GLM-4.7深度实测:编程能力全面对标Claude Sonnet 4.5
智谱AI发布开源大模型GLM-4.7,编程能力实测接近顶级闭源模型水平。
智谱AI发布了358B参数的MOE架构开源大模型GLM-4.7,采用MIT协议支持自由商用。官方基准测试显示其在数学、代码、推理等多项指标上超越DeepSeek V3.2和Claude Sonnet 4.5。实测中,GLM-4.7在前端开发(SVG动画、3D游戏)、浏览器自动化、iOS原生APP端到端开发等任务中表现出色,代码一次生成可运行性强,综合编程能力已接近顶级闭源模型。
智谱AI近日正式发布了最新开源大模型GLM-4.7。这款专为编程和智能体任务打造的大型MOE模型,参数量达358B,采用MIT开源协议,支持自由商用。官方基准测试显示,GLM-4.7在多项核心指标上超越了DeepSeek V3.2甚至Claude Sonnet 4.5,一时间引发开发者圈层的广泛讨论。
MOE(Mixture of Experts,混合专家)是一种稀疏激活的模型架构,其核心思想是将模型拆分为多个"专家"子网络,每次推理时只激活其中一部分专家来处理输入。这意味着虽然GLM-4.7总参数量高达358B(3580亿),但实际推理时激活的参数量远小于此,从而在保持大模型能力的同时显著降低计算成本。DeepSeek V3同样采用了MOE架构,这已成为当前大模型扩展的主流技术路线。相比传统的Dense(稠密)模型——如早期的GPT系列每次推理都激活全部参数——MOE架构在同等算力预算下能训练出更大规模的模型,实现更好的性能表现。
而MIT协议作为目前最宽松的开源许可证之一,允许任何人自由使用、复制、修改、合并、发布、分发、再授权和销售软件副本,唯一的要求是在软件的所有副本中包含版权声明和许可声明。相比之下,Meta的Llama系列虽然也开源,但附带了用户规模限制(月活超过7亿需要额外授权);而一些采用Apache 2.0协议的模型虽然也很宽松,但在专利授权条款上更为复杂。GLM-4.7选择MIT协议,意味着企业可以直接将其集成到商业产品中,无需支付授权费用,也无需公开自己的修改代码,这对于中小企业和创业团队来说极具吸引力。
那么,GLM-4.7的编程能力到底有多强?本文通过前端开发、3D游戏、浏览器自动化、iOS原生APP开发等多个维度进行实测,带你看看这款开源模型的真实水平。
官方基准测试:多项指标领先闭源模型
先来看官方公布的基准测试数据,GLM-4.7的成绩相当亮眼:
- 数学竞赛:95.7分,明显领先,甚至超过GPT-5.1
- 代码能力:超过DeepSeek V3.2及Claude Sonnet 4.5
- 科学推理:超过DeepSeek V3.2及Claude Sonnet 4.5
- 复杂推理:领先于DeepSeek V3.2、Claude Sonnet 4.5和GPT-5.1
- 软件工程:超过DeepSeek V3.2,仅次于GPT-5.1和Claude Sonnet 4.5
- 浏览器能力:超过DeepSeek V3.2和GPT-5.1,明显领先Claude Sonnet 4.5
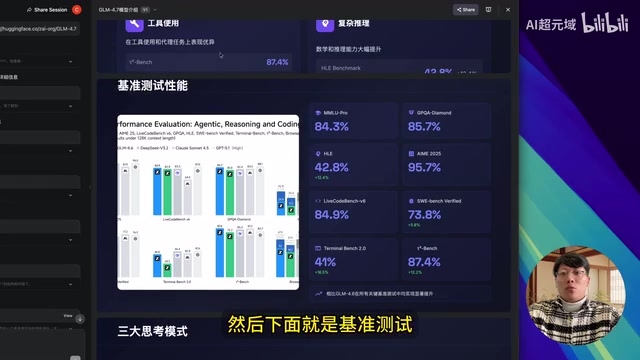
这些基准测试涵盖了当前AI模型评估的几大核心维度。数学竞赛通常采用AIME(美国数学邀请赛)等标准化竞赛题目来评估模型的数学推理能力;代码能力常用HumanEval、LiveCodeBench等基准,要求模型根据自然语言描述生成可执行代码;软件工程能力则通过SWE-bench等基准测试,评估模型修复真实GitHub仓库中bug的能力;浏览器能力测试(如WebArena、WebVoyager)则考察模型在真实网页环境中执行复杂操作的能力。值得注意的是,基准测试存在"过拟合"风险——模型可能在训练过程中接触过类似题目,因此实际应用中的表现才是更可靠的评估标准。
从综合数据来看,GLM-4.7已经达到了与顶级闭源模型正面竞争的水平,尤其在数学推理和复杂逻辑方面表现突出。不过,基准测试终究只是参考,实际编程能力还得靠真实任务来检验。
前端编程能力实测:从SVG到3D游戏
SVG动画生成:一句话搞定太阳系
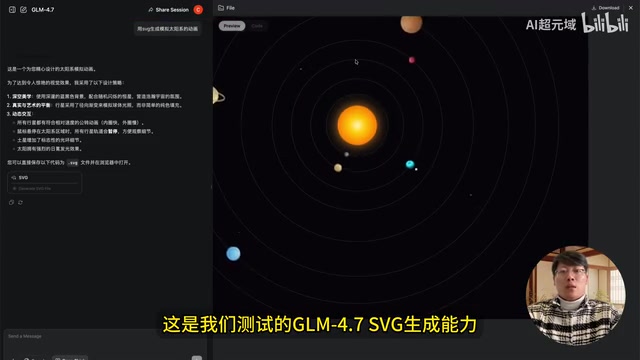
第一个测试从简单任务开始。仅用一句提示词"用SVG生成模拟太阳系的动画",GLM-4.7就输出了一个相当精美的太阳系动画——八大行星围绕太阳公转,轨迹清晰流畅,甚至还包含了月球围绕地球运转、土星光环等细节,完成度远超预期。
冒泡排序可视化:算法与美学的结合
接下来加大难度。要求GLM-4.7创建一个太空主题的冒泡排序可视化动画:12颗大小不同的小行星随机排列,一艘指挥舰使用冒泡算法逐一比较并排序,整个过程需要可视化展示。
测试结果令人满意。指挥舰会逐一比较相邻小行星,发现左侧更大时进行交换,移动动画流畅自然,界面还实时显示"正在比较"和"正在交换"的状态信息,全程运行零报错。
这道题看似简单,实则考察了算法理解、前端技术选型、动画交互设计以及视觉美学表达的跨领域整合能力,GLM-4.7交出了一份不错的答卷。
3D恐龙狩猎游戏:终极前端压力测试
前端测试的最后一关:使用HTML5 Canvas和JavaScript创建一个3D风格的恐龙狩猎游戏。具体要求包括可操控的皮卡车、机枪射击、鼠标瞄准、键盘控制移动,以及原始森林、火山等侏罗纪环境。
HTML5 Canvas是浏览器原生提供的2D绘图API,通过JavaScript可以在网页上实时绘制图形、动画和游戏画面。虽然Canvas本身是2D的,但开发者可以通过数学投影变换(如透视投影)在2D画布上模拟3D效果,这正是GLM-4.7在这个游戏中采用的技术方案。相比WebGL(基于OpenGL ES的浏览器3D图形API)或Three.js等专业3D引擎,纯Canvas实现3D效果的难度更高,因为需要手动处理深度排序、透视变换、光照计算等底层逻辑。
GLM-4.7成功实现了这个复杂项目。皮卡车上配备机枪,玩家可用鼠标瞄准射击远处的恐龙;小型恐龙打两三枪即可击倒,大型恐龙需要更多弹药;恐龙被攻击后还会主动逃跑;远处有雾气蒙蒙的山脉效果,整体氛围感十足。
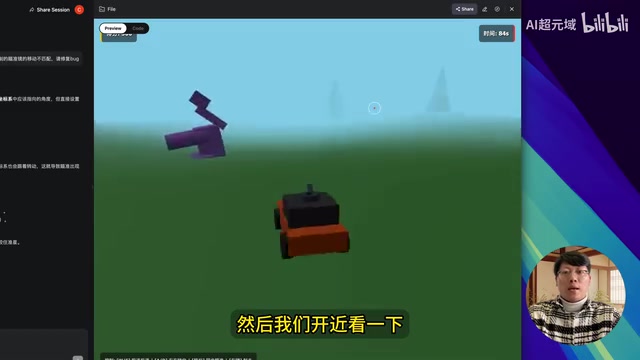
这个测试综合考察了3D图形渲染、物理碰撞检测、AI行为系统、多模态交互以及大规模复杂代码的组织能力,GLM-4.7一次生成就跑通了整个项目,表现相当出色。
数学推导动画与PPT自动生成
GLM-4.7还顺利完成了两个附加任务。一个是圆面积公式推导的可视化动画——将圆切割成64份后重排为近似长方形,配合文字说明切割原理、重排原理和极限思想,即使完全没有数学基础的人也能直观理解推导过程。
另一个是给定一个关于GLM-4.7模型介绍的链接,它能自动提取网页内容并生成结构完整的PPT,涵盖模型参数、核心特性、基准测试数据等关键信息,省去了大量手动整理的时间。
工具调用与浏览器自动化实测
通过Claude Code集成GLM-4.7的API,配合Google官方的Chrome DevTools MCP,进一步测试了浏览器自动化能力。
MCP(Model Context Protocol,模型上下文协议)是Anthropic于2024年底推出的开放标准协议,旨在为AI模型提供统一的外部工具调用接口。通过MCP,大语言模型可以像调用API一样操控浏览器、数据库、文件系统等外部资源,而无需为每个工具单独编写适配代码。文中使用的Chrome DevTools MCP就是Google基于该协议开发的浏览器控制工具,允许AI模型通过Chrome开发者工具协议来导航网页、点击元素、提取内容。这种"模型+工具"的组合正是Agentic AI(智能体AI)的核心范式——模型不再只是生成文本,而是能够自主规划任务步骤、调用工具执行操作、根据反馈调整策略,从而完成复杂的多步骤任务。
测试任务是:访问一个博客网站,点击前三篇文章,提取文章内容并改写为适合X(Twitter)发布的帖子。
GLM-4.7准确完成了整个流程——自动打开浏览器、依次点击三篇博客文章、返回首页、提取核心内容,最终输出了三篇带emoji表情和话题标签的高质量推文。整个过程运行速度快,逻辑清晰,没有出现任何卡顿或错误。
这说明GLM-4.7不仅代码写得好,在Agentic场景下的工具调用和多步骤任务执行能力同样可靠。
终极挑战:iOS原生APP端到端开发
最具挑战性的测试来了——让GLM-4.7在Claude Code中独立开发一款完整的iOS原生背单词APP。技术栈要求包括iOS 17、Swift 5.9、SwiftUI、SwiftData和SwiftCharts,全部使用苹果最新技术框架。
这套技术栈代表了苹果生态最前沿的开发框架组合。SwiftUI是苹果于2019年推出的声明式UI框架,开发者只需描述界面"应该是什么样子",框架会自动处理渲染和状态更新,大幅简化了传统UIKit的命令式编程模式。SwiftData是2023年WWDC上发布的数据持久化框架,用于替代已有十余年历史的Core Data,提供了更简洁的Swift原生API来管理本地数据库。SwiftCharts则是苹果原生的图表绘制框架,支持柱状图、折线图、饼图等多种可视化形式。要求AI模型同时掌握这些框架并协调使用,相当于考察一个高级iOS开发工程师的全栈能力,因为即使是人类开发者,熟练运用这套最新技术栈也需要相当的学习和实践积累。
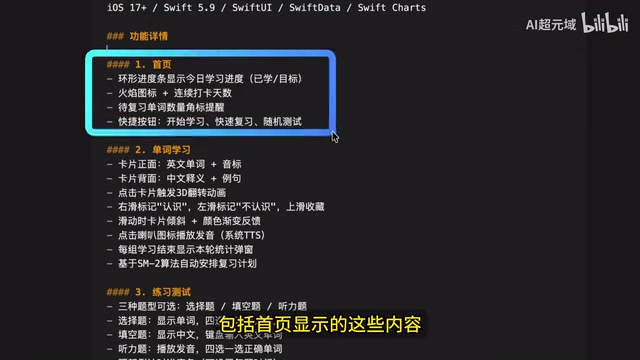
功能需求涵盖以下模块:
- 首页展示每日学习目标和学习进度
- 单词卡片支持正反面3D翻转动画
- 左右滑动切换单词
- 练习测试模块(选择题形式)
- 学习进度统计图表(基于SwiftCharts)
- 设置页面(每日目标、提醒等)
其中,背单词APP的核心学习逻辑涉及间隔重复(Spaced Repetition)算法,这是认知科学中经过大量实验验证的记忆优化方法。其核心原理基于艾宾浩斯遗忘曲线——人类对新学知识的遗忘速度先快后慢,因此在即将遗忘的时间节点进行复习,可以用最少的复习次数达到最佳记忆效果。最经典的实现是SM-2算法(SuperMemo 2),被Anki等主流记忆软件广泛采用。该算法会根据用户对每个知识点的掌握程度动态调整下次复习的时间间隔:回答正确则间隔延长,回答错误则间隔缩短。
经过大约十多分钟的自动开发,GLM-4.7成功完成了绝大部分功能。在Xcode中编译通过后,APP运行效果良好:卡片左右滑动切换流畅、3D翻转动画自然、"已掌握"标记功能正常、练习模块和进度统计图表均可正常使用。唯一未实现的是设置页面,但这完全可以通过追加指令继续补全。
这个测试综合考察了iOS原生开发全栈能力、复杂手势交互与动画系统设计、间隔重复学习算法的工程实现、多模块应用架构组织,以及从零到一的端到端产品开发能力。GLM-4.7能在一次对话中完成如此复杂的工程项目,确实令人印象深刻。
GLM-4.7使用方式与API接入指南
目前GLM-4.7提供多种使用途径:
- 海外用户:直接访问chat.z.ai使用网页版对话,或通过z.ai平台获取API Key进行开发
- 国内用户:通过BigModel平台使用GLM-4.7在线对话,或创建API Key接入自己的项目
- Claude Code集成:设置好Base URL、API Key和模型ID,即可在Claude Code中调用GLM-4.7作为后端模型
由于采用MIT开源协议,开发者也可以自行部署私有化版本,灵活性非常高。
总结:GLM-4.7编程能力究竟几何?
通过前端开发、浏览器自动化、iOS原生APP开发等多维度实测,GLM-4.7展现出了相当全面的编程综合能力:
- 前端开发能力突出:从简单SVG动画到复杂3D游戏,一次性生成的代码质量很高,可运行性强
- 工具调用稳定可靠:浏览器自动化流程流畅准确,MCP集成无障碍
- 复杂工程能力过硬:能独立完成iOS原生APP的端到端开发,架构清晰、功能完整
- 兼顾技术与美学:在满足功能需求的同时,生成的界面和动画都有不错的视觉表现
作为一款MIT协议的开源模型,GLM-4.7在编程和Agentic能力上确实已经接近Gemini和Claude Sonnet 4.5的水平,尤其在代码生成的完整性和可运行性方面表现出色。对于开发者来说,这意味着又多了一个强大且免费的AI编程助手可以选择——而且是完全开源、可自由商用的。
如果你正在寻找一款靠谱的AI编程工具,GLM-4.7值得一试。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。