GPT-5.5在Databricks文档解析中错误率降低46%:实测数据与架构解析

GPT-5.5在企业文档处理中错误率降低46%,数字解析实现质的突破
Databricks公开GPT-5.5在Codex平台的实测数据:在Agent Harness框架下,GPT-5.5相比GPT-5.4错误率降低46%,是唯一突破50%准确率的模型。其核心突破在于数字解析精度的阶梯式飞跃,解决了小数点偏移、千分位误读等问题。Databricks将通过AgentBricks和AgentSupervisor API让GPT-5.5担任多智能体架构中的监督者角色,推动企业文档处理自动化。
GPT-5.5实测表现:错误率降低46%意味着什么
Databricks近日公开了GPT-5.5在其Codex平台中的实际应用数据。在Agent Harness(智能体框架)设置下,GPT-5.5相比GPT-5.4实现了46%的错误率降低,并且是唯一一个在该基准测试中突破50%准确率的模型。
这不是实验室里的理论数字——它来自真实的企业文档处理场景,标志着大语言模型在这类任务上跨过了一个关键的能力门槛。
值得注意的是,Agent Harness是一种用于评估和运行AI智能体的测试框架,它模拟真实的多步骤任务执行环境。与传统的单次问答评估不同,Agent Harness要求模型在连续的决策链中保持一致性——每一步的错误都会向后传播并放大。这也是为什么46%的错误率降低在这个设置下意义格外重大:在多步骤任务中,错误率的复合效应意味着最终准确率的提升远超线性比例。
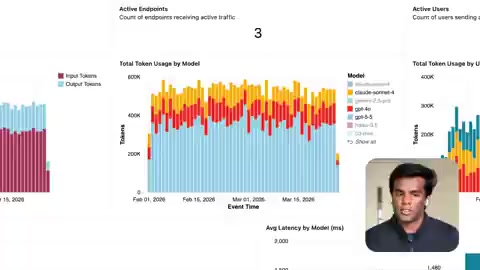
企业文档解析的核心难题
Databricks的客户日常面对的文档远比想象中复杂:不规则表格、混合格式数字、嵌套层级结构、扫描件中的模糊字符……这些都是传统解析方案的噩梦。

为了衡量模型在这些真实场景中的表现,Databricks采用Office QA作为代理基准测试。Office QA是专门针对办公文档理解设计的基准测试集,涵盖Word、Excel、PDF等格式中的信息抽取、表格推理和跨文档问答任务。与通用NLP基准(如MMLU、HellaSwag)相比,Office QA更贴近企业真实工作负载,因为它要求模型同时处理结构化数据(表格)和非结构化文本,并在两者之间建立语义关联。这个基准直接对标客户的实际工作流——从复杂PDF中提取关键数据、解析非标准化表格、处理多语言混排文档等。Databricks选择这一基准作为代理指标,体现了企业AI评估正在从"学术表现"向"业务可用性"转型的行业趋势。Databricks在Agent Harness中结合自定义解析能力和多智能体架构来执行这些任务。
数字解析精度:从5.4到5.5的质变
GPT-5.4与GPT-5.5之间最关键的差异在于数字解析质量。
早期模型(包括5.4及更早版本)在提取文档中的数字时频繁出错——小数点位置偏移、千分位分隔符误读、负号遗漏等问题屡见不鲜。对于金融报表、审计文件、医疗数据表格来说,一个数字的错误可能导致整个分析链条崩溃。
GPT-5.5在这方面展现出了"阶梯函数式"的能力跃升:不是渐进式的小幅改善,而是在数字精确提取上实现了质的突破。这种现象与大语言模型研究中记录的"能力涌现"(Emergent Abilities)高度吻合——Google Brain团队在2022年的研究中系统发现,某些能力并不随模型规模线性增长,而是在跨越特定参数量或训练量阈值后突然出现。这种非线性进步模式对企业采购决策有重要启示:版本号相邻的模型之间,实际能力差距可能远超预期,在特定任务维度上甚至是质的区别而非量的差异。

搭载GPT-5.5的Codex目前在所有智能体和模型组合中达到了最先进水平(state-of-the-art),这是一次能力边界的实质性拓展。
产品落地:AgentBricks与AgentSupervisor API
Databricks预计将有大量客户通过AgentBricks和AgentSupervisor API来构建自定义智能体工作流。在这些工作流中,GPT-5.5扮演"监督者"(Supervisor)角色,负责协调多个子智能体的协作。
多智能体架构(Multi-Agent Architecture)中的"监督者-执行者"模式借鉴了软件工程中的微服务设计思想。监督者负责任务规划、资源调度和结果验证,而专用子智能体则各司其职处理特定类型的子任务——例如OCR专用智能体、表格解析智能体、数字校验智能体等。这种分工使得整体系统的鲁棒性远高于单一大模型直接处理所有任务。监督者模型的能力上限直接决定了整个系统的天花板:它需要具备足够强的上下文理解能力,才能准确判断子任务的完成质量并做出正确的纠错决策。
这种架构设计赋予了GPT-5.5更高层次的职责:
- 任务理解与分解:把握文档处理的全局目标,将复杂任务拆分为可执行的子任务
- 子智能体调度:根据任务类型分配给最合适的专用智能体
- 结果验证与纠错:对子智能体的输出进行质量把关,发现并修正错误
GPT-5.5在数字精确度上的提升,恰好强化了其作为监督者进行结果验证的核心能力。在知识密集型任务中,监督能力的提升直接解锁了新一级别的整体性能。
这一突破对企业意味着什么
从Databricks的案例中,可以看到几个值得关注的趋势:
模型能力呈阶梯式进步。 从5.4到5.5并非线性提升,而是在特定维度出现了质变。这符合大模型scaling的典型特征——能力积累到一定程度后突然涌现。
多智能体架构正在成为企业AI的标准范式。 单一模型调用已经无法应对复杂业务场景,"强力监督模型+多个专用子智能体"的组合架构正在被越来越多企业采纳。
评估方式向业务结果靠拢。 Databricks用Office QA对标客户真实工作流,这种以业务产出为导向的评估比通用基准测试更能反映模型的实际价值。
对于金融、法律、医疗等对数字精确度要求极高的行业,GPT-5.5的突破意味着此前需要大量人工校验的文档处理流程有望进一步自动化——不是替代人类,而是将人力从重复性校验中释放出来,投入到更高价值的判断工作中。
核心要点
- GPT-5.5在Agent Harness设置下相比GPT-5.4实现46%的错误率降低,是唯一突破50%准确率的模型
- GPT-5.5在数字解析质量上实现阶梯式飞跃,解决了早期模型无法正确解析所有数字的问题
- 搭载GPT-5.5的Codex在所有智能体和模型中达到当前最先进水平
- Databricks将通过AgentBricks和AgentSupervisor API让客户构建以GPT-5.5为监督者的自定义智能体工作流
- 多智能体架构配合强力监督模型正在成为企业级复杂文档处理的主流范式
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。