HuggingFace Transformers入门教程:模型下载、Pipeline推理到训练保存
HuggingFace Transformers核心用法系统教程
本文系统介绍了HuggingFace Transformers的核心用法,包括预训练模型的两种下载方式(Git LFS和from_pretrained)、模型存储路径配置、SafeTensors格式说明,以及Pipeline API的使用方法。Pipeline封装了分词、推理和后处理的完整流程,支持情感分析、文本生成、NER等多种NLP任务,让开发者几行代码即可完成复杂任务。
前言
HuggingFace 已经成为 AI 领域的「GitHub」,汇聚了海量的开源模型、数据集和工具。无论是 BERT、GPT 还是 DeepSeek、LLaMA,几乎所有主流模型都能在这个平台上找到。而 Transformers 库则是 HuggingFace 生态中最核心的工具包,它让模型的下载、使用和微调变得异常简单。
背景补充:HuggingFace 成立于 2016 年,最初是一家聊天机器人公司,后来转型为 AI 开源平台。截至 2024 年,平台上托管了超过 50 万个模型和 10 万个数据集,估值超过 45 亿美元。其核心价值在于标准化了模型共享的方式——每个模型仓库都包含统一格式的权重文件、配置文件和使用文档,极大降低了 AI 研究成果的复现门槛。
本文将系统梳理 HuggingFace Transformers 的核心用法,涵盖预训练模型下载、Pipeline API 使用、Tokenizer 分词器原理以及模型训练保存的完整流程,帮助你快速上手这套工具链。
模型下载:从HuggingFace获取预训练模型
两种下载方式
使用 HuggingFace 的第一步是把模型下载到本地。主要有两种方式:
- Git LFS 下载:通过 Git 大文件存储直接克隆模型仓库
- Transformers 库下载:通过 Python 代码自动下载,也是最推荐的方式
Git LFS 技术背景:Git LFS(Large File Storage)是 Git 的扩展协议,专门解决大文件版本管理问题。普通 Git 仓库不适合存储 GB 级别的模型权重文件,而 LFS 通过将大文件替换为指针文件、实际内容存储在独立服务器上的方式解决了这一问题。对于 AI 模型下载,LFS 方式更适合需要完整版本历史或离线部署的场景;而
from_pretrained()方式则更适合快速实验和按需下载。
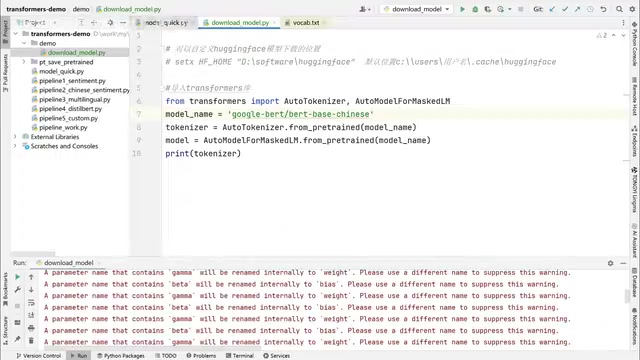
以下载 google-bert/bert-base-chinese 为例,代码非常简洁:
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_name = "google-bert/bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForMaskedLM.from_pretrained(model_name)
运行后,Transformers 会自动从 HuggingFace Hub 下载模型文件(约 412MB)及配套的分词器、配置文件等。
模型存储路径配置
默认情况下,模型会下载到 C盘用户目录/.cache/huggingface 下。建议通过设置环境变量 HF_HOME 来自定义存储路径,避免 C 盘空间不足:
export HF_HOME=/your/custom/path
下载完成后,目录结构中主要包含以下文件:
- model.safetensors:模型权重文件(核心文件,体积最大)
- config.json:模型配置文件
- vocab.txt:词汇表文件
- tokenizer_config.json:分词器配置
SafeTensors 格式说明:
model.safetensors是 HuggingFace 推出的新一代模型权重存储格式,用于替代早期的 PyTorch pickle 格式(.bin文件)。SafeTensors 的核心优势在于安全性——传统 pickle 格式在反序列化时可能执行任意代码,存在安全风险;而 SafeTensors 采用简单的头部+数据结构,不包含可执行代码。此外,SafeTensors 支持内存映射(mmap),加载速度比 pickle 格式快数倍,在多 GPU 场景下优势尤为明显。
加载模型时,既可以通过模型名称在线加载,也可以指定本地路径加载已下载的模型,from_pretrained() 方法同时支持这两种方式。
Pipeline API:开箱即用的推理工具
Pipeline 是 Transformers 提供的高层 API,封装了从分词、推理到后处理的完整流程,几行代码就能完成复杂的 NLP 任务。
Pipeline 架构原理:Pipeline API 的设计遵循「关注点分离」原则,将 NLP 任务拆解为预处理(Preprocessing)、模型推理(Model Inference)和后处理(Postprocessing)三个独立阶段。每个 Pipeline 实例在初始化时会自动加载与任务匹配的模型和分词器,并根据运行环境自动选择 CPU 或 GPU 执行。这种封装方式让用户无需关心底层张量操作,但也意味着灵活性有所降低——对于需要自定义推理逻辑的场景,直接操作模型和分词器是更好的选择。
Pipeline支持的任务类型
Pipeline 覆盖了多种常见的自然语言处理任务:
| 任务类型 | 说明 |
|---|---|
| 情感分析(Sentiment Analysis) | 判断文本正负面情感 |
| 文本生成(Text Generation) | 根据提示生成文本 |
| 命名实体识别(NER) | 识别文本中的人名、地名等实体 |
| 文本填空(Fill-Mask) | 预测被遮盖的词语 |
| 摘要生成(Summarization) | 自动生成文本摘要 |
| 翻译(Translation) | 不同语言间的翻译 |
| 特征提取(Feature Extraction) | 提取文本的向量表示 |
情感分析实战代码
以情感分析为例,Pipeline 可以判断
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。