Graphiti MCP Server配置教程:让Cursor和Claude Code拥有持久记忆
Graphiti MCP Server通过时序知识图谱为AI编程助手构建持久记忆能力
当前AI编程助手(如Cursor、Claude Code)存在跨会话记忆缺失的痛点。Graphiti MCP Server通过时序感知知识图谱解决这一问题,能持久存储编程偏好、项目架构、Bug修复历史等信息,支持复杂关系推理和时序追踪。相比传统RAG方案,它能表达实体间多跳关系和信息时效性,还支持团队共享知识库,真正实现跨对话的上下文感知与知识积累。
AI编程助手的记忆困境:为什么需要Graphiti
用 Cursor 或 Claude Code 做项目开发时,你大概率遇到过这些烦心事:关闭 IDE 再打开,AI 助手对之前的项目上下文一无所知,不得不重新索引整个项目,白白烧掉大量 token;明明修过的 bug 下次又踩一遍;团队成员之间没法共享技术经验和踩坑记录。
归根结底,当前 AI 编程助手的记忆是短暂且碎片化的。这些工具的记忆机制主要依赖上下文窗口(Context Window)——即模型单次对话能处理的 token 数量上限。Cursor 基于 VS Code 构建,通过索引项目文件生成向量嵌入来提供代码补全和对话能力,但这些索引在会话结束后并不会形成持久化的语义记忆。Claude Code 作为 Anthropic 推出的命令行 AI 编程工具,虽然支持 CLAUDE.md 等项目记忆文件,但本质上仍是静态文本,缺乏结构化的知识管理能力。这意味着 AI 助手每次启动都近似于「失忆」状态,需要重新理解项目全貌。
Cursor 和 Claude Code 自带的记忆功能效果有限,做不到真正的跨对话持久记忆。Graphiti MCP Server 正是为了解决这个核心痛点而生——它通过时序感知知识图谱,为 AI 编程助手搭建了一个真正的「持久记忆大脑」,实现跨会话的上下文感知与知识积累。
Graphiti是什么?时序感知知识图谱的核心优势
与传统RAG方案的本质区别
Graphiti 是一个用于构建和查询时序感知知识图谱的开源框架。和传统的检索增强生成(RAG)方案不同,它能持续将用户交互中的结构化和非结构化数据写入一个连贯、可查询的知识图谱。
所谓时序感知,是指在传统知识图谱的三元组(实体-关系-实体)基础上,为每条边和节点引入了时间戳、有效期等时态属性,能够表达「某个事实在什么时间段内成立」这类动态信息。这对软件开发场景尤为重要——比如一个 API 接口可能在 v1.0 中接受 JSON 格式,在 v2.0 中改为 Protocol Buffers,时序感知图谱能准确记录这种演变过程,而不是简单地用新信息覆盖旧信息。
传统方案(比如 Cursor 的知识库)通常采用文档向量化的方式,信息以非结构化形式存储,查询时主要靠相似度匹配,很难理解复杂的实体关系。具体来说,RAG 的核心流程是将文档切分为文本块、通过嵌入模型转化为高维向量、存入向量数据库,查询时通过余弦相似度等指标检索最相关的文本块。这种方案在处理扁平化的文档检索时表现良好,但存在几个结构性缺陷:无法表达实体间的多跳关系(如「A 依赖 B,B 依赖 C」的传递关系)、难以处理信息的时效性(旧文档和新文档的向量可能同时被检索到)、以及缺乏全局知识结构的理解能力。
Graphiti 采用知识图谱结构,通过显式建模实体和关系,天然支持这些能力,具备以下核心优势:
- 复杂关系推理:通过实体和关系管理,能够进行深层次的关联分析
- 时序感知能力:理解信息的时间关系和发展脉络,清楚什么时候发生了什么
- 完整数据生命周期管理:支持添加、删除、搜索、维护等全套操作
Graphiti MCP Server能记住哪些信息?
通过 MCP(Model Context Protocol)协议集成后,Graphiti 让 AI 编程助手可以自动存储、检索和推理交互中的信息。MCP 是 Anthropic 于 2024 年底推出的开放协议标准,旨在为 AI 模型与外部工具、数据源之间建立统一的通信接口。它采用客户端-服务器架构,定义了工具调用(Tools)、资源访问(Resources)和提示模板(Prompts)三种核心原语。AI 应用作为 MCP 客户端,可以发现并调用 MCP 服务器暴露的各种能力——类似于 Web 领域的 HTTP 协议,通过标准化的接口规范,让不同的 AI 应用能够以统一方式接入各种外部服务。目前 Cursor、Claude Code、Windsurf 等主流 AI 编程工具均已支持 MCP 协议。
具体来说,Graphiti MCP Server 能记住以下信息:
- 编程偏好:你习惯使用的技术栈、代码风格、框架选择
- 项目需求与架构:项目的技术架构、模块依赖关系
- 代码规范:团队约定的编码规范和最佳实践
- Bug修复历史:每个 bug 出现的原因、修复方案和最终结果
- 重构记录:每个模块的重构原因、过程和结果,保留历史决策上下文
更关键的是,它还支持团队共享知识库——可以追踪服务间的依赖变化、API 演进历程,让团队成员共享技术经验和问题解决方案。
实战效果演示:知识图谱驱动的智能开发
跨会话记忆验证
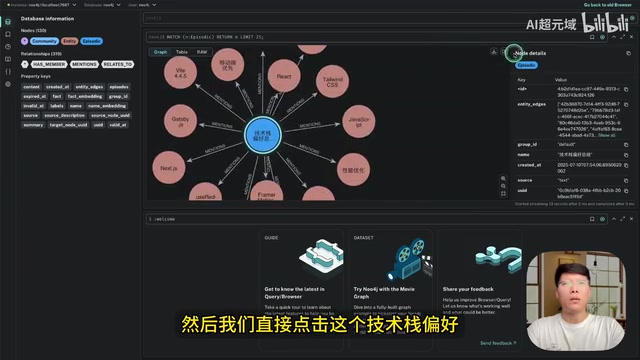
在 Claude Code 中直接提问「我的技术栈和技术偏好是什么」,Graphiti MCP Server 会自动查询知识图谱,返回之前记录的完整技术栈信息——包括 Next.js、Tailwind CSS、React 等偏好设置。这些信息在关闭 IDE 后依然保留,真正做到了跨对话的持久记忆。
在知识图谱的可视化界面中,点击实体节点就能查看详细信息。比如点击「技术栈偏好」节点,能看到关联的所有项目;双击某个 bug 节点,可以查看该 bug 的详细描述和修复方案。
智能Bug修复与自动记录
来看一个实际案例:一个使用 Chakra UI 开发的智能背单词 React 组件中,单词卡片上的文字出现了镜像翻转问题。
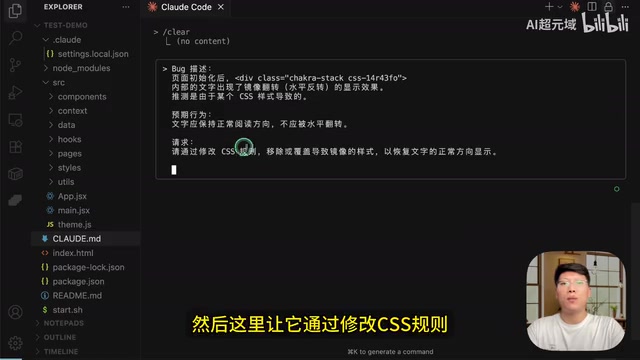
输入提示词描述问题后,Graphiti MCP 的工作流程如下:
- 查询知识图谱:首先检索项目信息和历史中的相似问题
- 定位问题:通过知识图谱中的项目结构信息快速定位到问题所在的 CSS 文件
- 执行修复:修改相关 CSS 规则,恢复文字正常显示
- 自动记录:将修复方案自动存入知识图谱,包括问题原因和解决方案
关闭 Claude Code 后重新打开,输入「你刚才为这个项目修复了什么问题」,系统成功查询到了文字镜像翻转的问题及其解决方案。这就是持久记忆的价值——避免重复踩坑,持续积累项目知识资产。
Graphiti MCP Server完整配置教程:从零开始搭建
下面是 Graphiti MCP Server 的详细安装配置步骤,涵盖 Neo4j 数据库安装、环境变量配置以及在 Cursor 和 Claude Code 中的集成方法。
第一步:安装Neo4j图数据库
Graphiti 底层依赖 Neo4j 图数据库来存储知识图谱数据。Neo4j 是全球最流行的原生图数据库,采用属性图模型(Property Graph Model)存储数据,其中节点和边都可以携带任意数量的键值对属性。与关系型数据库不同,Neo4j 使用「免索引邻接」(Index-free Adjacency)技术——每个节点直接持有指向其相邻节点的物理指针,这使得图遍历操作的时间复杂度与图的总规模无关,仅与遍历的局部子图大小相关。Neo4j 使用 Cypher 查询语言,其语法以 ASCII 艺术风格直观表达图模式匹配,例如 (a)-[:DEPENDS_ON]->(b) 表示节点 a 依赖节点 b。这种数据模型天然适合存储知识图谱中的实体关系网络。
从 Neo4j 官方网站 下载并安装 Desktop 版本,创建实例时需要设置以下参数:
- Instance Name:根据项目需求自定义命名
- User:保持默认即可
- Password:设置一个容易记住的密码(后续配置要用到)
第二步:克隆项目并配置环境变量
# 克隆 Graphiti 项目
git clone <graphiti-repo-url>
# 进入 MCP Server 目录
cd graphiti/mcp_server
# 安装依赖
uv install
# 复制配置文件
cp .env.example .env
# 编辑配置文件
nano .env
这里使用的 uv 是由 Astral 团队(同时也是 Ruff 代码检查工具的开发者)推出的 Python 包管理和项目管理工具,使用 Rust 编写,速度比传统的 pip 快 10-100 倍。uv 整合了虚拟环境管理、依赖解析、包安装、Python 版本管理等功能于一体,类似于 Rust 生态中的 Cargo 或 JavaScript 生态中的 npm。其 uv run 命令会自动处理虚拟环境的创建和激活,大幅简化了项目的环境配置流程。
在 .env 配置文件中需要填写以下关键参数:
- NEO4J_PASSWORD:上一步在 Neo4j 中设置的密码
- OPENAI_API_KEY:OpenAI 的 API Key(默认使用 GPT-4.1-mini 模型)
- 如果没有 OpenAI API Key,也可以配置其他兼容 API,例如将 base URL 指向 DeepSeek 并填写对应的模型名称
配置完成后,启动 MCP Server:
# 以 SSE 方式启动服务
uv run start-sse
第三步:在Cursor中集成Graphiti MCP
Cursor 集成 Graphiti MCP Server 的步骤如下:
- 打开 Cursor 设置 → 工具 → 添加 MCP Server
- 输入 MCP Server 的 SSE 连接地址并保存
- 确认界面显示 Graphiti MCP Server 及其 8 个可用工具
- 在项目规则文件中添加 Graphiti MCP 的使用指令,明确要求 AI 使用知识图谱工具查找偏好、项目设置,并在每次交互后保持知识图谱更新
第四步:在Claude Code中集成Graphiti MCP
# 以 SSE 方式添加 MCP Server
claude mcp add graphiti-sse --transport sse <server-url>
# 验证连接状态
/mcp
这里的 SSE(Server-Sent Events)是一种基于 HTTP 的单向实时通信技术,允许服务器通过持久化的 HTTP 连接向客户端推送事件流。在 MCP 协议中,SSE 是两种主要传输方式之一(另一种是 stdio 标准输入输出)。SSE 方式的优势在于:MCP 服务器作为独立进程运行,可以被多个客户端同时连接,非常适合团队共享场景;同时支持远程部署,服务器不必与 AI 编程工具运行在同一台机器上。相比之下,stdio 方式更适合单用户本地使用场景,由客户端直接启动服务器子进程。
建议同时配置 Claude Code 的 User Memory 文件,写入与 Cursor 规则文件相同的 Graphiti MCP 使用指令。这样可以确保 AI 在每次交互中都会主动调用知识图谱进行查询和更新。
实际开发场景:从零构建项目的完整体验
配置完成后,在 Claude Code 中输入「根据我的技术栈偏好开发一个简单的 Todo List 应用」,AI 会按照以下流程工作:
- 自动调用 Graphiti MCP 查询你的技术栈偏好
- 根据偏好选择对应的框架和工具(如 Next.js + Tailwind CSS)进行开发
- 将项目初始化信息、技术架构等自动记录到知识图谱
- 后续的每次修改(比如调整输入框文字颜色)也会被实时记录
在知识图谱的可视化界面中,可以清晰看到项目节点、技术栈节点、开发者偏好节点之间的关联关系,形成一张完整的项目知识网络。
总结与展望
Graphiti MCP Server 通过时序感知知识图谱,从根本上补齐了 AI 编程助手的记忆短板。它不只是一个简单的记忆存储工具,更是一个能进行关系推理、时序追踪的智能知识管理系统。
对个人开发者来说,它帮你积累编程经验、避免重复踩坑;对团队协作来说,它能共享技术知识、追踪项目演进。随着 MCP 生态的持续完善,「AI + 知识图谱」这种组合模式,很可能成为下一代 AI 辅助开发工具的标配。
如果你正在寻找一种方式让 Cursor 或 Claude Code 真正「记住」你的项目,Graphiti MCP Server 值得一试。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。