Gemma 4 12B:Google开源模型笔记本即可本地运行
Gemma 4 12B:开源模型的新标杆
Google近日正式发布了Gemma 4 12B模型,这是一款开放权重(open weights)的AI模型,最大的亮点在于——它可以直接在你的笔记本电脑上运行。
在大模型动辄需要数十GB显存、依赖云端算力的今天,一个12B参数量级的模型能够在消费级硬件上本地运行,这对开发者和研究者来说意义重大。
为什么12B参数是本地部署的甜蜜点?
性能与效率的最佳平衡
12B参数量级的模型正在成为开源社区的"黄金尺寸"。相比7B模型,12B在推理能力、知识储备和指令遵循方面有显著提升;而相比70B或更大的模型,它对硬件的要求大幅降低,使得本地部署成为现实。
要理解这一点,需要了解参数量与硬件需求的关系:在大语言模型中,每个参数本质上是神经网络中的一个可学习权重值。以FP16(半精度浮点)格式存储,1B参数约需2GB显存,因此12B模型在FP16下需要约24GB显存。但通过4-bit量化技术,显存需求可压缩至约6-8GB,这恰好落在许多消费级笔记本GPU(如NVIDIA RTX 4060 8GB)或Apple Silicon统一内存的可用范围内——这就是12B成为本地部署甜蜜点的技术原因。
从Google官方的描述来看,Gemma 4 12B被定位为"super capable"(超强能力),这意味着它在同参数量级的模型中具备领先的表现。考虑到Google在Gemma系列上持续投入的训练数据质量和架构优化,这一定位有充分的技术支撑。
笔记本本地运行的实际价值
能在笔记本上运行大模型,对开发者和普通用户而言带来了多重好处:
- 隐私保护:敏感数据无需上传云端,所有推理在本地完成
- 零延迟:无需网络连接即可推理,响应速度更快
- 零成本:不需要支付API调用费用,长期使用更经济
- 可定制:开发者可以自由微调和适配,打造专属模型
这些优势在边缘计算场景中尤为突出。边缘计算是指在数据源头或靠近用户的设备端进行计算处理,典型应用包括智能家居的离线语音助手、医疗影像的本地初筛(患者数据不出院)、工业质检的实时检测,以及开发者的代码辅助工具(企业代码不离开内网)。Gemma 4 12B这类可本地运行的模型,正在打通从"云端AI服务"到"端侧AI能力"的关键一环。
开放权重背后的战略考量
开源大模型的竞争格局
Google选择以开放权重形式发布Gemma 4 12B,延续了Gemma系列的开源策略。在Meta的Llama系列、Mistral、Qwen等开源模型激烈竞争的当下,Google需要持续输出高质量的开源模型来维持其在开发者社区的影响力。
需要指出的是,"open weights"与完全开源(open source)存在本质区别。根据OSI(开源促进会)的定义,真正的开源需要满足公开训练数据、训练代码、模型权重在内的完整可复现性要求。而开放权重仅意味着模型的最终参数文件可供下载使用,训练数据集的构成、数据清洗流程、具体的训练超参数等可能不会完全公开。Google的Gemma系列采用自定义的Gemma许可证,允许商业使用和再分发,但对使用场景有一定限制条款。不过对于大多数开发者而言,开放权重已经足够满足部署和微调需求。
Gemma系列的技术演进脉络
Gemma是Google DeepMind基于Gemini模型架构和训练方法论打造的开放模型系列。从2024年初的Gemma 1(2B/7B)到Gemma 2(2B/9B/27B),再到如今的Gemma 4 12B,该系列在架构设计上持续迭代。Gemma 2引入了交替使用局部注意力和全局注意力的混合机制,以及Group-Query Attention(GQA)等效率优化技术。Gemma 4 12B大概率继承了这些架构创新,并在训练数据规模和质量上进一步提升——Google拥有的网页索引、学术论文、代码库等数据资源,是其训练高质量模型的核心竞争优势。
开发者可以用Gemma 4 12B做什么?
Gemma 4 12B的发布进一步降低了AI应用开发的门槛。开发者可以:
- 在本地快速原型验证,无需配置云端环境
- 构建离线AI应用,适用于边缘计算场景
- 基于开放权重进行领域特定的微调
- 将其集成到现有的本地开发工作流中
本地AI部署的未来展望
随着模型压缩技术的不断进步,以及硬件算力的持续提升,在消费级设备上运行高质量AI模型正在从"勉强可用"走向"流畅体验"。
这里值得展开说明两项关键的模型压缩技术:量化(Quantization)是将模型权重从高精度(如FP32的32位或FP16的16位)降低到更低精度(如INT8、INT4)的过程,以牺牲微小精度换取显著的内存和计算效率提升。目前GGUF格式配合llama.cpp等推理框架,已能支持2-bit到8-bit的多种量化方案。知识蒸馏(Distillation)则是用大模型(教师模型)的输出来训练小模型(学生模型),使小模型在更少参数下逼近大模型的表现。Gemma 4 12B本身很可能就融合了从更大规模Gemini模型蒸馏而来的知识,这也是它能在12B参数下实现"超强能力"的技术基础之一。
Gemma 4 12B的发布是本地AI部署趋势的又一有力证明。对于关注本地AI部署的开发者来说,这款模型值得第一时间体验和评估。建议关注Google官方的模型卡片和基准测试结果,以便更全面地了解Gemma 4 12B在各项任务上的具体表现。
核心要点
相关推荐
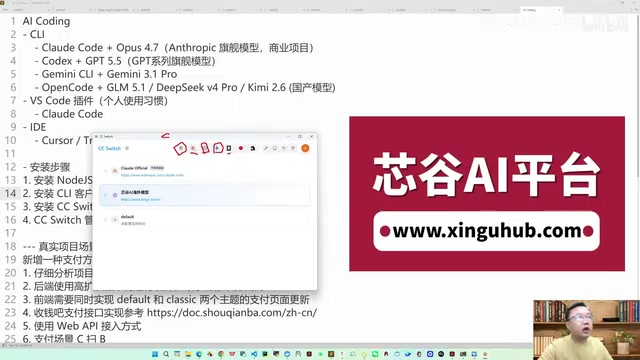
Claude Code实战:60美元4小时完成复杂支付系统二开
通过真实商业案例详解Claude Code + Opus 4.7如何在4小时内完成复杂支付系统二开,涵盖CC Switch配置、Prompt工程技巧、模型选择策略及AI Coding工程化落地方法论。

Vibe Coding入门指南:零基础用AI写代码的完整攻略
Vibe Coding(氛围编程)让零基础用户通过自然语言指令实现软件开发。本文详解Vibe Coding的核心概念、适用场景、推荐工具及实践步骤,帮你快速上手AI编程。

Vibe Coding入门指南:零基础用AI把想法变成产品
Vibe Coding(氛围编程)让零基础用户无需学编程语言,通过自然语言与AI对话即可开发软件产品。本文详解Vibe Coding概念、主流工具(Cursor、Claude Code、Codex)及入门学习路径。