义与调用;语义层面通过符号解析(Symbol Resolution)追踪跨文件的引用关系;模块层面分析import/require/include等依赖声明。这些信息被持久化为图数据库结构,支持关键的「反向查询」——不仅能查「A依赖了谁」,还能查「谁依赖了A」。
有了GitNexus后,AI在动手之前会:
- 先读取知识图谱索引
- 分析代码的顶层架构和依赖关系
- 通过反向图遍历枚举所有潜在影响范围(在大型项目中可能涉及数十个文件和数百个调用点)
- 识别潜在风险点
- 制定合理的优化或开发方案
对于编程经验不足的AI开发爱好者来说,这意味着大幅降低了因AI"盲改
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。