GPT 5.5 vs DeepSeek V4 实测对比:逻辑推理、前端生成、3D场景谁更强?

GPT 5.5与DeepSeek V4三维度实测对比,各有优劣,混合使用最佳。
本文通过逻辑推理、前端页面生成和3D场景动画三个维度实测对比GPT 5.5与DeepSeek V4。结果显示:DeepSeek V4在逻辑陷阱题识别、功能完整性和迭代修正效率上更优,且性价比极高;GPT 5.5在视觉表现力和生成速度上占优,复杂推理场景更稳健。作者建议混合使用两者以实现最佳效果和成本控制。
当 DeepSeek V4 携百万上下文和极致性价比杀入市场,与 OpenAI 旗舰模型 GPT 5.5 正面交锋时,谁才是真正的实战王者?本文通过逻辑推理、前端页面生成、3D 场景动画三个维度的实际任务测试,带你看清 GPT 5.5 和 DeepSeek V4 的真实表现差异。
GPT 5.5 与 DeepSeek V4 基础参数对比
在进入实测之前,有必要先厘清两位选手的基本面。
DeepSeek V4 目前分为 V4 Pro 和 V4 Flash 两个版本,最引人注目的是它已经将上下文窗口拉到了百万级别(1M),同时接口兼容 OpenAI 和 Anthropic 的调用方式,迁移成本极低。GPT 5.5 则延续了 OpenAI 旗舰模型线的定位,主打复杂推理和代码能力,优势在于成熟的生态工具链和稳定的通用任务表现。
所谓上下文窗口(Context Window),是指大语言模型在一次对话中能够"看到"和处理的最大文本长度,通常以 Token 为单位衡量——1 个 Token 大约对应英文中的 0.75 个单词或中文中的 0.5 到 1 个汉字。百万级上下文(1M Token)意味着模型可以一次性处理约 75 万个英文单词或数十万汉字的内容,相当于一次性阅读十几本完整的书籍。这对于长文档分析、大型代码库理解、多轮复杂对话等场景具有革命性意义。此前主流模型的上下文窗口多在 128K-200K 之间,百万级的突破使得"全量输入、无需分段"成为可能,大幅降低了信息丢失和上下文断裂的风险。

价格与输出上限差异显著
两边虽然都来到了百万级上下文,但在输出上限和价格上差异明显:
- 最大输出:DeepSeek V4 可达 384K,GPT 5.5 为 128K。对于长报告或大规模代码生成场景,这个差距非常直接。
- 价格:DeepSeek 的输入和输出价格都明显更低,Flash 和 Pro 两个版本能覆盖不同成本需求;GPT 5.5 的单价更高,高频调用或批量生成时成本差距会被迅速放大。
简单来说,DeepSeek V4 是"高性价比长上下文选手",GPT 5.5 是"复杂任务稳健选手"。
Benchmark 跑分参考:GPT 5.5 与 DeepSeek V4 各有所长
需要强调的是,Benchmark 只能作为参考,真正好不好用还得看具体任务。但从公开指标来看,两者的优势领域确实有明显分化:
- DeepSeek V4 Pro 在 Codeforces、Aero 以及 MRCR 1M 长上下文检索上表现更突出,说明它在竞赛级代码生成和超长上下文检索方面有优势。
- GPT 5.5 在 Humanities Last Exam 和 GPQA Diamond 上得分更高,即在综合逻辑推理和研究级科学问答这类复杂问题上仍然更强。
这里有必要解释一下这些 Benchmark 各自衡量的能力维度。Codeforces 是全球知名的编程竞赛平台,以其为基准的评测衡量模型解决算法竞赛题的能力;GPQA Diamond(Graduate-Level Google-Proof Q&A)是一组由领域专家编写的研究生级别科学问答题,即使使用搜索引擎也难以直接找到答案,专门用于衡量模型的深层知识推理能力;MRCR 1M(Multi-Round Co-reference Resolution)则测试模型在超长上下文中追踪和解析指代关系的能力;Humanities Last Exam 是一项综合人文学科考试,涵盖哲学、历史、文学等多个领域的高难度问题。这些指标从不同维度刻画了模型的能力边界,单看任何一项都不足以下结论。

这些数据给出了一个清晰的预期框架,但真正的胜负还要在实战中见分晓。
实测一:逻辑推理能力——经典陷阱题谁能识破?
第一个测试是一道精心设计的逻辑推理题:将一个经典有解的逻辑问题改版为无解的情况,故意挖坑。
GPT 5.5 的表现:思考速度很快,几乎立刻给出了结果——但正中下怀,输出了一个错误的解法。它没有识别出题目已经被改为无解,而是套用了经典解题模板,"自信地"给出了答案。
DeepSeek V4 的表现:经过了明显更长时间的深度思考,最终正确识别出这道题无解,并给出了合理的推理过程。
这个结果颇有意味:GPT 5.5 在没有明确指令提示"可能无解"的前提下,倾向于快速给出答案,存在"思考偷懒"的问题;而 DeepSeek V4 的深度思考机制虽然更慢,但在这类陷阱题上反而更可靠。这种现象在 AI 研究中被称为"模式匹配陷阱"——模型在训练数据中见过大量类似的经典题型及其标准解法,当遇到表面相似但本质不同的变体时,容易直接套用已有模式而跳过深层验证。DeepSeek V4 能够避开这一陷阱,说明其推理链路中可能包含了更强的自我校验机制。
实测二:前端页面生成——Shader 着色器与交互效果
第二个任务是让两个模型运用着色器(Shader)制作一个"有活人感"的网页,要求包含动画效果、鼠标交互响应以及隐藏彩蛋。
着色器(Shader)是运行在 GPU 上的小型程序,最初用于 3D 图形渲染中的光照和颜色计算,后来被广泛应用于网页视觉效果中。在前端开发领域,WebGL 和 GLSL(OpenGL Shading Language)让开发者可以直接在浏览器中编写着色器代码,实现粒子系统、流体模拟、光线追踪等复杂视觉效果。着色器分为顶点着色器(Vertex Shader,处理几何形状)和片段着色器(Fragment Shader,处理像素颜色)两种。让 AI 模型生成 Shader 代码是一项高难度任务,因为它不仅需要理解编程逻辑,还需要具备数学(向量运算、矩阵变换)和视觉美学的综合能力。
DeepSeek V4 生成效果:马赛克律动
DeepSeek 生成的网页采用了马赛克风格的动画效果,能够响应鼠标滑动,文字也有律动变化,整体风格独特。彩蛋功能也按要求正确实现,一次生成的完成度相当高。
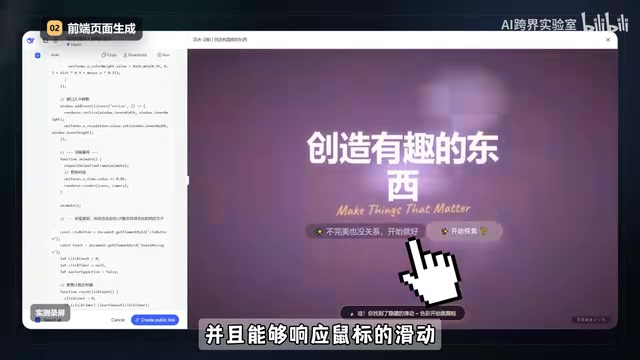
GPT 5.5 生成效果:烟雾绚丽
GPT 这边生成的是类似烟雾的效果,视觉感官上更加绚丽。烟雾的运动和对鼠标滑动的响应比较自然,"Live"手写体和抖动效果也给网页增添了生气。不过有一个小遗憾——虽然按要求设置了彩蛋触发,但彩蛋的实际效果没有做出来。
本轮判定:GPT 5.5 在视觉表现力上更胜一筹,但 DeepSeek V4 的一次生成完成度和功能完整性同样令人惊艳。如果追求视觉效果选 GPT 5.5,追求功能完整性则 DeepSeek V4 更稳。
实测三:3D 场景动画生成——飞机飞越城市
最后一个任务是生成一个"飞机飞过城市上空"的 3D 模拟场景,这对模型的空间理解和代码生成能力都是不小的考验。
初版生成结果:两个模型都翻车了
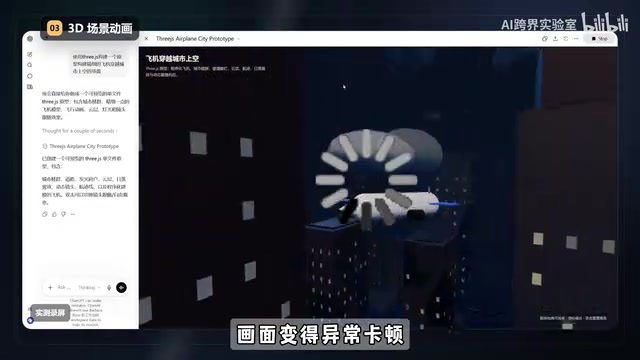
GPT 5.5:生成速度更快,但结果问题不少——飞机的机翼被放置到了同侧,而且是在倒退飞行。画面异常卡顿,出现了穿模(穿透建筑物)的情况,黑暗的天空也与左上角的日落效果矛盾。
穿模(Clipping/Collision Penetration)是 3D 图形和游戏开发中的常见问题,指的是两个 3D 物体在渲染时相互穿透,违反了物理世界中物体不能占据同一空间的基本规则。在专业的 3D 引擎中,通常通过碰撞检测(Collision Detection)算法来避免这一问题,常用的方法包括 AABB 包围盒检测、射线检测和物理引擎模拟等。当 AI 模型生成 3D 场景代码时,如果没有正确设置碰撞边界或飞行路径规划,就容易出现飞机穿过建筑物这样的穿模现象,这也反映出 AI 在空间推理和物理规则理解方面仍存在不足。
DeepSeek V4:正确生成了飞机、城市建筑、云朵和蓝天,但飞机的飞行姿态不对,且飞行速度过快。
迭代修正对比:DeepSeek V4 修正效率更高
在对两边的问题分别提出修正需求后,差异就出来了:
- DeepSeek V4 在收到问题反馈后直接进行了针对性修正,一轮就解决了问题。
- GPT 5.5 则绕了一些圈子,经过了多轮修改才达到预期效果。
本轮 DeepSeek V4 的表现更好,不仅初版的基础完成度更高,迭代修正的效率也更胜一筹。
总结:GPT 5.5 和 DeepSeek V4 怎么选?
经过三轮实测,两个模型的特点已经非常清晰:
| 维度 | GPT 5.5 | DeepSeek V4 |
|---|---|---|
| 生成速度 | 更快 | 稍慢 |
| 逻辑推理(陷阱题) | 容易"偷懒"出错 | 深度思考更可靠 |
| 前端视觉效果 | 更绚丽 | 功能完整性更好 |
| 3D 场景生成 | 初版问题多,迭代慢 | 初版基础好,修正快 |
| 价格 | 较高 | 极具性价比 |
推荐使用策略:混合搭配效果最佳
一个务实的方案是混合使用:先用 GPT 5.5 进行调研和规划(利用其在复杂推理上的优势),再用 DeepSeek V4 进行具体实现(利用其性价比和长上下文优势),以最大程度节省 Token 开支。
这种混合使用策略在业界被称为模型路由(Model Routing),已经成为大模型应用的最佳实践。其背后的核心逻辑是 Token 经济学——每次 API 调用的费用由输入 Token 数和输出 Token 数共同决定,不同模型的单价差异可达数倍甚至数十倍。在实际生产环境中,一个复杂项目可能涉及数百次 API 调用,累计消耗数百万 Token,此时价格差异会直接影响项目的经济可行性。一些开源框架如 LiteLLM 和 OpenRouter 已经提供了多模型路由的基础设施支持,开发者可以根据任务复杂度自动分配最合适的模型。
日常编程任务 DeepSeek V4 已经完全能够胜任,在某些方面甚至超越 GPT 5.5。但在真正复杂的推理和科学问答场景中,GPT 5.5 仍然是更稳健的选择。最终的赢家,或许不是某一个模型,而是懂得根据任务特点灵活切换的使用者。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。