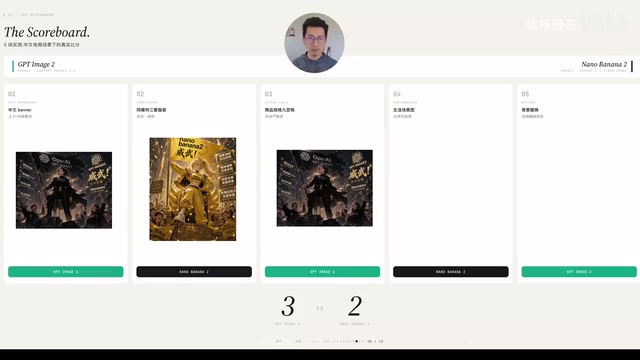
GPT Image 2 vs Nano Banana 2:电商生图实测对比,5大场景谁更强?
GPT Image 2与Nano Banana 2在中文电商生图场景中各有优劣
本文通过五个典型电商场景实测对比GPT Image 2和Nano Banana 2。结果显示GPT Image 2在中文文字渲染、一致性保持和避免幻觉编造方面明显占优,适合食品、母婴等对标签信息敏感的品类;Nano Banana 2则在人像质感和生活场景自然度上略胜,适合服装、家居等注重氛围感的品类。实际项目建议根据品类特点选模型,并采用模块化工作流提升可控性。
最近 OpenAI 发布了 GPT Image 2,不少人认为它在生图能力上大幅超越了此前的标杆模型。但在中文电商这个特殊场景下,它的表现究竟如何?
本文基于五个典型电商生图场景的实测,对 GPT Image 2 和 Nano Banana 2 进行了详细对比。结果出乎意料——两者各有胜场,选择哪个完全取决于你的具体需求。
模型基础参数对比
在正式测评之前,先了解两个模型的关键参数差异。
出图速度方面,Nano Banana 2 官方标称 3-5 秒,实测略长但仍明显快于 GPT Image 2。GPT Image 2 作为 Thinking Mode 的一个分支,带上推理过程后速度不可避免地慢下来。所谓 Thinking Mode(思维模式),是 OpenAI 在 o1、o3 等推理模型中引入的一种技术范式——与传统的前馈式生成不同,Thinking Mode 会在输出结果之前进行多步内部推理,模型会先"思考"图像的构图、元素关系、文字布局等,再进行像素级渲染。这种机制的优势在于能更好地理解复杂指令和保持语义一致性,但代价是显著增加了推理时间和计算资源消耗。这也解释了为什么 GPT Image 2 在文字渲染准确性上表现更好——它实际上在生成图像之前就对文字内容进行了逻辑校验。
分辨率与参考图方面,两者都支持最高 4K 输出。参考图数量上 Image 2 支持最多 16 张,Nano Banana 2 为 14 张,差距不大。价格上 Nano Banana 2 为 $0.067/千张,Image 2 为 $0.04/千张,后者更具性价比。
生态集成方面,Nano Banana 2 发布较早,已在 Vertex、PS、Canva、Figma 等平台完成集成;GPT Image 2 刚发布不久,主要集成在 GPT、Codex 及 API 等 OpenAI 自有生态中。这种生态差异对电商团队的实际影响很大:如果团队已经建立了基于 Canva 或 Photoshop 的设计工作流,Nano Banana 2 的集成优势会显著降低迁移成本——设计师可以在熟悉的工具中直接调用模型能力,无需切换环境。而如果团队更倾向于通过 API 构建自动化生图流水线,GPT Image 2 依托的 OpenAI API 生态则提供了更统一的开发体验。其中 Vertex AI 是谷歌面向企业的 AI 平台,支持模型部署、批量推理和工作流编排,对于需要大规模批量出图的电商场景尤为重要。
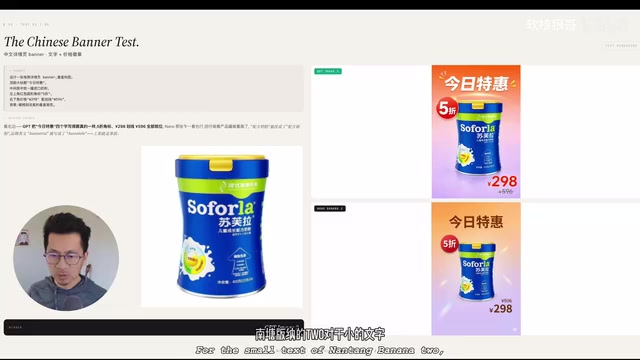
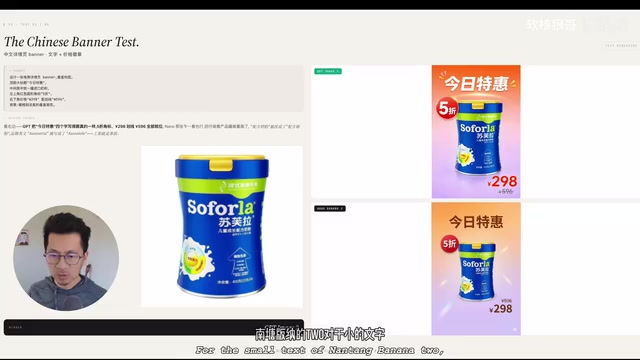
测试一:电商海报图生成
第一个测试场景是生成一张相对简单的电商海报图,我们提供了一张分辨率较低的产品图作为参考。
从结果来看,两个模型对大号文字的渲染都没有太大问题,产品图的外形、图标、图案等基本元素也都能保持原样。但关键差异出现在小文字的渲染上——Nano Banana 2 对小字的处理存在明显问题,整体表现不如 GPT Image 2。
AI 图像生成模型在处理中文文字时面临的挑战远大于英文。中文是一种表意文字系统,每个汉字由多个笔画组成,结构复杂且变化多样。模型需要在像素层面精确还原每一个笔画的位置、粗细和连接关系,而不仅仅是识别字母的线性排列。此外,中文字体在小尺寸下的可辨识性要求更高——一个笔画的偏差就可能让一个字变成完全不同的含义。目前主流的图像生成模型在训练数据中英文文本的占比远高于中文,这导致中文渲染能力普遍偏弱。GPT Image 2 在这方面的突破,很可能得益于训练数据中大量中文场景样本的加入,以及 Thinking Mode 对文字内容的预校验机制。
从海报整体风格来看,GPT Image 2 生成的效果更符合农业电商的视觉调性,色调和排版都更贴合实际使用需求。这一轮 GPT Image 2 完胜。
测试二:模特角色一致性
电商场景中经常需要同一位模特出现在不同图片中,角色一致性至关重要。
角色一致性(Character Consistency)是 AI 图像生成领域的核心难题之一,学术界通常称之为 Identity Preservation 或 Subject Consistency。其技术挑战在于:模型需要在不同姿态、光照、背景和服装条件下,保持同一人物的面部特征(如五官比例、肤色、脸型)不变。早期的解决方案依赖 LoRA(Low-Rank Adaptation,低秩适配)微调或 DreamBooth 等个性化训练技术,需要用户提供多张参考照片对模型进行专门微调。而 GPT Image 2 和 Nano Banana 2 等新一代模型则试图通过 zero-shot 或 few-shot 的方式实现角色一致性——即仅凭少量参考图就能在全新场景中复现同一角色,这对模型的面部特征编码能力和跨场景泛化能力提出了极高要求。
测试要求生成一位年轻东方女性在不同场景下的照片。从结果来看,两个模型对人物的诠释都比较到位。经过 AI 分析后认为生成的已经不是同一个人,但从普通消费者的视角来看,差别并不明显。
值得一提的是,GPT Image 2 在生成三合一照片时会提供两个方案供用户选择,而 Nano Banana 2 则没有这种选择机制。不过在角色一致性的整体表现上,Nano Banana 2 略胜一筹。
测试三:九宫格产品展示图
九宫格图是电商详情页的标配,也是产品一致性保持中最容易翻车的场景。
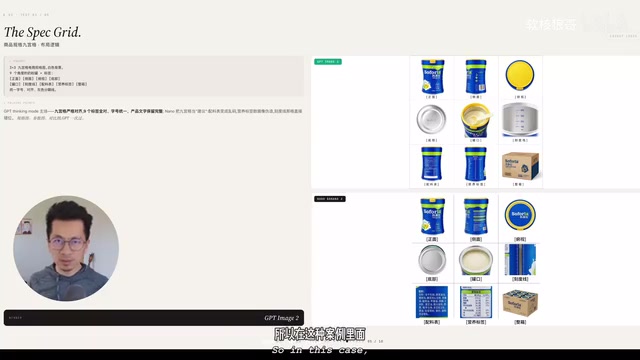
这个测试暴露了 Nano Banana 2 的一个严重问题:过度联想。它自行脑补了配方表、营养标签等我们并未提供的内容,并编造了大量虚假文字。对于奶粉这类对配料和营养成分极其敏感的产品,这种"活编乱造"是绝对不可接受的。
这种"过度联想"本质上是 AI 领域广泛存在的幻觉(Hallucination)现象在图像生成中的体现。在大语言模型中,幻觉表现为编造不存在的事实;在图像生成模型中,则表现为凭空添加参考图中不存在的视觉元素。其根源在于生成模型的训练机制——模型通过学习海量数据中的统计规律来"补全"信息,当输入信息不足时(如仅提供一张低分辨率图片),模型会基于训练数据中的先验知识进行推断填充。对于奶粉、药品、保健品等受严格监管的品类,AI 编造的配料表或营养标签可能直接违反《广告法》和《食品安全法》的相关规定,带来严重的法律合规风险。
当然,这个测试对 AI 模型来说确实有些勉为其难——仅凭一张低分辨率产品图就要生成多角度的九宫格展示,不进行联想几乎不可能。实际操作中,建议提供更丰富的提示词和多角度产品图,或者采用单独生成再后期合成的方式,效果会更可靠。
这一轮 GPT Image 2 胜出,主要因为 Nano Banana 2 的过度联想带来了不可控风险。
测试四:生活场景控制
这个测试要求模型按照给定的场景布置,将产品图以准确对焦、自然融入的方式展现出来。
从结果来看,Nano Banana 2 生成的场景更贴近真实生活感,但整体色调偏暗。GPT Image 2 则呈现出一种"摆拍"风格,但在光线处理上更为柔和淡雅,对于奶粉这类产品来说可能更合适。
这一轮见仁见智,但从生活场景的自然度来看,Nano Banana 2 略占优势。色调偏暗的问题理论上可以通过优化提示词来改善。
测试五:背景替换与文字一致性(终极测试)
最后一个测试是终极挑战——背景替换后的产品渲染,重点考察文字一致性的保持能力。
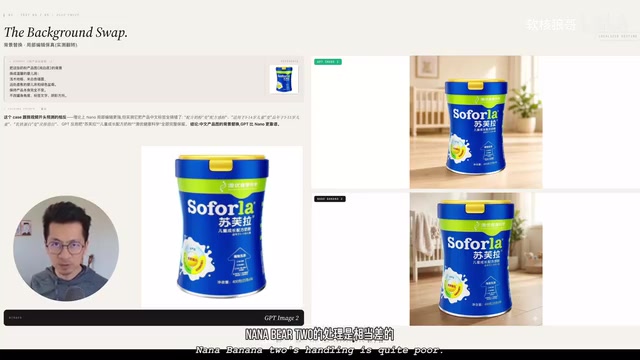
这一轮的结果非常明显,GPT Image 2 完胜。具体表现在:
- 小文字处理:Nano Banana 2 在重新渲染后出现了大量奇怪的"汗渍"般的伪影
- 数字准确性:原文"适用于 3 到 14 岁儿童"被 Nano Banana 2 篡改为"3 到 15 岁儿童",说明模型在猜测而非还原
- 中文渲染:最离谱的是"乳铁蛋白"四个字,GPT Image 2 完美还原,Nano Banana 2 却变成了"灵异之味"这样莫名其妙的内容
这些问题的出现再次印证了中文渲染的技术难度。图像生成模型在处理文字时,本质上是在"画"文字而非"排版"文字——模型并不真正理解字符的语义,而是试图在像素空间中复现训练数据中见过的文字图案。当背景发生变化时,模型需要重新推断文字区域的像素分布,这个过程中极易出现笔画错位、字形变异等问题。GPT Image 2 在这方面的优势,很可能源于其 Thinking Mode 在生成前对文字内容进行了额外的语义理解和校验步骤。
综合评分与选型建议
五轮测试结束,我们可以得出以下结论:
| 测试场景 | 胜出模型 | 关键差异 |
|---|---|---|
| 海报图生成 | GPT Image 2 | 小文字渲染更准确 |
| 角色一致性 | Nano Banana 2 | 人像质感略好 |
| 九宫格展示 | GPT Image 2 | 不会过度联想编造内容 |
| 场景控制 | Nano Banana 2 | 生活场景更自然 |
| 背景替换 | GPT Image 2 | 文字一致性远超对手 |
选型建议
推荐 GPT Image 2 的场景: 如果你的电商图片对中文文字的还原度要求较高(如配料表、功效说明、年龄标注等),GPT Image 2 的成功率明显更高。尤其是涉及食品、保健品、母婴等对标签信息敏感的品类,文字准确性至关重要。
推荐 Nano Banana 2 的场景: 如果你更看重生活场景的自然感和人像处理的质感,Nano Banana 2 在这方面略胜一筹。适合服装、家居、美妆等更注重氛围感的品类。
需要注意的局限性
目前这些多模态模型对大众化产品的处理已经相当不错,但在工业化产品或小众品类上仍然会出现各种问题。实际项目中,往往需要结合不同的算法和工作流来调优,单靠一个模型很难一步到位。
实际工作流建议
文中多次提到的"单独生成再后期合成"策略,实际上是目前电商 AI 生图领域的最佳实践之一。成熟的电商生图工作流通常包含以下环节:首先使用抠图模型(如 Meta 的 SAM 2、RMBG 等)将产品从原始照片中精确分离;然后通过 AI 生成模型创建符合品牌调性的背景场景;接着使用图像合成技术(如 Inpainting 局部重绘、Outpainting 外扩生成)将产品自然融入场景;最后通过超分辨率模型(如 Real-ESRGAN)提升最终输出的清晰度。这种模块化的流水线方式虽然步骤更多,但每个环节都可以独立优化和质检,整体可控性远高于端到端的一键生成方案。
此外,提供高分辨率的参考图、详细的提示词描述、多角度的产品素材,都能显著提升生成效果。AI 生图不是"一键出图"的魔法,而是需要精心设计输入才能获得满意输出的工具。
核心要点
- GPT Image 2 在中文文字渲染和一致性保持方面明显优于 Nano Banana 2,尤其是小文字和背景替换场景
- Nano Banana 2 在人像质感和生活场景自然度上略占优势,适合注重氛围感的电商品类
- Nano Banana 2 存在过度联想(幻觉)问题,会编造虚假的配料表和营养标签信息,对食品、母婴等敏感品类存在法律合规风险
- 两个模型都支持 4K 分辨率输出,但 GPT Image 2 因 Thinking Mode 机制导致出图速度较慢
- 实际电商生图项目中,建议根据品类特点选择模型,并采用模块化工作流(抠图→场景生成→合成→超分)来提升整体可控性和输出质量
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。