Google Vids免费做3D动画:Veo 3.1从零到成片完整教程

Google Vids免费集成Veo 3.1,可从零制作完整3D动画短片
Google Vids是隐藏在Google Docs套件中的免费视频创作工具,内置Veo 3.1视频生成模型,集成图像生成、视频转换、音效、字幕和编辑功能。用户只需用ChatGPT生成故事框架和提示词,再在Google Vids中完成角色设计、动画生成、字幕添加和导出,即可在几分钟内制作出带配音、唇形同步和环境音效的完整动画短片,且目前完全免费,但免费窗口期可能随时结束。
当Grok的免费动画功能被锁进付费墙后,一个隐藏在Google Docs套件中的免费工具浮出水面——Google Vids。它集成了图像生成、Veo 3.1视频转换、音效、字幕和视频编辑功能,让你从零开始制作一部完整的3D风格动画短片,而且目前完全免费。
为什么Google Vids值得关注
大多数人制作一段动画短片,至少需要五个工具:图像生成器、视频转换工具、音效库、字幕编辑器和视频剪辑软件。而Google Vids将这一切整合在了一个平台内。
Google Vids于2024年在Google Workspace中首次亮相,定位为继Docs、Sheets、Slides之后的第四大生产力工具。Google Workspace(前身为G Suite)是Google面向企业和个人用户的云端协作套件,全球拥有超过30亿用户。将视频创作工具嵌入这一生态的战略意义在于:用户无需离开熟悉的工作环境即可完成从文档撰写到视频制作的全流程。这种"超级应用"策略与微软将Copilot嵌入Office 365的路径类似,本质上是通过AI能力提升既有平台的用户粘性和付费转化率。
更关键的是,它内置了Google最新的Veo 3.1模型——这是企业级用户正在付费使用的视频生成模型。Veo 3.1是Google DeepMind开发的最新一代视频生成模型,属于扩散模型(Diffusion Model)家族的进化产物。扩散模型的核心原理是先向数据中逐步添加噪声,再训练神经网络学习逆向去噪过程,从而从随机噪声中生成高质量内容。Veo 3.1相比前代的关键突破在于原生音频生成能力——它不仅处理视觉帧序列,还同时建模音频波形,实现了视听联合生成。
Veo 3.1不仅能让静态图片动起来,还能自动生成角色对白(带唇形同步)、环境音效,甚至根据场景变化调整声音设计。其中,唇形同步(Lip Sync)技术依赖于音素到视素(Phoneme-to-Viseme)的映射模型,系统根据生成的语音内容自动计算口型变化并与面部动画对齐。这意味着你不需要录制人声、不需要搜索音效素材,只需输入文字提示词,模型就能自动处理视觉和听觉的全部内容。在行业竞争格局中,Veo 3.1的主要对手包括OpenAI的Sora、Runway的Gen-3 Alpha和Pika Labs的产品,但Veo 3.1在音频集成方面目前处于领先地位。
不过需要注意的是,这种免费策略不会永远持续。文中提到的"先免费后付费"策略在科技行业被称为免费增值模式(Freemium Model),在AI工具领域尤为普遍:OpenAI的ChatGPT、Midjourney的图像生成、xAI的Grok动画功能都经历了从免费到收费的转变。其商业逻辑是:免费期间快速积累用户基数和使用数据,利用网络效应建立竞争壁垒,同时通过真实用户反馈迭代产品,最终在用户形成依赖后引入付费层级。对于Google而言,Vids的免费策略还有额外目的——将用户锁定在Google Workspace生态中,提升整个套件的付费订阅转化率,而非仅靠单一工具盈利。Grok已经证明了这一点——先免费吸引用户,再转为付费。所以如果你想体验,现在就是最佳时机。
第一步:用ChatGPT生成完整的动画故事框架
每个优秀的动画都始于一个好故事,而你甚至不需要自己写。
将专门设计的故事提示词粘贴到ChatGPT中,几秒钟内它就会输出一整套创作素材:
- 完整的故事剧本:包含起承转合的叙事结构
- 详细的角色提示词:确保角色在每一幕中保持视觉一致性
- 文生图提示词:用于生成角色的初始图像
- 11个场景的图生视频提示词:每段都内置了简短对白
这套提示词体系的精妙之处在于,它不仅规划了视觉内容,还预设了每个场景的对话和动作指令,为后续Veo 3.1的视频生成提供了精确的控制参数。这里涉及的核心技术是提示词工程(Prompt Engineering)——通过精心设计输入文本来引导AI模型产生期望输出。在动画制作场景中,提示词的质量直接决定了最终成片的质量。其中"角色提示词"本质上是一种角色一致性约束——通过在每个场景的提示词中重复描述角色的关键视觉特征(服装颜色、体型、标志性配饰等),引导模型在不同生成批次中保持角色外观的连贯性。这解决了AI视频生成领域的一个核心痛点:跨场景角色一致性问题。传统上,即使是最先进的生成模型也容易在不同片段中产生角色"漂移",而结构化的提示词体系可以显著缓解这一问题。
第二步:在Google Vids中生成角色图像
打开Google Docs,你会看到一个名为"Google Vids"的选项——这是Google悄悄添加的全新功能,大多数人甚至不知道它的存在。
进入Google Vids后,将ChatGPT生成的角色提示词和主图提示词合并为一个提示词,粘贴到内置的图片生成器中。选择合适的宽高比(推荐16:9),点击生成。
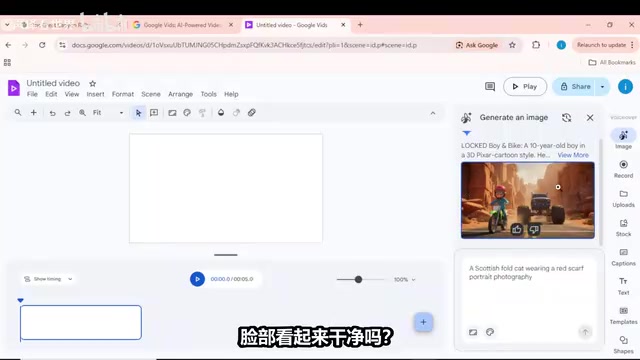
这一步至关重要:在继续之前,仔细审视生成的角色图像。脸部是否干净清晰?颜色是否准确?整体风格是否符合你的预期?如果有任何不满意的地方,果断重新生成。花30秒把角色做对,因为这张图是整个动画的基础——此后每一幕都源自这个角色设计,起点对了,后面一切都会水到渠成。
第三步:用Veo 3.1将静态图片变为3D动画
角色确定后,选中刚才生成的图片,点击"插入"→"转换为视频"。这一步调用的正是Veo 3.1模型。
从技术角度看,这里使用的是图生视频(Image-to-Video)范式——当前AI视频生成的主流方法之一。与纯文生视频(Text-to-Video)相比,它以一张参考图像作为生成的起始帧或条件锚点,从而大幅提升输出的可控性和视觉一致性。技术上,模型将输入图像编码为潜在空间(Latent Space)中的向量表示,然后在此基础上通过时序扩散过程生成后续帧。这种方法的优势在于:参考图像为模型提供了明确的视觉"锚点",减少了纯文本描述带来的歧义性。这也进一步解释了为什么上一步中角色图像的质量如此关键——它是整个动画视觉风格的种子,后续所有场景都从这个视觉基准出发进行生成。
从ChatGPT复制第一个场景的视频提示词,粘贴到生成器中,点击生成。然后见证奇迹发生:你的静态角色开始移动,摩托车轰鸣、尘土飞扬、镜头切换。更令人惊叹的是,角色开始说话——真实的对白配合精准的唇形同步。引擎轰鸣声、风呼啸而过的声音,所有音效都由Veo 3.1自动生成。
你没有录制人声,没有搜索音效,只是输入了文字,Veo 3.1就自主判断了场景应有的视觉效果和声音设计。
接下来对11个场景重复同样的操作流程:
- 从ChatGPT复制对应场景的视频提示词
- 粘贴到Google Vids的视频生成器中
- 点击生成
每个场景只需几秒钟就能生成。有意思的是,角色在不同场景中保持了高度一致性——同样的头盔、同一件夹克、同一辆摩托车,但故事持续推进,声音也随环境变化而演变。新场景带来新的环境音,全部自动生成,无需手动调整。

第四步:自动字幕——提升动画完成度的关键细节
11段动画片段就位后,你已经拥有了一部看起来和听起来都相当不错的短片。但还缺少一个能将"优秀"提升为"卓越"的元素——字幕。
数据表明,带字幕的视频能显著延长观众的观看时长。而在Google Vids中添加字幕几乎是零成本操作:
- 在编辑器中找到字幕选项并点击
- Google Vids自动转录视频中的所有对话
- 角色说的每句话都会生成时间同步的字幕
这一功能基于自动语音识别(ASR, Automatic Speech Recognition)技术。Google在ASR领域有深厚积累,其语音识别引擎支持超过125种语言,底层采用端到端的Transformer架构模型。在动画字幕场景中,系统面临一个独特的技术情境:需要识别的并非真人录制的语音,而是AI合成的角色对白。由于Veo 3.1生成的语音本身就是模型输出,理论上Google可以在生成阶段直接保留文本-音频的对应关系,从而实现近乎完美的转录精度和时间轴对齐,这比传统ASR对自然语音的识别要可靠得多。
你不需要手动输入一个字,也不需要手动调整时间轴同步。系统会自动聆听动画中的对白并完成全部处理。这个功能看似简单,但它省去了传统字幕制作中最耗时的转录和对齐工作。
第五步:导出完整的动画成片
当所有内容都确认无误后,点击左上角的"文件"选项,选择"下载为MP4"。下载时间取决于视频总时长,较长的动画可能需要等待一段时间。
完成后,一部完整的3D风格动画短片就保存在你的设备中了——有角色配音、有唇形同步、有环境音效、有同步字幕,全部在一个免费工具内完成。
Google Vids动画制作流程总结
回顾整个流程,核心工作流非常简洁:
| 步骤 | 工具 | 产出 |
|---|---|---|
| 故事与提示词 | ChatGPT | 完整剧本+11个场景提示词 |
| 角色设计 | Google Vids图像生成 | 角色基准图 |
| 动画生成 | Google Vids + Veo 3.1 | 11段带声音的动画片段 |
| 字幕添加 | Google Vids自动转录 | 同步字幕 |
| 导出 | Google Vids | 完整MP4文件 |
这个工作流的真正价值不在于某个单一功能有多强大,而在于全链路整合带来的效率提升。传统流程中,你需要在多个工具之间反复切换、导入导出、格式转换,每一步都是摩擦成本。Google Vids将这些环节压缩到了一个界面内,大幅降低了创作门槛。
当然,AI生成的动画在质量上仍然无法与专业动画工作室的产出相提并论。但对于内容创作者、教育工作者、独立开发者来说,能够在几分钟内从一个想法变成一部有声有色的动画短片,这本身就是一个巨大的生产力飞跃。关键是现在就去尝试——因为免费窗口期不会永远存在。
核心要点
- Google Vids是隐藏在Google Docs套件中的免费视频创作工具,集成了图像生成、Veo 3.1视频转换、音效、字幕和编辑功能
- Veo 3.1模型能从一张静态图片和文字提示自动生成带角色对白、唇形同步和环境音效的动画视频
- 完整工作流仅需ChatGPT(生成故事和提示词)和Google Vids(生成图像、动画、字幕和导出)两个免费工具
- 角色在11个不同场景中能保持视觉一致性,字幕可由系统自动转录生成,无需手动操作
- 免费策略可能随时改变(Grok已有先例),建议尽早体验
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。