Headroom:AI Agent Token成本降低10倍的开源压缩工具

当你使用 Claude Code、Codex 等 AI 编程工具时,是否注意过每次工具调用都在疯狂消耗 token?一个简单的日志文件读取可能就吞掉上万个 token,而其中大部分是噪音。Netflix 高级工程师 Tejas Chopra 开源了一个名为 Headroom 的工具,通过在 LLM 读取内容之前进行智能压缩,实现 60%-95% 的 token 节省,同时保证输出质量不变。
Headroom 解决了什么问题?
如果你用过 Claude Code 这类 AI 编程助手,你一定知道它有多"烧钱"。每一次工具调用都可能返回大量 JSON 日志,其中绝大部分是噪音,真正有价值的信息可能只占很小一部分。而这些内容全部会被塞进上下文窗口——这正是你付费的部分。
要理解这个问题的严重性,需要了解 Token 经济学的基本逻辑。Token 是大语言模型计费的基本单位,以 Claude 3.5 Sonnet 为例,输入 token 价格为每百万 token 3 美元,输出为 15 美元;而 Opus 模型则分别高达 15 美元和 75 美元。一个典型的 JSON 日志文件可能包含数千行重复结构,每行都会被分词器拆解为多个 token。当 AI 编程工具在一次会话中进行数十次工具调用时,累积的 token 消耗可以轻松达到数十万甚至上百万,单次会话成本可能超过 10 美元。
尤其是当你使用 Opus 模型的 UltraCode 模式时,它会动态创建并行子 Agent,没有 token 上限,成本可以迅速失控。UltraCode 是 Claude Code 的一种高级运行模式,它允许主 Agent 动态创建多个并行子 Agent 来同时处理不同的子任务。例如,在重构一个大型项目时,主 Agent 可能同时派出一个子 Agent 分析依赖关系、另一个修改测试文件、第三个更新文档。每个子 Agent 都有独立的上下文窗口和工具调用权限,这意味着 token 消耗是乘数级增长的。没有 token 上限的设计虽然提升了任务完成质量,但也让成本变得不可预测。
Headroom 的核心思路很简单:在内容到达 LLM 之前,先把它压缩掉。
Headroom 的工作原理
智能内容检测与分类压缩策略
Headroom 并不是简单地截断文本,而是根据内容类型采用不同的压缩策略:
- JSON 数组:保留异常值和边界情况,丢弃重复的正常数据
- 代码文件:通过解析实际的语法树(AST)进行代码感知压缩
- 构建日志:只保留失败信息,丢弃通过的测试结果
- 纯文本:使用自训练的本地模型 CompressBase 进行语义压缩
这种分类压缩的设计非常聪明——它理解不同类型内容的"信息密度分布",精准地保留高价值信息。
其中,代码文件的 AST 压缩尤其值得深入理解。AST(抽象语法树)是编译器前端将源代码转换为树状数据结构的中间表示。通过解析 AST,Headroom 能够理解代码的语法结构——区分函数签名、注释、实现细节和导入语句。这意味着它可以智能地保留函数签名和关键逻辑,同时省略冗长的实现体或重复的样板代码。相比简单的行数截断,AST 感知压缩能保证语义完整性,不会在函数中间断开或丢失关键的类型信息。
可逆压缩:面包屑机制实现无损回退
Headroom 最巧妙的设计在于可逆性。每次压缩后,它会在压缩文本中留下一个"面包屑"——包含一个哈希值的标记。当模型发现压缩后的信息不够用时,可以通过这个哈希值请求获取完整的原始数据。
这个面包屑机制借鉴了分布式系统中的内容寻址存储思想。每次压缩时,Headroom 会计算原始内容的哈希值(类似 Git 的 SHA 机制),将完整数据存储在本地缓存中,并在压缩输出中嵌入一个形如 [HEADROOM:abc123] 的标记。当 LLM 在推理过程中判断需要更多细节时,它可以在输出中引用这个标记,代理服务器会拦截这个请求并返回完整的原始数据。这种设计将压缩从不可逆操作变为了按需可逆操作,在信息保全和 token 节省之间取得了动态平衡。

架构设计:代理服务器模式无需改代码
Headroom 以 Python 代理服务器的形式运行,位于你的应用(如 Claude Code)和 API 服务器(如 Anthropic)之间。当工具调用结果返回时,代理会使用底层的 Rust 引擎进行压缩,然后将压缩版本发送给 API。这意味着你不需要修改现有代码的核心逻辑,只需要把请求指向 Headroom 代理即可。
代理服务器(Proxy Server)是一种经典的中间件架构模式,它拦截客户端与服务端之间的通信流量进行处理。在 Headroom 的场景中,它作为透明代理工作:客户端(如 Claude Code)将 API 请求发送到本地代理端口,代理转发请求到 Anthropic API,收到响应后对工具调用结果进行压缩,再返回给客户端。这种架构的优势在于零侵入性——不需要修改 AI 工具的源码或 API 调用逻辑,只需更改环境变量中的 API 端点地址即可。Rust 引擎的选择则是为了在压缩处理环节获得接近零延迟的性能表现,确保代理层不会成为响应速度的瓶颈。
实际效果:Token 节省数据
日志分析场景:98% 的 Token 节省
在一个读取服务器日志并分析错误根因的测试中,Headroom 展现了惊人的压缩效果。原始日志包含大量重复的 info 级别日志,Headroom 通过统计压缩将 419 条相似的 info 日志压缩为一行摘要,节省了超过 17,000 个 token,压缩率达到 98%。
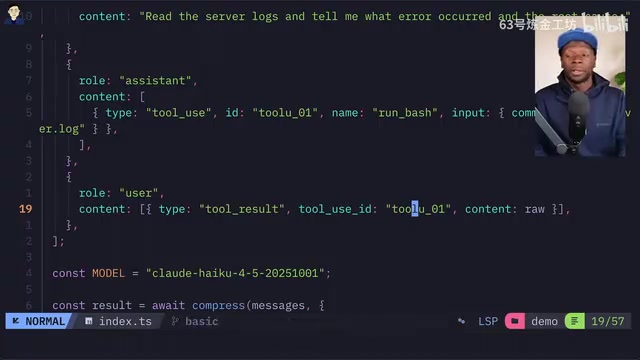
压缩后的工具响应只保留了关键的错误信息和异常模式,同时附带了用于检索完整数据的哈希标记。有意思的是,第一次运行时模型认为信息不足以完成任务,但第二次运行时就能给出完整的分析结果。
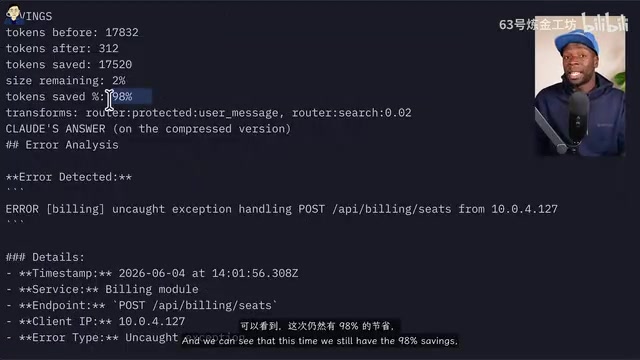
代码项目分析场景:代码感知压缩
在另一个测试中,让 Claude 读取项目中所有 TypeScript 文件并给出深度概览。启用 Headroom 的代码感知压缩器后,使用了约 89.1k token;而不使用 Headroom 的对照组使用了更多 token。通过 Headroom 的统计端点,可以清楚看到每次压缩节省了多少 token 和多少费用。
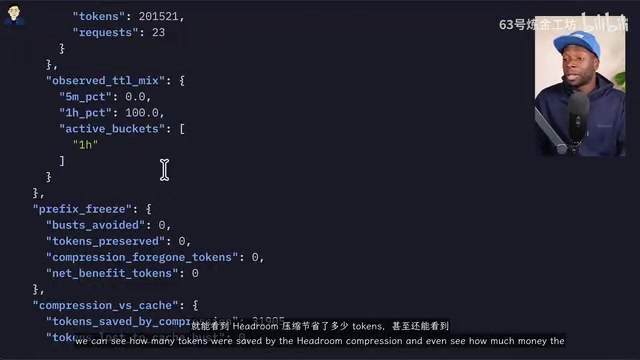
一个有趣的发现是:在低努力(low effort)模式下,Headroom 几乎没有产生 token 节省;只有在中等及以上努力级别时,节省才变得显著。这说明 Headroom 在高 token 消耗场景下价值更大。
进阶特性:不只是压缩工具
Headroom 还提供了几个值得关注的高级功能:
Cross-Agent Memory(跨 Agent 记忆共享)
允许 Claude Code、Codex 等不同的 AI 编程工具共享相同的压缩上下文。这意味着你在一个工具中已经压缩过的内容,不需要在另一个工具中重新处理。
在现代 AI 开发工作流中,开发者可能同时使用多个 AI 工具:用 Claude Code 进行代码编写,用 Codex 进行代码审查,用 Cursor 进行调试。每个工具都有独立的上下文窗口,这意味着同一份代码文件可能被重复读取和处理多次。Cross-Agent Memory 通过共享压缩缓存层解决了这个问题——当一个工具已经压缩并缓存了某个文件的内容,其他工具可以直接复用这个压缩结果,避免重复的 token 消耗。这本质上是在多个 AI Agent 之间建立了一个共享的知识层,类似于操作系统中多个进程共享同一块内存映射文件的概念。
Headroom Learn(自适应学习优化)
这是解决"压缩过度"问题的关键功能。它会挖掘你失败的会话记录,找出哪些内容被压缩得太狠导致模型无法正确回答,然后学习避免在未来犯同样的错误。这是一个持续优化的反馈循环。
从技术角度看,Headroom Learn 实现了一种离线强化学习的思路:它将每次会话的压缩决策视为"动作",将模型最终是否成功完成任务视为"奖励信号"。当某次压缩导致模型需要二次往返获取原始数据,或者直接给出了错误答案时,系统会记录这个负反馈,并调整对应内容类型的压缩阈值。随着使用时间的增长,Headroom 会越来越了解你的具体工作场景中哪些信息是不可压缩的"关键信号"。
局限性与使用权衡
二次往返的额外成本
Headroom 最大的潜在问题是:当模型发现压缩后的信息不够用,需要通过哈希值请求完整数据时,会产生额外的一次往返。在某些情况下,这反而会比不使用 Headroom 消耗更多 token。Headroom Learn 功能正是为了缓解这个问题而设计的。
具体来说,一次额外往返意味着:模型需要生成一个请求完整数据的输出(消耗输出 token),系统返回完整原始数据(消耗输入 token),然后模型需要重新处理包含完整数据的上下文(再次消耗输入 token)。在最坏情况下,总 token 消耗可能达到不使用 Headroom 时的 1.5-2 倍。因此,Headroom 的净收益高度依赖于压缩决策的准确性——这也是为什么 Headroom Learn 的自适应优化如此重要。
Headroom 与 Caveman 的互补使用
值得一提的是,Headroom 和另一个工具 Caveman 采用了完全相反的策略:
- Headroom:压缩模型的输入(工具调用结果、代码文件等)
- Caveman:压缩模型的输出(指示模型用简短片段回复,去掉填充词)
一个削减输入,一个削减输出,理论上可以同时使用以实现最大化的 token 节省。
从 token 计费的角度理解这种互补关系:输入 token 和输出 token 的价格通常相差 3-5 倍(输出更贵),因此 Caveman 压缩输出 token 的单位经济价值实际上更高。而 Headroom 压缩输入 token 的优势在于输入的体量通常远大于输出——一次工具调用可能返回数万 token 的内容,而模型的回复通常只有数百到数千 token。两者结合,可以从输入和输出两端同时降低成本。
总结:值得尝试的 AI 成本优化方案
Headroom 代表了一种务实的 AI 成本优化思路:与其等待模型价格下降或上下文窗口无限扩大,不如从工程层面解决信息冗余问题。据官方数据,Headroom 已经为用户累计节省了约 70 万美元的 token 费用。
对于重度使用 AI 编程工具的开发者和团队来说,Headroom 值得认真考虑。尤其是在多 Agent 并行、高努力级别的工作流中,它的价值会更加显著。当然,任何压缩都意味着信息损失的风险,关键在于找到压缩率和准确性之间的最佳平衡点——而这正是 Headroom Learn 试图自动化解决的问题。
从更宏观的视角来看,Headroom 所代表的"上下文工程"(Context Engineering)正在成为 AI 应用开发中的一个重要分支。随着 AI Agent 变得越来越复杂,如何高效管理有限的上下文窗口资源——决定什么信息进入窗口、以什么粒度进入、何时需要回溯获取更多细节——将成为影响 AI 应用性能和成本的关键工程决策。Headroom 提供了一个优雅的自动化方案,让开发者不必手动做这些权衡。
相关推荐

AI零代码复刻《杀戮尖塔》:从架构到美术的完整实践
B站UP主使用Godot引擎和AI工具链,全程零代码复刻经典卡牌肉鸽游戏《杀戮尖塔》。详解架构文档先行、AI迭代编程、美术素材批量生成的完整工作流,项目已开源。
Claude一句话生成10款网页游戏:零代码AI编程实战
用Claude Code一句自然语言提示词生成2048、五子棋、俄罗斯方块等10款网页游戏,全程零代码开发并部署上线。详解AI编程实战流程、工具选择与核心认知转变。

克隆成功App月入3.5万美元:独立开发者验证式创业方法论
前验光师零基础自学编程,通过克隆已验证的成功应用,运营三款产品月入3.5万美元。详解他的四步筛选法、数据驱动验证流程和递进式获客策略。