Google AI Studio使用教程:Gemini实战指南从入门到精通
全面解析Google Gemini三种使用方式及AI Studio核心功能与实战工作流
Google Gemini凭借与谷歌生态的深度整合,正在重新定义AI工作流的实用性。本文系统梳理了Gemini的三种使用方式:官网直接对话(含Canvas和Deep Research功能)、谷歌应用侧边栏集成、以及Google AI Studio专业平台。重点介绍了AI Studio的温度参数、系统指令、提示词画廊等核心设置,并展示了YouTube视频解析、网页信息提取、语音生成、Imagen 4文生图、Gemini Live多模态实时交互及一句话造App等实战应用场景。
Google Gemini 作为后发的大语言模型,在最新的数学推理和编程基准测试中已经超越了 OpenAI O3、Claude 4 和 DeepSeek R1,稳居榜首。这里涉及的基准测试通常包括 MATH(高中及竞赛级数学题)、GPQA(研究生级别科学问答)、HumanEval 和 SWE-bench(代码生成与软件工程能力评估)等标准化评测。不过,基准分数并不总能反映真实使用体验,比排名更有价值的,是它与谷歌生态系统的深度整合——从 YouTube 视频解析到 Gmail 邮件处理,从语音生成到应用开发,Gemini 正在重新定义 AI 工作流的实用性边界。
本文将从入门到进阶,系统梳理 Gemini 的三种使用方式和 Google AI Studio 的核心功能,帮助你真正将 AI 融入日常工作流程。
三种方式使用 Gemini:从零门槛到专业级
方式一:Gemini 官网直接对话
最简单的方式就是打开 Gemini 官网或 App 直接对话,零门槛,有手就能用。官网界面看似与其他大模型类似,但底部有两个特色功能开关值得关注:
- Canvas 功能:开启后屏幕右侧会分出一个编辑器,将输出结果以文档形式呈现。你可以在里面随意编辑,调整篇幅长短(扩写或精简),设定语气风格(口语化或正式),甚至选中某一处要求重写。
- Deep Research 功能:这是 Gemini 2.5 更新的重大功能,开启后可以同时搜索和浏览数百个网站,帮你解决垂直细分问题,具备任务优先级排序和问题识别能力。结合 Canvas 使用,还能将研究报告一键转成网页、信息图,甚至支持超过 24 种语言的播客输出。
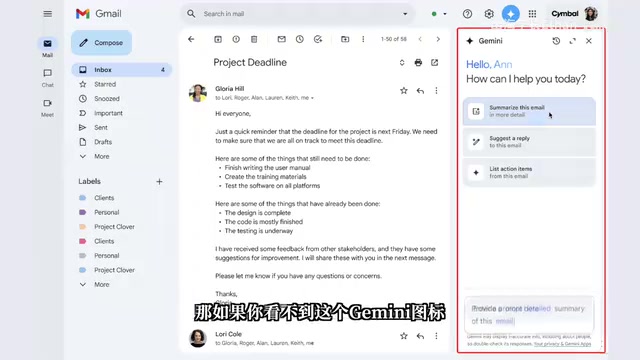
方式二:谷歌应用侧边栏集成
在 Gmail、Google Sheets、Google Docs 等谷歌应用中,点击右上角的 Gemini 图标即可在侧边栏直接调用 AI 能力。回复邮件时让 Gemini 生成格式完整的邮件内容,在 Google Sheets 中快速生成图表,甚至在谷歌搜索栏中直接唤起 Gemini——这种无缝集成才是谷歌生态的真正优势。
方式三:Google AI Studio 专业平台
Google AI Studio 是面向开发者和创作者的工具平台,功能选项远比 Gemini 官网丰富。同样的问题在这里可以得到更专业、更深入的回答。如果你使用 AI 的目的是提升工作效率,Google AI Studio 是更合适的选择。
Google AI Studio 核心设置详解
进入 Google AI Studio 后,界面中间是指令输入框,右侧是运行设置,默认选择最新的 Gemini 2.5 Pro。以下几个关键设置直接影响输出质量:
温度参数(Temperature):控制 AI 回答的创造力和想象力。数值越高,回答越跳脱、富含想象力;数值越低,回答越严谨、精确,但也可能越死板。根据任务类型灵活调整即可。从技术层面来说,模型生成每个 token 时会计算词汇表中所有候选词的概率分布(logits),温度值作为除数应用于这些 logits:温度低于 1 时概率分布变得更尖锐,高概率词更占优势,输出更确定;高于 1 时分布变得更平坦,低概率词获得更多机会,输出更多样。一般来说,温度为 0 适合事实性问答和代码生成,0.7-1.2 之间适合创意写作和头脑风暴。
System Instructions(系统指令):在输入框上方可以预设 Gemini 的角色、语气和规则。比如设定它是资深营销专家、历史教授,或者要求它用教五岁小孩的方式通俗易懂地回答。如果你经常遇到 AI 回答中途切换成英文的问题,也可以在这里预设"全部用中文输出"。系统指令本质上是提示词工程(Prompt Engineering)中"角色设定"技术的产品化实现——在 API 层面,系统指令被标记为 system 角色,模型会将其视为整个对话过程中不可违背的基础约束,因此在系统指令中设定语言偏好比在每条消息中重复要求更加有效和稳定。
Prompt Gallery(提示词画廊):谷歌已经把各种常见场景的提示词做成了优化过的模板——代码优化、数学题解析、食谱输出、图片生成、营销方案撰写等应有尽有。找到相似任务的模板,微调成自己的需求即可,完全不需要花钱买提示词。
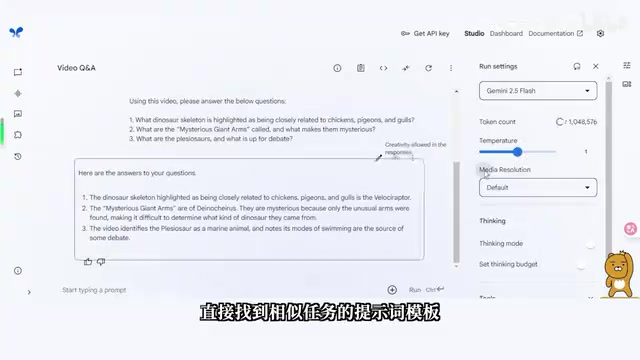
实战工作流:YouTube 视频解析与网页信息提取
网页信息批量处理
日常工作中需要浏览大量网页、提取和整理信息。以往使用 ChatGPT 附上链接,生成的内容常有"幻觉"问题,需要逐一核实。AI 幻觉(Hallucination)是指大语言模型生成看似合理但实际上不准确或完全虚构的内容,这是当前所有 LLM 面临的核心挑战之一,其根本原因在于模型本质上是基于概率的文本生成器,而非知识检索系统。
而 Gemini 可以一次性处理多条网页链接,链接中的文字、图片、视频都能被识别和提取。这得益于谷歌搜索二十多年积累的网页爬取和信息处理能力——包括 Googlebot 网页爬虫、Knowledge Graph 知识图谱,以及检索增强生成(RAG)架构的深度整合,使模型能够在生成回答时实时检索和验证网页信息,而非仅依赖训练时记忆的知识,从而大幅降低了幻觉发生的概率。
YouTube 长视频深度解析
这是 Gemini 最让人惊喜的工作流之一。无论是 YouTube 链接还是本地视频文件,丢给 Gemini 后它就能快速整理和总结。实测将一个小时的 YouTube 视频内容交给 Gemini,不到一分钟就能解析出核心要点和思维逻辑。
对于不理解的知识点,可以继续和 Gemini 对话深入探讨。经过梳理的知识点逻辑清晰,不仅更容易理解,运用起来也更准确有条理。同样的指令交给 ChatGPT,虽然也能给出总结,但内容极其简短,远没有 Gemini 详细和清晰。
更有趣的是,Gemini 还能识别视频片段的来源。比如给它一个影视片段,它不仅能准确识别出自哪部作品,还能分时间段描述视频画面——说明它真的"看懂"了视频内容。这种能力源于 Gemini 原生多模态(Natively Multimodal)的架构设计:与早期将视觉和语言模型分别训练再拼接的方案不同,Gemini 从训练阶段就同时处理文本、图像、音频和视频数据,使用统一的 Transformer 架构进行跨模态理解,因此能够真正理解画面中物体的空间关系、时间序列和语义含义。
多媒体创作:语音生成与文生图
AI 语音生成
在 Google AI Studio 中点击"生成媒体",选择 Gemini 语音生成功能。支持单人和双人模式:
- 单人模式:选择音色,在 Style Instruction 中描述语气风格(如"温暖而友好的语气"),粘贴文案即可生成。
- 双人模式:分别设置两个角色的名称和音色,用脚本生成器像搭积木一样分配台词,即可生成双人对谈音频。
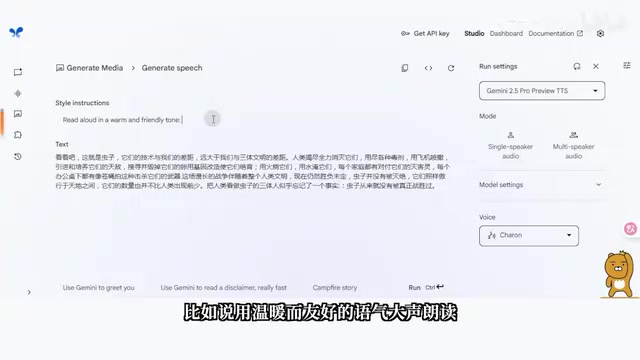
这个功能特别适合自媒体视频配音、影视作品配音,甚至播客音频制作。
Imagen 4 文生图
Google AI Studio 集成了最新的 Imagen 4 模型,突破了 AIGC 长期面临的技术瓶颈——AI 生图中的文字乱码问题。传统文生图模型如 Stable Diffusion 和 DALL-E 在生成文字时频繁出错,根本原因在于扩散模型(Diffusion Model)将图像视为像素级的连续信号进行去噪生成,而文字本质上是离散的符号系统——模型"理解"了字母的视觉形态,却无法保证字符的正确拼写和排列。Imagen 4 通过在扩散过程中引入专门的文字渲染模块,将文本生成从像素级预测提升为字符级精确控制,相当于在图像生成管线中嵌入了一个"排版引擎"。
它不仅能准确生成文字,还能自动调整样式适配图片。实测生成一张包含"2025 Google for Developers"长文字的像素风海报,文字完全没有乱码,还巧妙融合到画面元素中。生成速度也实现了 10 倍提升,基本 10 秒左右即可出图。
Gemini Live:多模态实时交互的终极形态
从 Google AI Studio 左侧分栏的"实时流"进入 Gemini Live,除了文字交流外,还有三个多模态交互功能:
实时语音对话
类似于和 AI 进行一对一的电话沟通,任何不懂的问题都可以像和真人对话一样去问。无论是情感陪伴、口语练习、疑问解答还是头脑风暴,Gemini Live 的表现都相当出色。这种实时交互依赖流式推理(Streaming Inference)技术,模型无需等待完整输入即可开始生成响应,配合谷歌自研的 TPU 芯片集群实现毫秒级延迟,让对话体验接近真人交流的自然节奏。
摄像头实时识别
打开设备摄像头,让 Gemini 作为你的"眼睛和大脑"分析画面内容。看到不认识的动植物可以即时科普,逛博物馆和摄影展时它就是你的私人导游,甚至可以识别护肤品成分帮你选择适合的产品。

屏幕共享协作
这个功能堪称"神器"——开启屏幕共享后,Gemini 可以直接看到你的屏幕内容,相当于 AI 坐在你的电脑前手把手教你操作。工作中遇到任何问题都可以随时求助,AI 的具象化体验在这里达到了新高度。
编程与应用开发:一句话造 App
Gemini 2.5 在编程能力上已经超越 ChatGPT O3 和 Claude 4,尤其是多模态编程能力——一张图加一句提示词就能生成一个小游戏,甚至有人实测 17 秒就用一句话做出了一个可运行的游戏。
在 Google AI Studio 左侧找到拼图样式的构建按钮,用自然语言描述需求就能直接生成 App。这代表了软件开发领域"低代码/无代码"(Low-Code/No-Code)趋势与 AI 编程能力融合的最新阶段。传统低代码平台通过可视化拖拽组件降低开发门槛,而 AI 编程则更进一步——用户只需描述功能需求,模型自动完成架构设计、代码编写、UI 布局和调试,这背后依赖的是大模型在海量开源代码(如 GitHub 数据)上的训练,使其掌握了从前端框架到后端逻辑的完整技术栈。
如果只想做一个自己用的小工具,甚至不需要部署上线,直接在预览模式下日常使用即可。平台还提供了大量公共模块,可以随手创建音乐生成 App,或者用 Gemini 的实时 API 构建对话应用。不过需要注意的是,AI 生成的代码在安全性、可维护性和性能优化方面仍需人工审查,目前更适合原型验证和个人工具开发场景。
写在最后
谷歌 Gemini 的真正竞争力不在于单项能力的排名,而在于它与整个谷歌生态的深度融合。从搜索到邮件,从文档到视频,从语音到编程,Gemini 正在构建一个真正意义上的 AI 全家桶工作流。
每一次使用都是在帮助你成为 AI 时代的原住民,将 AI 更丝滑地融入日常工作和生活。毕竟,人类最有价值的资源就是时间,而 AI 的意义正是帮我们把时间从重复劳动中解放出来。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。