Google Gemma 4实测:手机离线运行+Ollama部署教程
Google Gemma 4开源模型实现手机端本地运行,兼顾隐私与性能
Google发布Gemma 4系列开源模型(1B至31B参数),通过量化技术和MOE混合专家架构,实现了从手机到工作站的全场景本地部署。实测显示小模型在常识推理上仍有短板,但在文档识别、代码补全等工具型任务上表现出色,且完全本地运行保障数据隐私。文章还提供了Ollama + Claude Code的完整部署教程。
Google近期发布的Gemma 4系列开源模型,堪称一次"把超级大脑装进手机"的工程奇迹。从2B参数的轻量版到31B的旗舰版,覆盖了从手机到工作站的全场景需求。B站UP主对这款模型进行了三台真机对比测试,并给出了Ollama + Claude Code的完整部署教程,让我们一起来看看这款模型的真实表现。
Gemma 4的技术背景与开源生态定位
Google的Gemma系列模型源自其内部的Gemini大模型技术栈,采用了相同的研究成果和训练方法论,但以更小的参数规模和开源许可证发布。这一策略使得Google在开源AI社区中建立了强大的影响力,与Meta的LLaMA系列形成直接竞争。Gemma 4的发布时间节点恰逢端侧AI(On-device AI)需求爆发期——高通、联发科等芯片厂商纷纷在移动SoC中集成专用NPU(神经网络处理单元),为本地大模型推理提供了硬件基础。正是软硬件生态的同步成熟,才使得"手机上跑大模型"从概念走向了现实。
Gemma 4四款模型覆盖全场景
Gemma 4系列一共推出了四款模型,针对不同硬件条件的用户精准定位:
1B/2B(Nano级):最轻量的版本,手机和树莓派都能运行,自带语音识别功能,量化后仅需4GB显存。这是真正意义上的"口袋AI"。这里提到的"量化"是一种关键的模型压缩技术——原始模型通常使用FP32(32位浮点数)或FP16(16位浮点数)存储参数权重,而量化将其降低到INT8(8位整数)甚至INT4(4位整数)精度。这种做法会牺牲少量推理精度,但能将模型体积和显存占用降低4-8倍,同时显著提升推理速度。常见的量化格式包括GPTQ、AWQ和GGUF,其中GGUF是Ollama默认使用的格式,专为CPU和混合推理场景优化。
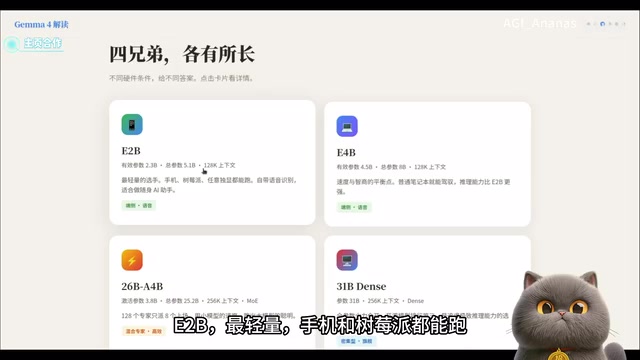
4B(Quadro级):笔记本甜品级选手,在速度和能力之间找到了平衡点。
26B(MOE混合专家架构):总参数25B,但每次推理仅激活3.8B参数——用小模型的成本干大模型的活,性价比极高。
31B(Dense旗舰级):全参数推理,在开源模型排行榜上位列第三,适合拥有高端显卡的用户。
Dense vs MOE:理解Gemma 4的关键概念
理解Gemma 4系列,有一个核心概念必须搞清楚——Dense(密集型)和MOE(混合专家)的区别。
Dense模式下,每次推理时所有参数都参与计算。31B就意味着310亿次运算,一个不少。优点是结果稳定,缺点是速度慢且显存消耗大。
MOE模式则完全不同。模型内部有128个"专家",但每次推理只派8个上场,其余待命。这意味着虽然总参数量很大,但实际计算量大幅降低。
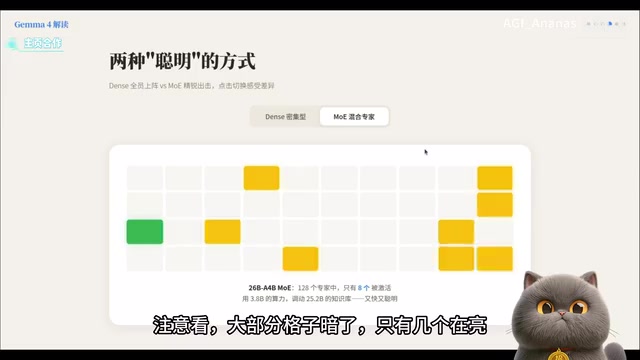
上图直观展示了MOE的工作原理:大部分"格子"处于暗灭状态,只有少数几个在亮——这就是混合专家架构的精髓所在。用更少的计算资源,换取接近大模型的推理能力。
MOE架构的技术深度解析
混合专家(Mixture of Experts)架构最早由Hinton等人在1991年提出,但直到2022年Google的Switch Transformer和后来Mistral AI发布的Mixtral模型才将其推向主流应用。MOE的核心组件包括两部分:多个专家网络(通常是Transformer中的前馈神经网络层)和一个门控网络(Router/Gating Network)。门控网络负责根据输入token的语义特征,决定将其分配给哪些专家处理。
这种设计的数学优势在于:模型的总参数量(决定知识容量上限)可以做得很大,但每次前向传播的实际计算量(FLOPs)只与被激活的专家数量成正比。Gemma 4的26B MOE模型拥有128个专家但每次仅激活8个,这意味着其推理计算成本仅相当于一个3.8B参数的Dense模型,却拥有接近25B模型的知识储备和泛化能力。这也解释了为什么MOE模型在"性价比"维度上具有压倒性优势。
不过MOE架构也有其挑战:专家负载均衡(避免某些专家被过度使用而其他专家闲置)、训练稳定性、以及模型总体积仍然较大(虽然推理快,但加载时需要将所有专家权重载入内存)。Gemma 4在这些方面的工程优化,代表了当前业界的最佳实践水平。
三台手机实测:本地离线运行表现
测试使用了三台手机在完全离线的环境下运行Gemma 4的1/2B模型,测试内容包括三个经典问题:加油问题、脑筋急转弯问题、字符出现次数统计问题。
测试结果揭示了两个关键发现:
-
常识判断仍是小模型的短板:在需要常识推理的问题上,小参数模型的表现依然不够理想,这是当前所有轻量级模型的共性问题。这一现象的根本原因在于,常识推理需要模型在训练过程中建立对现实世界的隐式知识表征,而这种能力与模型参数量高度相关——参数越少,能够编码的世界知识就越有限。当前学术界对此的主流解决思路包括:检索增强生成(RAG)为小模型补充外部知识、蒸馏大模型的推理能力到小模型、以及通过Chain-of-Thought提示引导小模型进行分步推理。
-
硬件差异显著:三台手机中,iQOO 15的运行速度最快,说明芯片的AI算力对本地推理体验影响巨大。现代手机SoC中的NPU(如高通的Hexagon、联发科的APU、三星的Exynos NPU)专门针对矩阵运算和低精度推理进行了硬件加速,其INT8算力可达数十TOPS(每秒万亿次运算),这是本地大模型能够流畅运行的硬件基础。不同芯片的NPU架构差异,直接决定了推理速度的上限。
Gemma 4能力边界:工具型AI的正确定位
Gemma 4的强项非常明确:文档识别、发票解析、代码补全、长文档问答、Agent自动化任务。更重要的是,所有这些都跑在本地,你的数据永远不用上传到别人的服务器,这对隐私敏感场景意义重大。

本地部署大模型的隐私价值不仅是"数据不上传"这么简单。在企业场景中,这涉及到GDPR(欧盟通用数据保护条例)、中国《数据安全法》和《个人信息保护法》等法规的合规要求。许多行业(如医疗、金融、法律)的敏感数据根本不允许离开本地网络环境。端侧AI使得这些受监管行业也能享受大模型的生产力提升,而无需面对数据出境、第三方数据处理协议等复杂的合规挑战。此外,本地推理还消除了网络延迟和API服务中断的风险,确保了业务连续性。
但它的短板同样需要正视:
- 能否替代Claude或GPT? 显然不行。云端大模型(如GPT-4、Claude 3.5)的参数规模通常在数千亿甚至万亿级别,且经过了大规模RLHF(基于人类反馈的强化学习)对齐训练,在复杂推理、创意写作和多轮对话方面的能力远超当前的开源轻量模型。
- 高质量写作? 勉强可以,但不要期望太高。
- 大规模代码重构? 以当前能力还差得很远。
用UP主的原话总结:"Gemma 4是一个极其出色的本地工具型AI。你把它当高效工具用,它不会让你失望;如果你把它当全能大脑用,那你就会很失望。"这个定位非常精准。
实战教程:Ollama + Claude Code部署Gemma 4
手机端部署
手机用户最简单,直接前往Google的AI Edge Gallery下载使用即可,无需额外配置。
电脑端:Ollama一键部署Gemma 4
电脑端通过Ollama部署同样非常便捷。Ollama是一个开源的本地大模型运行框架,它封装了llama.cpp的底层推理引擎,提供了类似Docker的模型管理体验。用户无需手动处理模型格式转换、内存映射或GPU调度等复杂问题。Ollama支持GGUF格式模型,能够自动检测系统的GPU(NVIDIA CUDA、AMD ROCm、Apple Metal)并进行最优的模型层分配——当GPU显存不足时,会自动将部分模型层卸载到CPU内存中运行(即所谓的offloading策略),以牺牲少量速度换取可运行性。其内置的HTTP API服务器兼容OpenAI API格式,使得几乎所有支持OpenAI接口的应用都能无缝切换到本地模型。
以下是完整部署步骤:
第一步:下载并运行模型
确保电脑上已安装Ollama,然后执行命令:
ollama run gemma4:e4b
等待模型下载完成,总计约9.6GB。下载成功后可在终端直接测试问答。
第二步:配置Claude Code调用本地模型
Claude Code是Anthropic推出的命令行AI编程助手,原本依赖云端Claude模型。将其配置为调用本地Ollama模型,本质上是利用了Claude Code优秀的交互界面和工具调用框架(如文件读写、命令执行等),同时将推理后端替换为本地运行的开源模型。这种架构分离(前端交互层与后端推理层解耦)是当前AI工具链的重要设计趋势,它允许用户根据任务复杂度、隐私需求和成本预算灵活切换不同的模型后端。
具体配置步骤:
- 复制模型ID
- 克隆项目仓库,进入项目目录
- 运行安装命令,下载依赖
- 进入引导界面,选择颜色模式
- 选择"本地Ollama模型"选项
- 粘贴模型ID,回车确认
配置完成后即可在Claude Code中直接调用本地Gemma 4模型进行问答。首次请求时模型加载耗时约38秒(模型需要从磁盘加载到GPU显存中),后续响应会更快,因为模型会保持在内存中直到超时释放。
切换模型:已登录用户输入/logout退出,然后运行配置命令即可重新选择模型。
总结:Gemma 4的价值与局限
Gemma 4系列的发布,标志着开源模型在"端侧部署"方向上迈出了重要一步。4GB显存就能运行大模型,这在一年前还是不可想象的。
对于普通用户而言,Gemma 4最大的价值在于隐私保护和零成本使用——不需要API Key,不需要网络连接,不需要担心数据泄露。对于开发者而言,MOE架构的工程实现为未来更多轻量化模型提供了可借鉴的范式。从更宏观的视角来看,Gemma 4代表了AI民主化的重要里程碑:当强大的AI能力不再被少数云服务商垄断,而是可以运行在每个人的设备上时,整个AI应用生态的创新空间将被极大拓展。
当然,我们也要理性看待它的局限性。小模型在常识推理、复杂写作和大规模代码工程上的短板,短期内很难通过架构优化完全弥补——这些能力的提升本质上依赖于更大的参数规模和更丰富的训练数据。选择合适的场景,用对工具,才是发挥Gemma 4最大价值的关键。
目前模型权重已在Hugging Face和Kaggle上开放下载,感兴趣的读者可以立即上手体验。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。