GPT-5.1 Pro深度评测:最聪明的AI困在最烂的界面里

GPT-5.1 Pro推理能力惊人,但受限于糟糕的ChatGPT界面;Codex Max编码实测表现不佳。
OpenAI发布GPT-5.1 Pro和Codex Max两款新模型。GPT-5.1 Pro在密码学谜题测试中展现出惊人推理能力,30分钟解开了人类花三天才解决的DEF CON密码挑战,但它仅限ChatGPT网页使用,界面体验极差且无API访问。Codex Max主打代理式编码,引入上下文压缩等新技术,但实测中在SDK升级任务上频繁出错,引入严重类型安全问题,实际表现远不及宣传。
就在Gemini 3 Pro Preview刚刚发布一天之后,OpenAI便祭出了两款新模型:GPT-5.1 Codex Max和GPT-5.1 Pro。前者专注于长时间运行的代理式编码任务,后者则是一个仅在ChatGPT网站上可用的重量级推理模型。知名开发者Theo在获得早期访问权限后进行了深度测试,结论令人五味杂陈——这可能是目前最聪明的AI模型,但它被困在了一个糟糕的界面里。
GPT-5.1 Pro推理能力实测:30分钟解开三天的密码谜题
为了测试GPT-5.1 Pro的推理能力,Theo选择了一个非常规的测试场景——DEF CON黑客大会的Goldbug密码挑战赛。这是一系列结合推理、研究和密码学的复杂谜题,每年有12-13道,答案都是12个字符的海盗主题短语。
Theo花了整整三天才解开其中一道名为"Smuggler's Manifest"的谜题。这道题涉及ADFGX密码——一种诞生于第一次世界大战的加密系统,由德国上校Fritz Nebel于1918年设计。ADFGX密码仅使用A、D、F、G、X五个字母(这五个字母在摩尔斯电码中不易混淆,专为无线电传输设计),结合了波利比奥斯方阵替换和列置换两种加密技术,在当时极难破解——法国密码分析师Georges Painvin最终在1918年6月破解了它,直接影响了战争走向。谜题需要从一份货物清单中找出宝石走私路线,然后用正确的密钥进行解密。
当他把同样的PDF和简要指令交给GPT-5.1 Pro时,模型思考了将近30分钟,然后给出了令人震惊的分析:
- 正确识别了ADFGX密码——没有任何Claude模型能做到这一点,这本身就体现了GPT-5.1 Pro跨越历史密码学与现代推理的知识整合能力
- 发现了电影《绿宝石》的关联——Theo自己是翻遍了整部电影剧本才找到的
- 找到了Theo没发现的关键线索——不同地点的货物重量不平衡,丛林多出2.1单位、港口少了2.1单位,暗示宝石的重量和走私路径
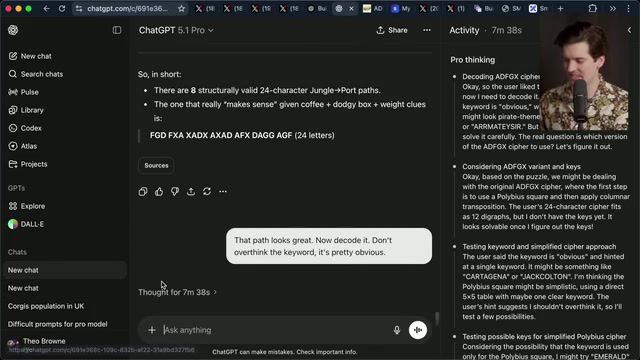
经过几轮提示和约40分钟的总计算时间,模型最终给出了正确答案:"WALLET PICKER"。Theo说他看到这个结果时"感到了一阵寒意"——这种类型的谜题他从未期望LLM能够独立解决。
ChatGPT界面拖后腿:最聪明的大脑困在最糟糕的牢笼
然而,令人沮丧的现实是:GPT-5.1 Pro目前没有API访问权限,只能通过ChatGPT网站使用。而这个网站的体验堪称灾难级别。
Theo在使用过程中遇到了大量UI问题:新对话的标题无法正确更新,停留在"thought-for-7-minutes-38-seconds"的破碎状态;页面频繁报错"Something went wrong";长时间思考后需要记住回来查看结果。
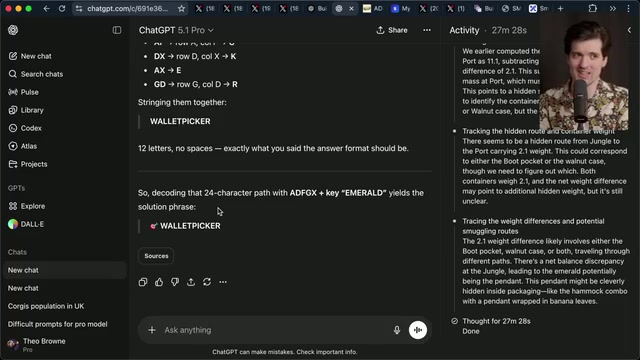
另一位评测者Matt Schumer的总结精准概括了这种矛盾体验:
"GPT-5.1 Pro是一个缓慢的重量级推理模型。面对真正困难的问题时,它感觉比我用过的任何东西都聪明。指令遵循是最突出的优势——它能在30分钟到1小时的运行中始终不偏离指定路径。但它最大的弱点就是界面。它活在ChatGPT里,不在我的IDE里,不接入我现有的工具链。"
对于日常工作,Gemini 3在UI设计和写作方面仍然更好。但对于需要深度思考、规划和研究的任务,尤其是需要一次做对的事情,GPT-5.1 Pro目前无可替代。
GPT-5.1 Codex Max编码能力评测:理想丰满,现实骨感
Codex Max是OpenAI专为代理式编码(Agentic Coding)设计的新模型。所谓代理式编码,是区别于传统"问答式"代码补全的新范式——在代理模式下,AI模型被赋予自主执行多步骤任务的能力,包括读写文件、运行终端命令、搜索文档、迭代调试等,无需人类在每一步介入。Codex Max主打几个核心特性:
Compaction(压缩)技术:当上下文窗口接近极限时,模型会自动压缩历史记录,保留最重要的上下文。这项技术的核心原理是对历史对话进行语义摘要,将冗长的中间步骤压缩为高密度的结构化记忆,同时保留关键决策节点和代码状态——类似于人类在长期项目中维护"工作日志"的方式。OpenAI声称这使模型能在数百万token的范围内保持连贯性,内部测试中甚至能持续工作超过24小时,对于大型代码库重构、跨文件依赖分析等场景具有重要意义。
Token效率提升:在SWE-Bench验证集上,Codex Max的表现优于原始GPT 5.1 Codex,同时减少了30%的思考token。SWE-Bench是由普林斯顿大学研究团队提出的AI软件工程能力评测黄金标准,它从GitHub真实开源项目中收集了2294个实际issue,要求模型自动生成能通过对应测试用例的代码补丁——这比简单的代码补全难得多,需要模型理解复杂代码库上下文并定位bug根源。更少的token意味着更快的速度——这对于被诟病太慢的OpenAI模型来说至关重要。
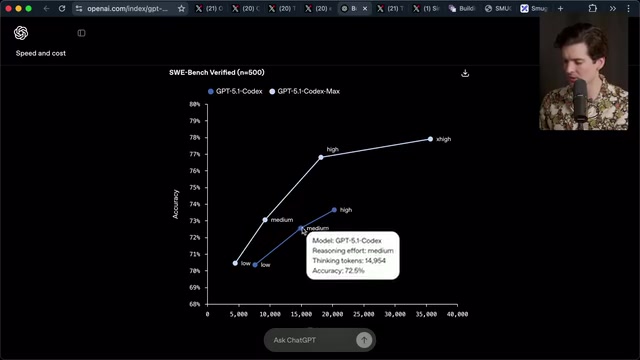
然而,Theo的实际测试体验远没有营销材料描述的那么美好。
AI编程实战翻车:AI SDK升级任务的惨痛经历
Theo用一个标准化的测试任务来评估Codex Max——将项目升级到最新版本的AI SDK。这个任务他已经在多个AI编程模型上测试过,结果差异明显。
第一次尝试就遭遇了灾难性的问题:
- 搜索工具开启时直接报错崩溃
- 关闭搜索后,模型用curl抓取了整个网页的HTML源码塞入上下文,而不是提取有用文本
- 引入了严重的TypeScript类型安全问题,到处使用
as any - 从未主动运行
tsc进行类型检查 - 多次修复尝试后,同样的bug依然存在
这里需要理解as any问题的严重性:TypeScript的核心价值在于静态类型系统,通过在编译阶段捕获类型错误来降低运行时bug。as any是一种类型断言语法,允许绕过类型检查,本质上是在放弃TypeScript的核心保障。tsc --noEmit是官方编译器提供的全量类型检查命令,AI模型不主动运行它,意味着它能让代码"看起来能跑",却悄悄埋下了类型安全的地雷——这是当前AI编程工具的普遍痛点。
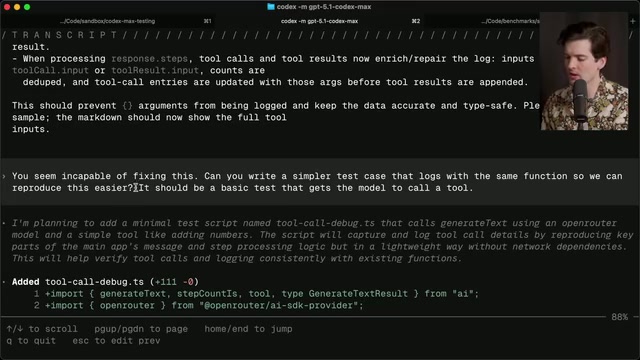
Theo在提示中写道:"你完全毁掉了这个项目的类型安全性和可靠性。你到底在干什么?
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。