Harness Engineering:从提示词到驾驭工程的AI开发实战指南

AI开发范式从提示词工程演进到驾驭工程,通过三层架构系统性约束AI Agent。
文章介绍了AI工程范式的三次跃迁:从提示词工程到上下文工程,再到驾驭工程(Harness Engineering)。驾驭工程通过信息层(让Agent理解项目)、约束层(限制Agent行为边界)和自动化层(自我验证与纠错)三层架构,系统性解决AI Agent在开发中方向偏移、上下文丢失、错误累积等常见失败问题,实现AI生产力与代码质量的平衡。
从提示词工程到驾驭工程:AI开发范式的三次跃迁
在AI大模型快速发展的今天,工程化实践的方法论也在不断演进。最近,一个名为**Harness Engineering(驾驭工程)**的概念正在开发者社区中引起广泛关注。它代表着AI工程范式从"提示词工程"到"上下文工程"再到"驾驭工程"的第三次重要跃迁。
简单回顾这三个阶段:
- 提示词工程(Prompt Engineering):通过精心设计提示词来引导模型输出,是最基础的AI交互方式
- 上下文工程(Context Engineering):在提示词基础上,系统性地管理上下文信息,让模型获得更丰富的背景知识
- 驾驭工程(Harness Engineering):构建完整的约束、验证和自动化体系,让AI Agent在可控范围内高效工作
这一演进路径反映了行业对AI工程化的认知深化——我们不仅需要让AI"能做事",更需要让它"做对事"并且"不出错"。
技术背景:提示词工程的兴起与局限
提示词工程兴起于2020年GPT-3发布之后。研究者发现,同样的模型在不同提示词下表现差异巨大,由此催生了一门专门研究如何"与AI对话"的学科。早期的经典技巧包括少样本学习(Few-shot Learning)、思维链提示(Chain-of-Thought, CoT)以及角色扮演设定等。然而随着任务复杂度上升,单纯依赖提示词的局限性日益凸显——它本质上是一种"一次性"的输入优化,缺乏对整个交互过程的系统性管理,这正是上下文工程和驾驭工程相继出现的根本动因。
技术背景:上下文工程的核心机制
上下文工程是对提示词工程的系统性升级。大语言模型的核心工作机制是基于上下文窗口(Context Window)进行预测,GPT-4支持128K tokens,Claude 3系列甚至达到200K tokens。上下文工程的核心任务是在有限的上下文窗口内,最大化信息密度和相关性。具体技术手段包括:RAG(检索增强生成)动态注入相关文档、记忆压缩(Memory Compression)保留关键历史信息,以及结构化的系统提示(System Prompt)设计。这一阶段标志着AI应用从"单次对话"走向"持续任务执行"。
Harness Engineering的核心理念
为什么需要Harness Engineering?
当前使用AI Agent进行开发时,一个普遍的痛点是:Agent在生成代码的过程中容易"跑偏"。它可能生成你完全不需要的内容,或者在方向上产生严重偏差。这不是模型能力不足的问题,而是缺乏系统性的工程化约束。
Harness Engineering正是为解决这一问题而生。它的核心思想是:通过构建一套完整的"驾驭"体系,让AI Agent在明确的边界内工作,同时具备自我验证和纠错能力。
Agent常见的失败模式
在深入Harness Engineering的具体实践之前,有必要先理解Agent为什么会失败。
技术背景:AI Agent的架构与复合误差问题
AI Agent是指能够自主规划、执行多步骤任务并与外部环境交互的AI系统。其技术架构通常包含四个核心组件:感知模块(接收输入信息)、规划模块(基于LLM进行任务分解)、记忆模块(短期工作记忆与长期知识存储)以及行动模块(调用工具、执行代码、访问API等)。ReAct(Reasoning + Acting)框架是目前最主流的Agent实现范式,由Google在2022年提出。Agent的"方向偏移"问题在技术层面源于LLM的自回归生成特性——每一步输出都依赖前序输出,误差会随步骤数指数级累积,这在学术界被称为"复合误差问题"(Compounding Error Problem),也是Harness Engineering三层架构着力解决的核心挑战。
常见的失败模式包括:
- 方向偏移:Agent在执行任务过程中逐渐偏离预期目标
- 上下文丢失:在长对话或复杂任务中,Agent遗忘关键约束条件
- 过度生成:产出大量不必要的代码或内容,增加维护成本
- 错误累积:前序步骤的小错误在后续步骤中被放大
这些失败模式在实际项目中极为常见,也是很多开发者对AI编程工具"又爱又恨"的根本原因。
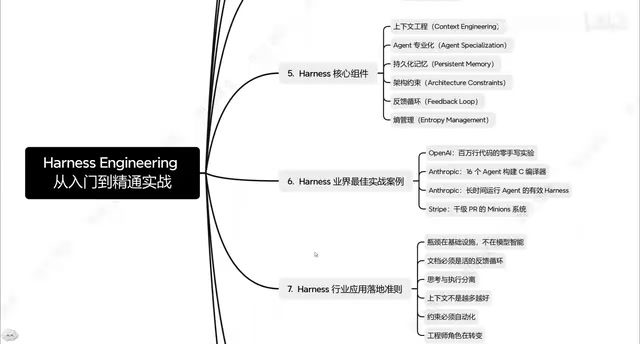
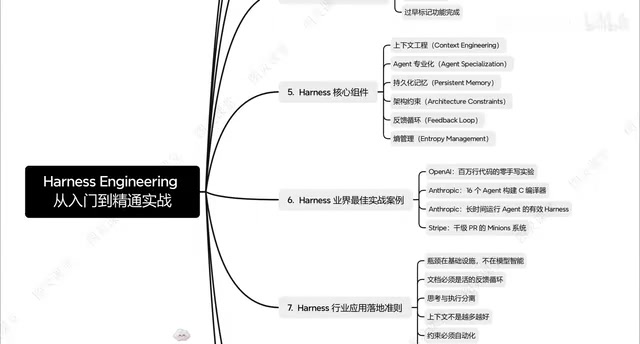
Harness Engineering的三层架构
根据体系化的梳理,Harness Engineering的实施可以分为三个关键层次。这套三层架构是其最具实践价值的框架设计。
信息层:让Agent"看懂"项目
第一层是信息层(Information Layer),核心目标是让Agent充分理解项目的全貌。这不仅仅是把代码丢给AI,而是系统性地提供项目架构、技术栈、业务逻辑、编码规范等关键信息。
信息层的构建质量直接决定了后续开发的效率和准确性。一个好的信息层应该包含:
- 项目整体架构文档
- 技术选型说明和约束条件
- 已有代码的结构和依赖关系
- 业务领域的核心概念定义
约束层:让Agent"不犯错"
第二层是约束层(Constraint Layer),这是Harness Engineering区别于传统AI编程方式的关键所在。约束层通过明确的规则和边界,限制Agent的行为范围,防止它在生成过程中"跑偏"。
技术背景:约束层与防御性编程的渊源
Harness Engineering的约束层理念与传统软件工程中的"防御性编程"(Defensive Programming)高度契合。防御性编程的核心思想是假设任何输入都可能是错误的,并在代码中预先处理各种异常情况。在AI Agent语境下,约束层扮演的角色类似于类型系统(Type System)和契约式设计(Design by Contract)——前者在编译期阻止非法操作,后者通过前置条件、后置条件和不变量来规范函数行为。
.cursorrules、CLAUDE.md等规则文件本质上是将这些约束以自然语言形式编码,让AI在执行前"内化"边界条件,而非事后纠错,从根源上降低了复合误差的发生概率。
约束层的设计需要回答几个核心问题:
- Agent可以修改哪些文件,不能动哪些文件?
- 代码风格和架构模式有什么强制要求?
- 哪些操作需要人工确认才能执行?
- 出现不确定性时,Agent应该如何处理?
这一层的本质是在AI的自由度和可控性之间找到最佳平衡点。约束太松,Agent容易失控;约束太紧,又会限制AI的创造力和效率。
自动化层:让Agent"自我验证"
第三层是自动化层(Automation Layer),负责在开发完成后自动验证代码质量,发现问题并进行修正。这一层将传统软件工程中的CI/CD理念与AI Agent的能力相结合,形成完整的质量闭环。
技术背景:CI/CD与AI自动化验证的深度融合
传统CI/CD流水线(如GitHub Actions、Jenkins、GitLab CI)负责代码构建、测试和部署的自动化。在Harness Engineering框架中,AI Agent被嵌入这一流水线,承担更智能的角色:不仅执行预定义的测试脚本,还能分析测试失败的根因、生成修复建议甚至自动提交修复PR。这与"AIOps"(AI for IT Operations)的理念一脉相承。值得一提的是,Harness本身也是一家知名的DevOps平台公司,其产品专注于软件交付自动化——这一命名的巧合折射出Harness Engineering与工程化交付体系之间深刻的概念关联。
自动化层通常包括:
- 自动化测试执行和结果分析
- 代码质量检查和规范验证
- 错误检测和自动修复建议
- 回归测试和影响范围评估
业界最佳实践:从OpenAI到Anthropic
值得关注的是,Harness Engineering的理念并非空中楼阁。OpenAI和Anthropic等头部AI公司已经在内部实践中广泛应用了类似的工程化方法。
技术背景:头部AI公司的工程化实践细节
Anthropic提出的"宪法AI"(Constitutional AI, CAI)方法论要求模型在生成内容时遵循一套明确的原则体系,这与约束层的设计思想高度一致。OpenAI则在其Codex和GPT-4 Code Interpreter的内部实践中大量使用沙箱隔离(Sandbox Isolation)和权限最小化原则,确保代码执行不会产生意外的副作用。此外,Anthropic发布的"Model Spec"文档详细规定了Claude在面对不确定性时的行为准则,这与Harness Engineering中"出现不确定性时Agent应如何处理"的约束层设计形成了直接呼应——两者都强调显式规则优于隐式期望,将可控性作为系统设计的第一优先级。
这些最佳实践的核心思想可以提炼为几条关键准则:
- 渐进式信任:从小任务开始,逐步扩大Agent的权限范围
- 显式约束优于隐式期望:所有规则都应该明确写出,而非依赖Agent的"常识"
- 验证驱动开发:每一步操作都应有对应的验证机制
- 人机协作而非人机替代:Agent是增强开发者能力的工具,而非替代品
AI编程工具的选择策略
在Harness Engineering的不同阶段,需要选择合适的AI编程工具。目前主流的工具各有侧重:
- 信息层构建阶段:适合使用能够深度理解代码库的工具,如Cursor、Windsurf等IDE集成方案
- 约束层设计阶段:需要支持规则文件(如
.cursorrules、CLAUDE.md等)的工具 - 自动化验证阶段:可以结合传统CI/CD工具与AI Agent的自动修复能力
关键不在于选择"最好的"工具,而在于在正确的阶段使用正确的工具。
实战落地的关键清单
将Harness Engineering真正落地到项目中,需要关注以下核心事项:
- 项目文档准备:完整的架构文档、技术规范、业务说明
- 约束规则定义:明确的编码规范、文件权限、操作边界
- 验证机制搭建:自动化测试、代码审查、质量门禁
- 迭代优化流程:根据实际效果持续调整约束和信息层
- 团队协作规范:统一的Harness配置管理和版本控制
总结与展望
Harness Engineering代表了AI工程化实践的一个重要方向。它的核心价值不在于某个具体的工具或技术,而在于提供了一套系统性的方法论,帮助开发者在享受AI生产力红利的同时,保持对代码质量和项目方向的控制。
随着AI模型能力的持续提升,Harness Engineering的重要性只会越来越高。因为模型越强大,"驾驭"它的工程化能力就越关键——这就像一匹更快的马,需要更好的缰绳和更熟练的骑手。从提示词工程到上下文工程,再到驾驭工程,每一次范式跃迁的背后,都是开发者群体对"如何与AI协作"这一核心命题认知的集体深化。
对于希望在AI时代保持竞争力的开发者来说,掌握Harness Engineering不仅是一项技术技能,更是一种工程思维的升级。
核心要点
- AI工程范式经历了从提示词工程到上下文工程再到驾驭工程(Harness Engineering)的三次演进,每次跃迁都对应着开发者对AI系统性管理能力的更高要求
- Harness Engineering通过信息层、约束层、自动化层三层架构解决Agent开发中的常见失败问题,其理论根基与防御性编程、契约式设计等经典软件工程思想一脉相承
- 约束层是Harness Engineering的核心差异化所在,通过明确规则防止Agent在代码生成中跑偏,本质上是将类型系统和编译期检查的思想迁移到AI行为管理领域
- OpenAI和Anthropic等头部公司已在内部实践中应用类似的工程化方法(如宪法AI、Model Spec、沙箱隔离),验证了该范式的可行性
- 不同开发阶段应选择不同的AI编程工具,关键在于正确阶段使用正确工具,而非追求单一"最优解"
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。