Haiku 4.5 vs GPT-5 Mini vs GLM-4.6:低价编程模型实测对比

三款小型AI编程模型实战评测:GPT-5 Mini重安全,Haiku 4.5重速度,GLM-4.6重架构。
KiloCode对Claude Haiku 4.5、GPT-5 Mini和GLM-4.6三款小型编程模型进行了实战评测,要求用TypeScript和SQLite构建任务队列系统。结果显示:GPT-5 Mini具备生产级并发安全能力,总成本最低($0.05);Haiku 4.5速度最快(3分钟),工具调用零失败,但缺乏并发控制;GLM-4.6代码结构最优,但推理模式导致工具调用失效且成本最高。三款模型分别体现了系统工程师、UX设计师和软件架构师的思维模式,适用于不同开发场景。
小型编程模型的实战较量
在AI编程工具日益普及的今天,开发者面临一个现实问题:不是每个项目都需要动用Claude Sonnet 4.5或GPT-5这样的旗舰模型。日常开发中,真正被集成到IDE和命令行里的,往往是那些又快又便宜的"终端编码模型"。
所谓终端编码模型(Terminal Coding Models),是指那些专门为集成到开发者工作流中而优化的轻量级AI模型。与旗舰模型追求极致推理能力不同,这类模型在参数规模、推理延迟和API调用成本之间寻求平衡。它们通常被嵌入到VS Code、Cursor、Windsurf等IDE插件或命令行工具中,承担代码补全、代码生成和重构等高频任务。由于开发者在一天的编码过程中可能触发数百次模型调用,即使单次调用成本微小,累积下来也会形成可观的开支,因此这类模型的性价比成为关键考量因素。
KiloCode近期发布了一篇深度评测,将三款当下最具代表性的小型编程模型——Claude Haiku 4.5、GPT-5 Mini和GLM-4.6——放在同一测试框架下进行对比。测试不是简单的文本生成,而是涵盖了异步逻辑、持久化、并发控制和工具调用等真实编程场景。结果颇具启发性。
测试设计:公平且贴近真实开发
测试方法值得一提。评测团队使用KiloCode的问答模式编写提示词,然后切换到代码模式执行。测试任务是:用TypeScript和SQLite构建一个任务队列系统,支持延迟执行,实现持久化,并展示完整示例。
这个任务设计得很巧妙——它涵盖了异步逻辑、数据持久化和并发控制,而这些恰恰是小型模型最容易翻车的地方。三款模型使用完全相同的提示词,没有针对任何模型做特殊的提示工程优化,都从一个空白项目开始。
KiloCode采用的这种评测方法论代表了AI编程模型评估的一个重要趋势:从静态Benchmark转向动态实战测试。传统的代码生成评测(如HumanEval、MBPP、SWE-bench)通常测试模型在孤立函数级别的代码生成能力,而KiloCode的测试要求模型完成一个涉及多文件、多模块、多技术栈的完整工程任务。这种端到端的评测方式更能反映模型在真实开发场景中的表现,因为实际编程不仅仅是写出正确的函数,还包括项目结构设计、依赖管理、错误处理和运行时行为等多个维度。这也解释了为什么三款模型在传统Benchmark上可能差距不大,但在这次实战测试中却展现出截然不同的工程哲学。
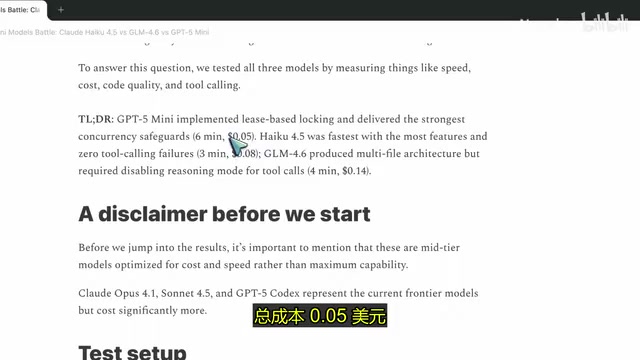
核心结果:速度、成本与质量的三角博弈
三款模型硬指标对比
| 模型 | 耗时 | 总成本 | 核心特点 |
|---|---|---|---|
| GPT-5 Mini | 6分钟 | $0.05 | 并发安全,生产级质量 |
| Haiku 4.5 | 3分钟 | $0.08 | 速度最快,功能最全 |
| GLM-4.6 | 4分钟 | $0.14 | 结构最佳,但稳定性不足 |
一个反直觉的发现是:单位Token价格最低的模型,总成本未必最低。 GLM-4.6虽然账面单价便宜,但因为生成内容过于冗长,推理时消耗了大量Token,最终反而成了三者中最贵的。
这是一个非常实用的洞察——评估AI编程模型成本时,不能只看定价表,还要看"每次运行的实际花费"。在企业级应用中,这种差异会被进一步放大:如果一个团队每天执行数千次模型调用,单次运行成本差异0.09美元就意味着每月数千美元的额外支出。
三款模型拆解:截然不同的工程哲学
GPT-5 Mini:系统工程师思维
GPT-5 Mini是三者中唯一真正理解SQLite并发限制的模型。要理解这一点的重要性,需要了解SQLite的核心架构特征:SQLite是一种嵌入式关系数据库,以轻量、零配置著称,广泛用于移动应用、桌面软件和小型服务。但它采用文件级锁机制,同一时刻只允许一个写操作。当多个进程或线程同时尝试写入时,SQLite会返回SQLITE_BUSY错误。在生产环境中,如果不对并发写入做妥善处理——比如使用WAL(Write-Ahead Logging)模式、事务重试或应用层锁——就会出现数据丢失或程序崩溃。
GPT-5 Mini通过基于租约(Lease)的锁系统规避了这一并发问题。租约锁是分布式系统中常见的并发控制模式:当一个Worker获取任务时,不是永久锁定它,而是设置一个有时效的租约(例如30秒)。如果Worker在租约到期前完成任务,正常释放锁;如果Worker崩溃或超时,租约自动过期,其他Worker可以重新获取该任务。这种机制避免了死锁问题,在Redis分布式锁(如Redlock算法)和Kubernetes的Leader Election中都有广泛应用。GPT-5 Mini使用时间戳通过locked_until字段实现锁定,还运用了事务和指数退避策略——即当操作失败时,按指数级增长的时间间隔(如1秒、2秒、4秒、8秒)进行重试,以避免在高并发场景下形成"重试风暴",进一步加剧系统负载。
这才是真正的工程逻辑。如果你要将代码正式部署到生产环境,这正是该有的做法。虽然它在工具调用上出现了一些小问题,但从失败中自动恢复了。GPT-5 Mini的策略很明确:正确性优先,不讲究花哨,只求功能正常、不会崩溃。

GLM-4.6:软件架构师思维
GLM-4.6在代码结构方面表现得非常突出——多文件架构、完整的类型系统、枚举和优先队列,甚至手写了UUID生成函数而非使用现成库。这种做法有点"用力过猛",但也说明它擅长处理底层编码任务。
然而,GLM的经典问题再次出现:推理模式导致工具调用失效。 这反映了当前大语言模型架构中的一个普遍张力。推理模式通常启用了Chain-of-Thought(思维链)机制,模型会在生成最终答案前进行多步内部推理。然而,这种推理过程会改变模型的输出格式和Token分布,可能导致结构化输出(如工具调用所需的JSON格式)被打断或格式错误。部分模型在训练时,推理能力和工具调用能力是在不同阶段或不同数据集上优化的,两者之间存在一定的"能力竞争"。OpenAI和Anthropic在最新模型中已经在努力解决这一问题,但对于许多模型来说,推理深度和工具调用稳定性之间的平衡仍然是一个活跃的研究方向。
评测团队不得不禁用推理模式才能让GLM-4.6正常运行,但速度也因此变慢。更关键的是,它在内存中追踪活跃任务——这意味着应用程序一旦崩溃,所有状态都会丢失。
用一句话概括:代码在仓库里看着整洁,运行时却让你吃尽苦头。
Haiku 4.5:用户体验设计师思维
Claude Haiku 4.5是速度之王,仅用3分钟就完成了任务,还额外添加了统计功能、任务清理和索引优化。这很符合Claude一贯的风格——注重开发者体验,提供贴心的附加功能。
工具调用方面,Haiku表现完美,零失败。Claude在文件编辑的精准度上一直是顶尖水平。但致命缺陷是:没有并发控制,没有锁定,没有事务,没有任何安全保障。 代码能跑,但绝不能在生产环境中通过API调用。
此外,评测还发现Haiku有时会陷入循环——如果任务中途挂起,它可能会进入重复操作的死循环。
工具调用能力:被忽视的关键维度
这次评测最有价值的部分之一,是对工具调用能力的专项测试。在AI编程助手的语境中,工具调用(Tool Use / Function Calling)是指模型不仅生成文本形式的代码,还能直接操作开发环境——创建文件、编辑特定代码行、执行终端命令、读取项目结构等。这需要模型输出结构化的JSON指令,由宿主应用(如IDE插件)解析并执行。工具调用的可靠性直接决定了AI编程助手的实用性:如果模型生成了正确的代码但无法准确地写入目标文件,或者在多步操作中丢失上下文导致文件编辑错乱,那么开发者仍然需要大量手动干预。
工具调用通常是AI编程助手最先出问题的环节,也是区分"能聊代码"和"能写代码"的关键分水岭。
结果很清晰:
- Haiku 4.5:工具调用零失败,表现完美。这意味着开发者可以信任模型的每一步文件操作,而不需要反复检查和修正。
- GPT-5 Mini:重试后恢复正常,可以接受
- GLM-4.6:推理模式下工具调用直接失效,必须禁用推理模式
对于开发者来说,重要的不是模型自称能做什么,而是实际运行后它能真正构建出什么。
AI编程模型选型建议
评测文章给出了一个精妙的类比,完美概括了三款模型的思维模式:
GPT-5 Mini是系统工程师,GLM-4.6是软件架构师,Haiku 4.5是用户体验设计师。
基于这次实测结果,不同场景下的选型建议如下:
- 生产部署、涉及数据安全的项目 → GPT-5 Mini。它是唯一具备生产级并发安全保障的模型,总成本也最低。对于需要处理并发写入、事务完整性和故障恢复的后端服务,GPT-5 Mini的系统工程师思维能有效降低线上事故风险。
- 快速原型开发或演示 → Haiku 4.5。速度无与伦比,附加功能贴心,工具调用稳定,非常适合快速验证想法。在Hackathon、产品Demo或内部概念验证等场景中,3分钟完成一个功能完整的任务队列系统,这种效率优势是压倒性的。
- 注重代码结构和架构设计 → GLM-4.6。代码组织赏心悦目,但要注意禁用推理模式,且不建议用于需要高可靠性的场景。适合用于生成项目脚手架、设计模块接口或作为代码审查的参考。
结语
这次评测的价值在于,它不是用简单的Benchmark分数来排名,而是通过一个真实的工程任务,暴露出每款AI编程模型在实际开发中的优势和短板。对于开发者来说,选择编程模型从来不是"谁最强"的问题,而是"谁最适合我当前的场景"。
值得注意的是,这三款模型的表现差异也折射出各家AI公司不同的训练优先级和产品定位。Anthropic在工具调用的精准度上投入了大量优化,OpenAI在系统级推理和安全性方面持续深耕,而智谱则在代码结构化和架构设计能力上展现了独特优势。随着这些模型的快速迭代,当前的短板很可能在下一个版本中得到显著改善。
期待未来能看到更多类似的实战评测,尤其是在API开发、前端构建等更复杂场景下的对比——在那些场景中,模型之间的权衡取舍才真正关键。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。