GLM-4.6深度实测:性能、价格与编程能力全面评估
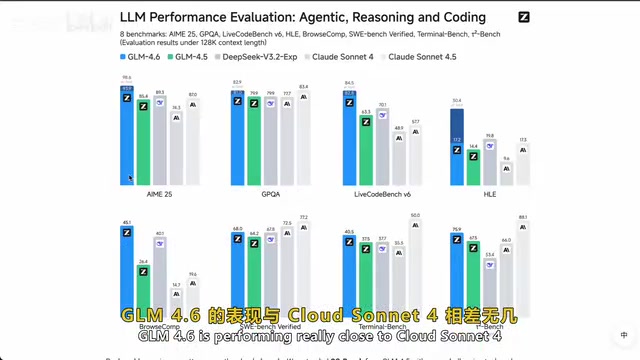
智谱AI发布开源模型GLM-4.6,以极低价格提供接近顶尖的AI性能
智谱AI发布GLM-4.6开源大模型,采用MoE架构(3550亿参数仅激活320亿),上下文窗口扩展至200K Token。实测中编程能力出色,可一次性生成完整可运行代码。价格仅为Claude Sonnet 4.5的1/7到1/20,极具性价比。不足之处在于纯编码基准测试仍落后于Claude,Token效率偏低。开源可本地部署,适合高频API调用、注重数据隐私和预算有限的团队。
AI开源领域迎来重磅选手:GLM-4.6正式发布
在AI领域消息密集轰炸的当下——Claude 4.5 Sonnet刚刚发布、OpenAI上线Sora 2、Gemini 3.0也蓄势待发——智谱AI悄然推出了GLM-4.6模型。这款定位为行业巨头有力竞争者的开源大模型,凭借极具竞争力的价格和接近顶尖的性能,迅速引发了开发者社区的广泛关注。
本文将从架构设计、编程实战、价格对比和适用场景四个维度,对GLM-4.6进行全面评测,帮助你判断它是否值得纳入你的技术栈。
GLM-4.6架构升级:MoE设计带来效率飞跃
参数规模与激活策略
GLM-4.6采用了**专家混合架构(Mixture of Experts, MoE)**设计,总参数量达到3550亿。但关键在于,它在推理时只激活约320亿个参数。这意味着你获得了一个拥有大模型知识容量、却以小模型效率运行的系统。
MoE是近年来大模型架构设计中最重要的范式转变之一。传统的密集型(Dense)模型在推理时会激活所有参数,导致计算成本与参数规模线性增长。而MoE架构将模型的前馈网络层拆分为多个独立的"专家"子网络,每次推理时通过一个门控网络(Gating Network)动态选择少量专家参与计算。Google的Switch Transformer(2021年)是这一架构的早期里程碑,而Mistral的Mixtral 8x7B则让MoE在开源社区中大规模普及。GLM-4.6的3550亿总参数仅激活320亿,意味着其激活比例约为9%,这一比例在当前MoE模型中属于较为激进的稀疏设计,能在保持大模型知识容量的同时大幅降低推理所需的算力和显存。
这种设计哲学体现了智谱AI团队的务实取向——不追求参数规模的军备竞赛,而是让模型更实用、更适合实际部署。
上下文窗口大幅扩展
相比4.5版本的128K Token上下文窗口,GLM-4.6将其扩展至200K Token,最大输出长度也达到了128K Token。这一提升意义重大:你可以处理更大规模的代码库、更长的文档,执行更复杂的多步骤任务,而不会因上下文限制而受阻。
上下文窗口指模型单次推理时能处理的最大Token数量,它直接决定了模型能"看到"多少信息。早期GPT-3的上下文窗口仅为2048 Token(约1500个英文单词),而200K Token大约相当于一本500页的书籍或一个中型软件项目的完整代码库。扩展上下文窗口面临的核心技术挑战是Transformer架构中自注意力机制的计算复杂度随序列长度呈二次方增长。业界通常采用稀疏注意力、滑动窗口注意力、RoPE位置编码外推等技术来突破这一瓶颈。GLM-4.6将上下文窗口从128K扩展到200K,同时最大输出长度达到128K,这对于需要生成长篇代码、完整报告或进行大规模文档分析的场景尤为关键。
GLM-4.6编程实战:一次生成,无需调试
测试一:矩阵风格动画网页
在第一个测试中,要求GLM-4.6生成一个矩阵风格的数字雨动画网页。模型快速生成了包含HTML、CSS和JavaScript的完整代码。实际运行效果令人满意:绿色字符流畅滑落,逐渐消失的动画效果没有任何卡顿。
**关键点:一次性完成,无需调试。**这在实际开发中意味着显著的效率提升。
测试二:任务管理应用
第二个测试更具实用性——构建一个完整的任务管理App,要求包含添加任务、标记完成、删除和筛选功能,任务状态分为"进行中"和"已完成"。
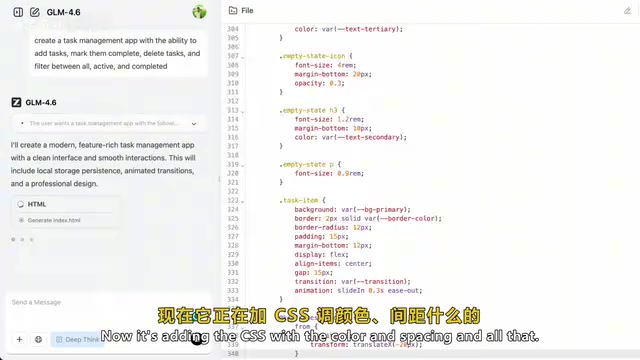
模型在大约30-40秒内完成了全部代码生成,包括HTML结构搭建、CSS样式设计和JavaScript功能实现。最终成品界面简洁、交互流畅,复选框、删除按钮、状态切换等功能全部正常运行。
同样是一次输入完成,不需要反复调整提示词。这种"一次成型"的AI编程能力,对于日常开发工作流来说价值巨大。
GLM-4.6 vs Claude价格对比:7到20倍的成本差距
价格是GLM-4.6最大的卖点之一,我们直接看数据:
| 模型 | 输入价格(每百万Token) | 输出价格(每百万Token) |
|---|---|---|
| GLM-4.6 | $0.06 | $2.2 |
| Claude Sonnet 4.5 | $3.0 | $15.0 |
价格差距达到7到20倍,取决于你的使用模式。对于高流量应用或开发工作量较大的场景,这种成本优势会被急剧放大。
要真正理解这一价格差距的影响,需要了解Token经济学。Token是大语言模型处理文本的基本单位,一个英文单词通常被拆分为1-3个Token,而一个中文汉字通常对应1-2个Token。以一个日均处理100万次API请求、每次请求平均消耗1000个输入Token和500个输出Token的中型应用为例:使用Claude Sonnet 4.5的月度成本约为31.5万美元,而使用GLM-4.6则仅需约3.48万美元,成本降低近90%。这种数量级的差距足以改变一个AI产品的商业可行性,尤其对于利润率敏感的B2C应用和资源有限的初创团队。
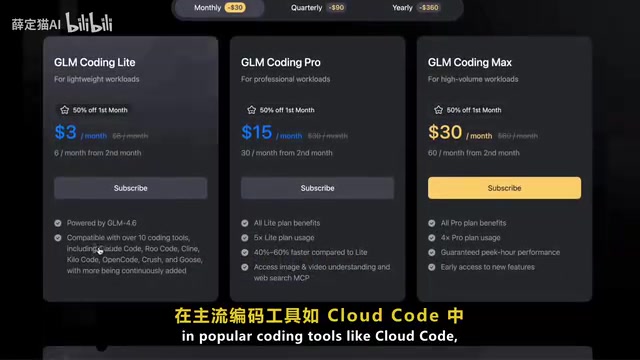
此外,智谱还推出了GLM编码订阅计划,起价仅每月3美元,支持在Claude Code、Open Code、RU Code等主流编码工具中使用GLM-4.6。换算下来,你可以用七分之一的价格享受接近云端级的性能,且使用量是同等预算下云端服务的三倍。
GLM-4.6优缺点分析:优势与不足并存
明显优势
- 性价比极高:近乎顶尖的性能,成本却只有竞品的几分之一
- 开源可控:提供模型权重,支持本地部署,数据安全有保障
- 代理流程表现优异:工具使用灵活,API集成、网页爬取、多文件代码生成等场景表现出色
- 推理能力强:能稳妥完成复杂的多步骤任务
关于代理流程(Agent Workflow),这是2024-2025年AI应用层最热门的方向之一。与传统的单轮问答不同,AI Agent能够自主规划任务步骤、调用外部工具(如API、数据库、浏览器)、根据中间结果动态调整策略,并最终完成复杂的多步骤目标。典型的Agent框架包括LangChain、AutoGPT、CrewAI等。一个Agent的核心能力取决于底层大模型的工具调用(Function Calling)准确率、指令遵循能力和长上下文推理能力。GLM-4.6在代理流程中表现优异,意味着它能准确理解工具调用的格式要求、合理编排多步骤执行计划,并在长链条任务中保持逻辑一致性——这对于构建自动化工作流和企业级AI应用至关重要。
需要注意的不足
第一,纯编码能力仍有差距。 在软件工程师基准测试(SWE-bench)和终端基准测试等严格的编码评测中,Claude Sonnet 4.5依然明显领先。如果你需要处理极其复杂的编码任务,且对性能有最高要求、成本不是首要考量,Claude仍是更好的选择。
SWE-bench(Software Engineering Benchmark)是由普林斯顿大学研究团队于2023年推出的编码能力评测基准,被广泛认为是衡量AI模型实际软件工程能力的黄金标准。它从GitHub上真实的开源项目中提取了数千个Issue和对应的Pull Request,要求模型在理解问题描述后,自主定位代码库中的相关文件并生成正确的修复补丁。与简单的代码生成题目不同,SWE-bench考察的是模型在真实工程环境中的综合能力——包括代码理解、跨文件导航、Bug定位和修复方案设计。目前Claude Sonnet系列在SWE-bench上持续保持领先,这也解释了为何在纯编码任务中GLM-4.6仍存在差距。
第二,Token使用效率偏低。 GLM-4.6在某些任务中存在用词量偏多的问题,Token使用效率不如部分竞品。不过考虑到其Token成本极低,这一问题在实际使用中的影响有限。
智谱AI团队正在根据用户反馈积极改进这些问题,后续版本值得期待。
谁适合使用GLM-4.6?五类最佳用户画像
基于实测结果,以下几类用户最能从GLM-4.6中获益:
- 高频API调用的开发者:大量API调用场景下,成本节约效果最为显著
- AI编程工具的重度用户:配合GLM编码订阅计划,性价比远超同类方案
- 注重数据隐私的企业:开源模型支持本地部署,数据不出内网
- 构建AI Agent的团队:在代理流程和工具调用方面表现优异
- 预算有限但需要强大AI能力的中小团队:用极低成本获得接近顶尖的性能
关于第三类用户需要特别说明的是,开源模型的本地部署能力在当前AI产业格局中具有深远的战略意义。对于企业用户而言,将敏感数据发送至第三方API存在合规风险——尤其在金融、医疗、政务等受严格监管的行业,数据主权和隐私保护是不可妥协的底线。欧盟《AI法案》和中国《生成式人工智能服务管理暂行办法》等法规进一步强化了这一需求。本地部署还意味着推理成本可预测(仅为硬件折旧和电力成本)、无网络延迟、不受API服务商的速率限制和定价策略变动影响。GLM-4.6提供完整的模型权重下载,配合vLLM、TGI等高效推理框架,企业可以在自有GPU集群上实现完全自主可控的AI能力,这在地缘政治不确定性加剧的背景下尤为重要。
总结:GLM-4.6是开源AI生态的健康信号
GLM-4.6的发布,不仅仅是又一个模型的问世,更是开源AI生态健康发展的重要信号。它证明了开源模型完全有能力在性能上逼近甚至部分超越闭源商业模型,同时以数量级的价格优势降低AI应用的门槛。
对于大部分应用场景而言,GLM-4.6已经完全能够胜任,而其带来的成本节约是实实在在的。随着社区的壮大和模型的持续迭代,GLM-4.6的竞争力只会越来越强。
它完美吗?不是。但它足够好,而且足够便宜——在工程实践中,这往往比"最好"更重要。
核心要点
- GLM-4.6采用MoE架构,3550亿总参数仅激活320亿,上下文窗口扩展至200K Token
- 实测中一次性生成完整可运行的动画网页和任务管理应用,无需调试
- 价格仅为Claude Sonnet 4.5的1/7到1/20,输入每百万Token仅$0.06
- 在纯编码基准测试中仍落后于Claude Sonnet 4.5,Token使用效率也有待优化
- 开源可本地部署,配合每月$3起的编码订阅计划,对开发者极具吸引力
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。