Harness:一句话生成多Agent协作团队的开源框架
当你的AI Agent从「单兵作战」进入「团队协作」阶段,最头疼的问题是什么?不是写提示词,而是设计谁该干什么、谁先谁后、怎么配合。Harness 这个 4.6K 星的开源项目,正是要解决这个问题。
什么是 Harness:Agent 团队的自动化工厂
Harness 的定位很清晰——它不是又一个聊天助手,也不是提示词模板合集,而是一个Agent 团队生成器。
你只需要用一句话描述项目目标,它就能自动拆解出一个完整的多角色协作团队。举两个例子:
- 做一个网站:自动拆分出设计师、前端开发、后端开发、测试工程师等角色
- 做内容生产:自动拆分出选题策划、脚本撰写、标题优化、封面设计、内容审核等角色
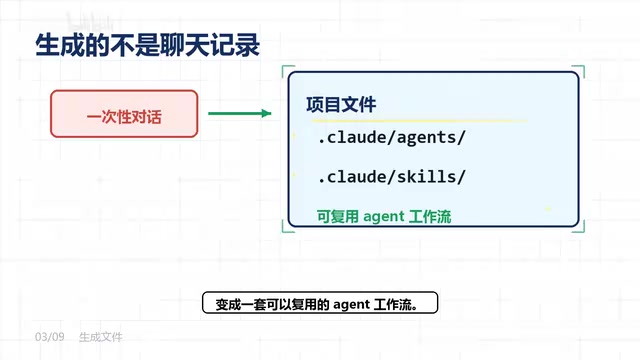
关键在于,生成的不是一次性的聊天记录,而是项目中可复用的 agent 文件和 skills 文件。在Agent开发实践中,「agent文件」通常指定义了Agent角色、系统提示词、可用工具和行为约束的配置文件(通常为YAML或JSON格式),而「skills文件」则封装了Agent的具体能力实现,包括工具调用逻辑、输出格式规范和错误处理策略。这种将Agent能力「文件化」的做法,本质上是软件工程中「基础设施即代码」(Infrastructure as Code)理念在AI领域的延伸——它解决了一个关键痛点:大多数人使用Agent时的成果是一次性的对话记录,无法复用、无法版本控制、无法团队共享。
在DevOps领域,IaC通过Terraform、Ansible等工具将服务器配置、网络拓扑等基础设施定义为可版本控制的代码文件,彻底改变了运维方式。Agent文件化遵循同样的逻辑:当Agent的角色定义、技能配置和协作规则都以声明式文件存在时,团队可以通过Pull Request来审查Agent行为变更,通过分支策略来实验不同的协作方案,通过CI/CD流水线来自动化部署Agent团队。这种工程化实践还解决了「提示词漂移」问题——在纯对话模式下,Agent的行为会随着上下文积累而逐渐偏离预期,而文件化的配置提供了确定性的行为锚点。
值得进一步指出的是,IaC的核心价值不仅是版本控制,更重要的是实现了「幂等性」——即同一份配置文件无论执行多少次,都能产生完全相同的结果。在Agent领域,这意味着通过声明式配置文件定义的Agent团队,可以在不同环境中被精确复现。此外,IaC生态中成熟的实践如「漂移检测」(Drift Detection)也可以被借鉴到Agent管理中——定期检查运行中的Agent行为是否偏离了配置文件中的定义,这对于长期运行的多Agent系统尤为重要,因为模型更新、API变更或上下文污染都可能导致Agent行为的隐性漂移。
换句话说,它把临时的需求固化成了一套可持续运行的工作流。
多Agent协作的行业背景
Multi-Agent系统(MAS)是分布式人工智能领域的核心研究方向,其理论基础可追溯到20世纪80年代的分布式问题求解研究。在LLM时代,Multi-Agent的含义发生了本质变化:从传统的基于规则的软件代理,演变为由大语言模型驱动的智能体协作。当前主流框架如AutoGen、CrewAI、LangGraph等都在尝试解决同一个核心问题——如何让多个LLM Agent高效协作而不产生信息熵增。
这里的「信息熵增」是多Agent系统中最被低估的技术挑战之一。在信息论中,熵衡量的是系统的不确定性程度。当多个Agent进行信息传递时,每一次转述都可能引入噪声、丢失上下文或产生歧义——这与组织管理中的「传话效应」如出一辙。在技术层面,这表现为:Agent A生成的结构化输出被Agent B解析时丢失了隐含语义;多轮协作中累积的上下文超出了单个Agent的处理窗口;不同Agent对同一术语的理解存在微妙差异导致决策偏差。解决这一问题的常见策略包括:定义严格的消息schema、引入共享知识库作为「单一事实来源」、以及设置检查点机制来定期校准各Agent的状态一致性。
这里的难点不在于单个Agent的能力,而在于协调机制的设计:包括任务分解策略、通信协议、冲突解决机制和结果聚合方式。Harness 在这个赛道中的独特定位是:它不要求用户理解这些底层机制,而是通过自动化生成来降低多Agent系统的设计门槛。
六种预设团队架构详解
Harness 内置了六种经过验证的团队协作模式,覆盖了绝大多数实际场景:
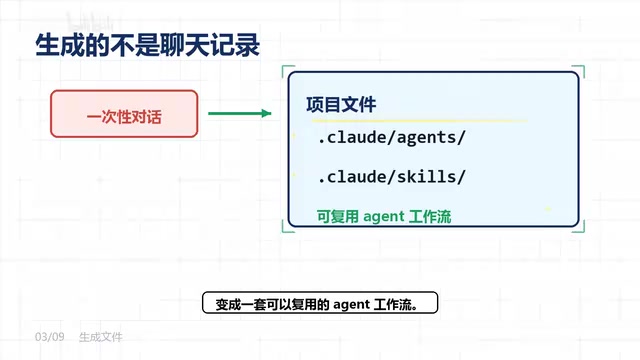
- 流水线模式:适合有明确先后顺序的任务,A做完传给B,B做完传给C
- 并行汇总模式:多个Agent同时处理不同子任务,最后统一汇总结果
- 专家路由模式:根据问题类型自动调用对应领域的专家Agent
- 生产-审核模式:一个Agent负责生产内容,另一个负责质量审核
- 主管调度模式:由一个主管Agent统筹分配任务给下属Agent
- 分层委派模式:多级管理结构,适合大型复杂项目
这六种架构并非Harness的发明,而是对组织管理学和软件架构设计中经典模式的AI化映射。流水线模式对应制造业的装配线和软件开发中的Pipeline模式;并行汇总模式类似MapReduce的计算范式——先将大任务拆分到多个节点并行处理,再将结果归约合并;专家路由模式本质上是设计模式中的策略模式(Strategy Pattern)在Agent层面的应用;生产-审核模式源自软件工程中的Code Review文化和出版行业的编辑-校对流程;主管调度模式对应管理学中的集中式决策结构;分层委派模式则映射了大型企业的科层制组织架构。
并行汇总模式与MapReduce的深层对应
并行汇总模式与MapReduce的类比值得深入展开。MapReduce由Google在2004年的论文中正式提出,其核心思想是将大规模数据处理拆分为Map(映射)和Reduce(归约)两个阶段,这一范式后来成为Hadoop等大数据框架的理论基石。在Agent场景中,Map阶段对应多个Agent并行处理各自的子任务——例如在市场调研项目中,一个Agent分析竞品定价,另一个分析用户评论,第三个分析行业趋势;Reduce阶段对应汇总Agent对多个结果的整合。但Agent场景比传统MapReduce更复杂,因为Agent的输出是非结构化的自然语言,汇总时需要处理语义层面的冲突和冗余,而非简单的数值聚合。当两个Agent对同一市场趋势给出相反判断时,汇总Agent需要评估各自的论据质量和数据来源可靠性,这要求汇总Agent具备超越简单合并的元认知推理能力。
专家路由模式的策略模式实现
专家路由模式中涉及的策略模式(Strategy Pattern)是GoF(Gang of Four)设计模式中的经典行为型模式。在传统软件中,策略模式通过定义一系列算法并将它们封装在独立的类中,使得算法可以在运行时互换而不影响调用方。在Agent路由场景中,每个「专家Agent」就是一个策略实现,而路由器Agent充当Context角色,根据输入问题的语义特征选择最合适的专家。路由决策的质量直接决定了整个系统的表现——如果一个法律问题被错误路由到了技术专家Agent,不仅浪费计算资源,还可能产生误导性的输出。常见的路由实现方式包括:基于关键词匹配的规则路由(简单但脆弱)、基于嵌入向量相似度的语义路由(更鲁棒但需要维护向量索引),以及让路由器Agent自身通过推理来判断的LLM路由(最灵活但增加了延迟和成本)。
在技术实现层面,这些模式各有不同的通信和状态管理机制。流水线模式需要定义明确的数据传递接口,每个Agent的输出必须符合下游Agent的输入schema;并行汇总模式面临的核心挑战是结果合并时的冲突消解——当多个Agent对同一问题给出矛盾结论时,汇总Agent需要具备元认知能力来判断哪个结论更可靠;专家路由模式的关键在于路由器Agent的分类准确性,这通常依赖于对问题的语义理解和领域边界的清晰定义;生产-审核模式需要设计反馈循环机制,审核Agent不仅要指出问题,还要提供可操作的修改建议,避免陷入无限修改循环。理解这些实现细节,有助于在实际部署时预判和规避常见的系统性问题。
理解这些底层映射关系,有助于在实际项目中选择最合适的协作模式,而不是盲目套用。
核心价值:从单人助手到团队编排
传统使用Agent的方式是:你自己想好该让哪个Agent干什么,手动编排流程。这在简单任务中没问题,但当任务变复杂,问题就来了——
- 角色拆分不合理导致重复劳动
- 协作顺序设计不当导致信息断层
- 每次新项目都要从头设计流程
Harness 的做法是把「团队设计」这件事本身也交给AI来做。你负责描述目标,它负责设计最优的团队结构和协作方式。这背后的逻辑是:如果AI已经足够理解任务的结构和依赖关系,那么它也应该能够设计出合理的分工方案——就像一个经验丰富的项目经理,看到需求后就能快速组建团队并分配职责。
这种思路特别适合三类场景:
- 开发项目:需要多角色分工的软件工程
- 内容项目:从策划到发布的完整内容流水线
- 复杂研究:需要多视角分析的调研任务
使用限制与适用边界

需要明确的是,Harness 目前官方重点支持的是 Claude Code 环境。Claude Code是Anthropic推出的命令行AI编程工具,它允许开发者在终端环境中直接与Claude模型交互,执行代码编写、文件操作、系统命令等任务。与传统IDE插件不同,Claude Code采用了「agentic coding」的范式——AI不仅生成代码片段,还能自主规划执行步骤、读取项目上下文、运行测试并迭代修复。
Claude Code所代表的Agentic Coding范式是AI辅助编程的第三次范式跃迁。第一代是代码补全(如GitHub Copilot早期版本),AI在光标位置预测下一行代码,本质上是一个高级的自动补全引擎,其能力边界局限于当前文件的局部上下文;第二代是对话式编程(如ChatGPT),开发者通过自然语言描述需求获取代码片段,AI的视野扩展到了对话历史,但仍然缺乏对项目整体结构的感知;第三代即Agentic Coding,AI具备了自主规划和执行的能力——它可以读取整个项目结构、理解文件间的依赖关系、自主决定修改哪些文件、运行测试验证结果、并根据错误信息迭代修复。这种范式下,AI从「工具」升级为「协作者」,而Harness在此基础上更进一步,将单个AI协作者扩展为一个AI协作团队,每个团队成员通过文件系统中的配置文件获得专属的角色定义和能力边界。这三代范式的演进,本质上是AI在编程场景中「自主性」(Agency)的逐步释放——从被动响应到主动规划,从单点操作到全局协调。
Harness选择Claude Code作为首要支持环境,是因为Claude Code原生支持通过项目目录中的配置文件(如.claude/目录下的文件)来定义Agent行为,这为多Agent协作提供了天然的文件系统级集成点。生成的agent和skills文件可以直接被Claude Code识别和执行,无需额外的运行时环境。
如果你使用其他开发环境,它的架构思路可以借鉴,但无法直接作为通用插件使用。
另外,并非所有任务都需要团队编排。当任务足够简单时(比如翻译一段文字、总结一篇文章),单个Agent就能高效完成,引入团队架构反而增加了不必要的复杂度。这在系统设计中被称为「过度工程化」(Over-engineering)——解决方案的复杂度超过了问题本身的复杂度,反而降低了效率。
适合使用 Harness 的判断标准:
- 任务涉及3个以上不同职能的角色
- 流程需要反复执行而非一次性完成
- 任务链条较长,存在明确的上下游关系
总结
Harness 代表了 Agent 应用的一个重要演进方向:从「怎么用好一个Agent」到「怎么组织一群Agent协作」。它把组织管理学中的团队设计理论,转化成了可执行的AI工作流框架。
这个方向的意义在于,随着单个Agent的能力逐渐趋近天花板(受限于上下文窗口、推理深度和工具调用的可靠性),通过多Agent协作来突破单体能力边界,正在成为提升AI系统整体表现的关键路径。关于上下文窗口的限制,值得补充的是:当前主流LLM的上下文窗口虽然已从最初的4K token扩展到128K甚至更长,但在处理大型项目时仍然捉襟见肘。更关键的是,即使窗口足够大,研究表明LLM在超长上下文中存在「中间遗忘」(Lost in the Middle)现象——模型对上下文中间部分的信息关注度显著低于首尾部分,这意味着简单地堆叠上下文长度并不能线性提升Agent的任务处理能力。多Agent架构通过让每个Agent只关注自己职责范围内的上下文,天然地规避了这一问题——每个Agent维护一个精简的、与其角色高度相关的上下文窗口,而非试图将所有信息塞进一个巨大的提示词中。
对于正在深入探索Agent开发的人来说,即使不直接使用这个工具,其背后的多Agent协作架构思维也值得认真研究。
相关推荐

AI零代码复刻《杀戮尖塔》:从架构到美术的完整实践
B站UP主使用Godot引擎和AI工具链,全程零代码复刻经典卡牌肉鸽游戏《杀戮尖塔》。详解架构文档先行、AI迭代编程、美术素材批量生成的完整工作流,项目已开源。
Claude一句话生成10款网页游戏:零代码AI编程实战
用Claude Code一句自然语言提示词生成2048、五子棋、俄罗斯方块等10款网页游戏,全程零代码开发并部署上线。详解AI编程实战流程、工具选择与核心认知转变。

克隆成功App月入3.5万美元:独立开发者验证式创业方法论
前验光师零基础自学编程,通过克隆已验证的成功应用,运营三款产品月入3.5万美元。详解他的四步筛选法、数据驱动验证流程和递进式获客策略。