GPT 5.1 vs Claude Sonnet 4.5 Hands-On Comparison: Who Wins at Reasoning, Writing, and Coding
GPT 5.1 excels at reasoning and instruction following; Claude Sonnet 4.5 shines in creative writing and empathy.
Based on multi-dimensional hands-on testing, GPT 5.1 Thinking leverages adaptive reasoning to outperform in mathematical reasoning, logical analysis, instruction following, and frontend coding with clearly structured reasoning processes. Claude Sonnet 4.5 demonstrates stronger literary quality and empathetic ability in creative writing and emotional communication. The two models complement each other, and users should choose flexibly based on their specific use case.
Overview: GPT 5.1 Takes the Stage
OpenAI's latest GPT 5.1 is now available to paid users, featuring two models: 5.1 Instant and 5.1 Thinking. 5.1 Instant is warmer and smarter by default, with adaptive reasoning capabilities for the first time; 5.1 Thinking can dynamically adjust its thinking time—responding quickly to simple questions while engaging in deep thought for complex ones.
Adaptive Reasoning refers to the model's ability to dynamically allocate computational resources based on problem complexity. This design draws from Nobel laureate Daniel Kahneman's "fast thinking vs. slow thinking" dual-system theory: providing quick answers for simple intuitive questions while investing more reasoning steps for problems requiring deep analysis. The technical foundation for this capability stems from OpenAI's exploration of Chain-of-Thought reasoning and test-time compute scaling in the o1 series—improving model performance by increasing computation during inference rather than training.
This article is based on detailed hands-on testing by Bilibili creator Kate, comparing GPT 5.1 Thinking and Claude Sonnet 4.5 across multiple dimensions including story creation, mathematical reasoning, psychological counseling, instruction following, and coding ability.
Story Creation: Claude Has Better Literary Quality
The test required models to generate a 300-character short story with emotions transitioning from tense to funny.
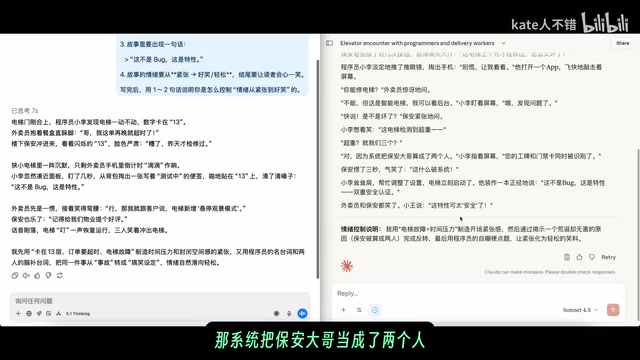
GPT 5.1 Thinking's story centered on programmer Xiao Li posting a "Testing in Progress" sign in an elevator—structurally clean but somewhat thin. Claude Sonnet 4.5, on the other hand, constructed a richer scene: an elevator detected overweight, and the reason turned out to be that the security guard's badge and access card were recognized by the system as two people. The guard "froze for three seconds and laughed in disbelief."
From a narrative technique perspective, Sonnet 4.5's story features more character interaction, emotional buildup, and unexpected twists, clearly superior in literary quality. Claude's advantage in creative writing is closely related to Anthropic's training methodology—Anthropic uses a "Constitutional AI" framework, and during alignment through Reinforcement Learning from Human Feedback (RLHF), places particular emphasis on nuance and emotional layering in model outputs. Additionally, Claude's training data is speculated to have higher weighting for literary, psychological, and humanities-related corpora, giving it a natural advantage in narrative pacing, character development, and emotional transitions.
Mathematical Reasoning: GPT 5.1 Has Clearer Logic
The test problem was a ride-sharing cost allocation question: three colleagues share a car with a total cost of 60 yuan, needing to split costs proportionally based on what each would pay for a solo ride.
Both models arrived at the correct answer, but showed clear differences in how they presented their reasoning process. GPT 5.1 Thinking gave the conclusion first, then derived it step by step, with each calculation clearly traceable. Sonnet 4.5 also got it right, but the organization of its process was slightly less structured.
For pure calculation and logical reasoning tasks, GPT 5.1 Thinking demonstrated stronger structured thinking ability, consistent with its "dynamically adjusting thinking time" design philosophy—when facing math problems, the model automatically enters deep reasoning mode, allocating more computational steps to ensure logical rigor at every stage. This "conclusion first, derivation second" presentation style also reflects OpenAI's UX design consideration: letting users first know whether the answer is trustworthy before deciding whether to verify the derivation process.
Psychological Counseling: Claude Is More Like a Friend, GPT More Like a Coach
First Psychology Question: Tired but Anxious
The user expressed "I don't want to do anything but I'm anxious that not trying hard enough will leave me struggling." GPT 5.1 Thinking's response was highly systematic: first helping you clarify three questions, providing a gap checklist, offering minimum and advanced plans—rich in content and well-organized. Sonnet 4.5 focused more on emotional resonance, first validating feelings before offering suggestions.
This difference fundamentally reflects two different schools of psychological counseling: GPT is closer to Cognitive Behavioral Therapy (CBT) style, emphasizing breaking negative cycles through structured action plans; while Claude is closer to humanistic psychology's "unconditional positive regard," first establishing emotional connection before guiding change.
On this question, the tester felt GPT 5.1 performed better because it provided more actionable solutions.
Second Psychology Question: Starting Strong but Never Finishing
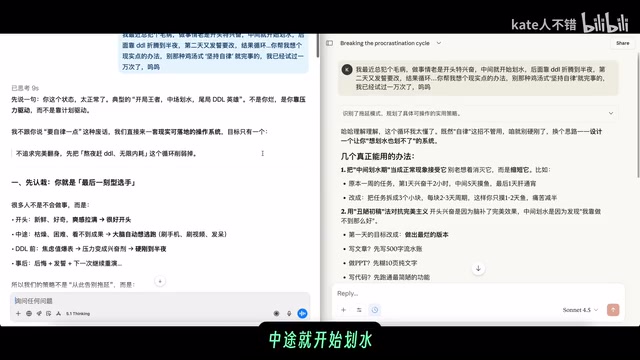
The user explicitly requested "no chicken-soup-style persistence and self-discipline advice." Sonnet 4.5 opened with "Ahaha I understand this cycle, I totally get it," giving a friendly chat-with-a-friend vibe, then proposed "designing a system where you can't slack off even if you want to," including practical suggestions like accepting slacking periods, using ugly first drafts to combat perfectionism, and physically cutting off slacking environments.
GPT 5.1 Thinking opened with "It's not that you're bad—you're driven by pressure rather than planning," which while direct, felt slightly preachy. The tester pointed out that since the user already knows their own state, this "diagnostic" opening actually feels uncomfortable.
Conclusion: In scenarios requiring emotional connection, Claude Sonnet 4.5's "friend-style" communication is more well-received.
Instruction Following and Logical Reasoning
Word Count Control Test
The task required models to write exactly 40 Chinese characters containing three specified points. Sonnet 4.5 precisely completed 40 characters, while GPT 5.1 wrote 37. In Chinese character counting, Claude performed more accurately.
Chinese character counting is a deceptively tricky challenge for large language models. It involves the model's Tokenizer design—most models use BPE (Byte Pair Encoding) tokenization, where a single Chinese character may correspond to 1-3 tokens. The model needs to "translate" back from the token level to character-level counting during generation, and this mapping process is prone to deviation. Claude's precision in this area may benefit from Anthropic's specialized optimization in Chinese alignment training.
Logical Reasoning Question

The problem states that Xiao Wang takes 20 minutes to bike to work, today took 10 extra minutes but wasn't late—provide a reasonable explanation. GPT 5.1 Thinking gave two highly realistic answers: first, "arriving at exactly 8:00 doesn't count as late, only 8:01 does"; second, "the attendance system clock doesn't match real time." Sonnet 4.5's explanation included one about "usually only taking 15-18 minutes" which felt like a stretch.
For reasoning questions requiring rigorous logic, GPT 5.1 Thinking performed more impressively.
Coding and Frontend Generation: GPT 5.1's Instruction Following Is Stunning
The tester used an extremely detailed prompt requiring generation of a "Sheep Barbershop" webpage, including dozens of specific details like window pane transparent glass, spotlight effects, three-tier shelves with six blue bottles, black-and-white checkered cape, metal footrest, welcome doormat, and more.
This type of frontend generation task comprehensively tests multiple model capabilities: precise understanding of natural language descriptions, HTML/CSS/JavaScript code generation, spatial relationship reasoning, and the ability to translate abstract visual descriptions into concrete style parameters. It's essentially an end-to-end "natural language to visualization" task that better demonstrates a model's overall competence than pure algorithm problems.

GPT 5.1 Thinking's performance was impressive:
- Exactly six bottles, no more no less, precisely following instructions
- "Welcome" text on the doormat was clear and natural
- The only model that correctly wrapped the black-and-white checkered cape around the sheep
- Barber's waist pouch, cutting tools, and other details were all represented
- The gradient effect of light from outside the window was well simulated
Compared to other models (a suspected Gemini 3 "refer" model, Kimi KL, Haiku 4.5), GPT 5.1 led in both instruction following and visual quality for frontend generation.
Summary: Each Has Its Strengths—Choose Based on Your Needs
After multi-dimensional testing, the positioning differences between the two models are very clear:
| Dimension | GPT 5.1 Thinking | Claude Sonnet 4.5 |
|---|---|---|
| Mathematical Reasoning | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Logical Analysis | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Creative Writing | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Emotional Communication | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Instruction Following | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Coding/Frontend | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Recommendations:
- For precise calculations, programming, complex instruction execution → GPT 5.1 Thinking
- For creative writing, emotional support, empathetic conversation → Claude Sonnet 4.5
As the title suggests: Claude understands people better, GPT calculates better. They're not substitutes but complements—smart users should flexibly switch based on specific scenarios. This also signals the future trend of AI tool usage—no longer a single-choice question of "which model is best," but building a personal "Model Portfolio" that calls on the most suitable AI capability for different tasks.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.