GLM-5.2深度解析:百万上下文、MIT开源与国产算力全栈突破

48小时内的戏剧性对比
6月12日,美国政府下达出口管制令,要求Anthropic立即切断所有外籍用户对Claude Sonnet 5和Haiku 5两款最先进模型的访问。其中Sonnet 5上线仅三天就被迫下架,Anthropic当天发声明表示服从但不认同,随即将美国国防部告上法庭。
仅仅一天之后,6月13日傍晚,智谱就宣布GLM-5.2全面向开发者开放,并承诺下周以MIT协议开源。同一个48小时窗口里,世界上最强的闭源模型在关门,国产开源模型在开窗——这个时间差打得极其精准。
智谱官方的表态也很直白:"前沿智能不应该只属于少数人,也不应该被少数规则随时收回。"
这背后至少有三层战略考量:
- 提供开放替代:为被切断顶级闭源模型访问的海外开发者提供可用选项
- 抢占开发者心智:在国产开发者群体中完成市场卡位
- 巩固开源生态位:确立国产开源在最前沿的竞争地位
三层叠加,才能理解这次"突袭式发布"为何如此急迫。
不过有个细节必须说清楚:截至发稿时,GLM-5.2的独立API尚未正式上线,目前仅订阅了Coding Plan的用户可以使用,全面免费开放还需等待数日。
百万Token上下文:从标称到真正可用

GLM-5.2的第一个核心卖点,是100万Token的超长上下文窗口。100万Token折算成中文大约50万字,相当于三本《红楼梦》的体量。
这个数字本身并不稀奇,目前好几家大模型都标称百万级上下文。但智谱反复强调一个关键词——"真正可用"。这四个字话里有话:市面上那些标称百万上下文的模型,实际使用中往往到不了那个长度,要么中间内容记不住,要么直接报错。智谱的意思是,GLM-5.2的100万Token是能真正用满的。
一个社区实测案例颇具说服力:有开发者在GLM-5.2上单回合完成了约17.7万Token的工作量,更关键的是,模型在这一轮中自动发现了一个致命Bug——而这个Bug此前人工Review并未检出。这说明它不光"装得多",还能在大上下文中"真的干活"。
与上一代相比,提升更加直观:GLM-5.1的上下文为20万Token,GLM-5.2直接翻了5倍。对程序员而言,这意味着可以把一整个大型代码库一次性塞进去做全局重构,而不是切切补补。
GLM-5.2双思考模式设计
GLM-5.2支持两种思考模式:
- 思考模式:模型会先推理再作答,适合复杂编程和逻辑任务
- 标准模式:直接给出答案,响应更快
代价是思考模式下首个Token需要等待30到60秒,急性子用户会比较难受。
智谱给GLM-5.2的定位也很明确——智能体工程。从以前那种"凭感觉写代码"的氛围编程,进化到能自己规划、自己执行、自己验证的长程智能体。
跑分迷雾:别把前代成绩张冠李戴

关于GLM-5.2的跑分,网上已经流传一堆数字——77.8、58.4、95.3等等。但必须明确指出:**截至目前,GLM-5.2自己的官方跑分一个都还没公布。**网上流传的那些高分,全部来自GLM-5或GLM-5.1,被张冠李戴到了5.2头上。
要衡量GLM-5.2的实力,只能拿前代作参照:
| 模型 | 基准测试 | 得分 | 对比 |
|---|---|---|---|
| GLM-5.1 | SWE-Bench PRO | 58.4 | 超过GPT 57.7、Claude Opus 57.3 |
| GLM-5 | SWE-Bench Verified | 77.8% | 开源第一梯队 |
这些数字表明国产开源大模型确实已经摸到世界第一梯队,但跑分和实际手感从来是两码事。知乎上有开发者实测后的原话是:"刨除审美和多模态,GLM-5.2真能跟Claude Opus掰手腕。"社区评测NOWBON在五个工程任务中给了三个A档。
争议同样存在。Linux社区有人讨论跑分虚高的问题,一个第三方早期评测给出约81分,比Opus和Sonnet低了约6%。不过这是单点数据,佐证力有限。
我的判断是:GLM-5.2的真实水平,得等权重开源、社区大规模复测之后才能下定论。在这个节点上,任何斩钉截铁的排名都不太负责任。
GLM-5.2开源协议与国产芯片适配详解
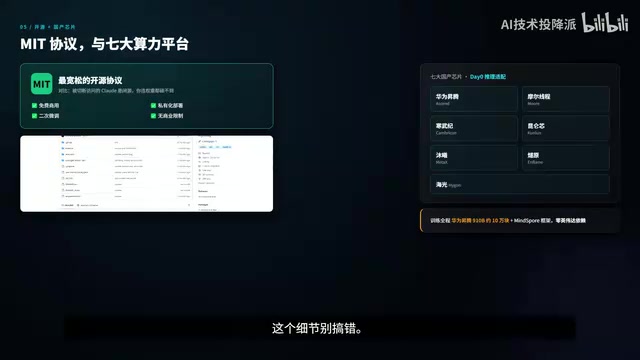
MIT协议的分量
这次GLM-5.2采用的MIT协议,是目前最宽松的开源协议之一。具体意味着:
- ✅ 可以免费商用
- ✅ 可以私有化部署
- ✅ 可以基于它二次微调
- ✅ 没有任何商业限制
对比一下:被切断访问的Claude是闭源的,用户连权重都碰不到。一个对你关门、随时可能被收回;一个直接把代码和权重交到你手里。这就是MIT协议在当下环境中的战略分量。
华为昇腾全栈国产算力训练
GLM-5系列从头到尾在华为昇腾910B芯片上训练,大约使用了10万块,配套华为自研的MindSpore框架,全程零英伟达依赖。此外还完成了7大国产芯片的推理适配,包括:
- 华为昇腾
- 摩尔线程
- 寒武纪
- 昆仑芯
- 沐曦
- 燧原
- 海光
发布当天即可运行(D-0适配)。
但这里需要踩一脚刹车:**7大芯片适配的成果,公开报道中明确属于GLM-5和GLM-5.1。截至目前,尚未有任何来源确认GLM-5.2已完成这7家的适配。**更准确的说法是"GLM-5系列已适配7大国产芯片",而非"GLM-5.2适配了7大芯片"。
此外,下周开源是官方承诺,但Hugging Face和GitHub上目前还看不到GLM-5.2的独立权重。承诺和落地有时会差几天,等权重真正放出来,才是开源的最后一公里。
GLM-5.2实战选型:强项与局限全面分析

强项:长上下文场景
- 超大代码库全局重构:100万上下文一次性吃下整个项目,告别切切补补
- 超长文档审阅:合同、研报逐条处理,有耐心不遗漏
- 长程智能体任务:自动撰写完整金融研报、编写长篇教材等复杂工作流
四个明确局限
- 不支持原生视觉多模态:看图、理解视频需要让位给多模态版本
- 超长上下文的幻觉风险:上下文拉得越长,多轮对话积累下来幻觉风险越高,混合专家架构在超长任务链路上还可能出现路由漂移
- 延迟与成本偏高:思考模式首Token等待30-60秒,不适合实时交互和客服场景;高峰期三倍计费,成本不低
- 审美与文档能力优于纯代码:社区普遍反馈其文档能力比纯代码能力更强,跑分和实战可能存在落差
GLM-5.2价格参考
GLM-5.2在智谱内部定位为直接对标Claude Opus的高阶模型,额度消耗按高阶计算:
- Max套餐:每月469元(多个来源一致)
- Lite和Pro套餐:价格存在出入(有说49/140,也有说20/100),建议以智谱官网实时价格为准
- 新用户:5天免费试用
- 独立API:按量计费单价尚未公布,参考前代约为每百万Token 3美元
一句话选型建议:复杂编程+大上下文,选GLM-5.2;需要图像理解或实时低延迟,绕开它。
超越技术参数的战略意义
别只把GLM-5.2当成又一次模型迭代。在那个48小时的背景下,它给"开放对封锁"这个叙事提供了一个中国的落点。
当世界上最前沿的闭源模型可以被一纸命令随时收回的时候,一个MIT协议、权重公开、人人可部署的国产开源大模型,提供的是一种确定性。这种确定性,对开发者来说,比跑分高几分重要得多。
当然,仍有三个悬念留给时间验证:
- GLM-5.2自己的官方跑分到底什么水平?
- 权重能否下周如约开源?
- 7大国产芯片能否顺利完成5.2的适配?
对开发者而言,最实际的行动建议是:等API上线后亲自上手测试,体感骗不了人。前沿智能,应该开放、可用、可构建,并且服务于每一位开发者。
相关推荐

别再手写Prompt了:让AI代理自己提示自己
深度解析AI编程范式转变:从手动编写Prompt到构建代理自提示循环系统。了解如何通过代理自审代码、主动获取上下文等方法,实现规模化高质量AI编程,从Prompt工程师进阶为代理系统设计师。

SpaceX收购Cursor背后:马斯克600亿美元的真正野心
SpaceX以600亿美元全股票方式收购Cursor母公司Anysphere,马斯克看中的不只是代码编辑器,而是AI驱动的软件生产线入口和真实工作流数据。深度解析这笔交易的战略逻辑、潜在风险与AI编程赛道格局。
Cursor实战:15分钟开发图书馆管理系统全流程
详解使用Cursor AI编程工具15分钟开发FastAPI+Vue3图书馆借阅管理系统的完整流程,包括结构化提示词设计、Plan与Build分步策略、Bug修复技巧及实践经验总结。